有些人在面临问题的时候会想:“我知道,我将使用正则表达式来解决这个问题。”这让他们面临的问题变成了两个。
—— Jamie Zawinski
首先我们对比一下两段代码处理用户输入手机号的不同


1 phone_num = input('请输入手机号:') 2 if len(phone_num) == 11 3 and phone_num.isdigit() 4 and phone_num[:3] in ['130','131','132']: 5 print('hello') 6 else:print('非联通号!')
1 import re 2 phone_num = input('请输入手机号:') 3 if re.findall('^(130|131|132)[0-9]{8}$',phone_num): 4 print('hello') 5 else:print('非联通号!')
对比来看代码1比较通俗易懂,代码2看起来有些不太容易理解但是可以使得代码更加的简洁
1.正则表达式
re模块提供了对正则表达式的支持,学习re模块之前要了解正则表达式:
正则表达式其实是匹配文本片段的模式,最简单的正则表达式是普通的字符串,与自己匹配,可以使用这种匹配行为来完成一下工作:在文本中查找模式,将特定的模式替换为计算得到的值,以及将文本分割为片段。
正则表达式在线测试工具 http://tool.chinaz.com/regex/
1.1通配符
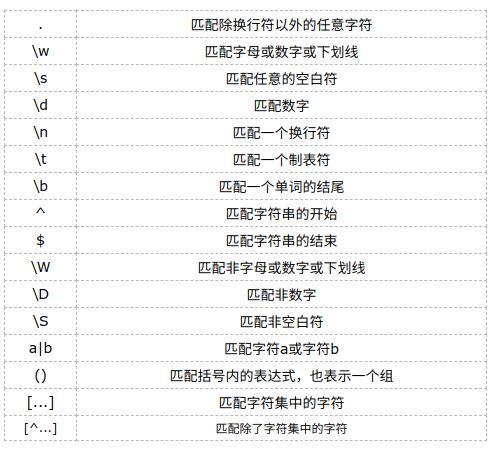
1.2字符集
用方括号将一个子串括起来,创建一个所谓的字符集
例如"[a-zA-Z0-9]"与大小写字母以及数字都匹配,但需要注意的是字符集只能匹配一个字符
要排除字符就可以在开头加上^字符,例如"[^abc]"与除a、b和c外的其他任何字符都匹配

1.3量词

1.4分组 ()与 或 |[^]
匹配身份证号为15或18位字符串组成,15位为纯数字,首位不能为零。

1.5 特殊字符进行转义
普通字符与自己匹配,但特殊字符情况不同,要让特殊字符与普通字符一样就要对其进行转义:在正则前加""
请注意,为表示模式re要求的单个反斜杠,需要在字符串中写两个反斜杠,让解释器对其转义,包含两层含义,解释器执行的转义和模块re进行的转义
当然可以使用原始字符串,如r'd'
>>> import re
>>> print(re.findall('\\d', '\d')) # 匹配字符"d"时,正则表达为"\d",然后Python还要对其中两个斜杠在进行转义,最终规则表达式为"\\d"
['\d']
>>> print(re.findall(r'\d',r'd')) # 使用原始字符串省去不必要的麻烦
['\d']
1.6 贪婪和非贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
加上"?"变为非贪婪匹配
*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复
一般这样使用时要加上结尾条件,否则只会匹配量词的最少重复次数

2.模块re的常用函数

print(re.findall('你','你好你是')) # ['你', '你']
ret = re.search('你','好是') # 找到后需要调用group()方法,找不到返回None,None不能调用group()方法
if ret:
print(ret.group())
ret = re.match('你','ni好你是') # 和search用法类似
if ret:
print(ret.group())
ret = re.split('b','abc') # 按“b”分割字符串
print(ret) # ['a', 'c']
ret = re.split('[ad]','adbcde') # 先按“a”分割,再按“b”分割
print(ret)
print(re.sub('d','$','zhao123'))
print(re.subn('d','$','zhao123'))
obj = re.compile('你好')
ret = obj.findall('你好吗')
print(ret)
ret = re.finditer('你好','你好吗你好')
print(ret.__next__().group())