C#多线程逻辑编程
多线程编程以难著称, 有很多人碰见多线程编程就会畏缩, 不敢前进, 言必称死锁/卡死. 但是合理编程是不会碰到死锁这种问题.
对语言了解
工欲善其事必先利其器, 必须要对语言提供的同步机制和期扩展有所了解.
Linux系统(库)提供的同步机制有:
- 锁
- 原子操作
- 条件变量
其中原子操作对个人编程能力要求较高, 所以在编写逻辑的时候, 一般不使用, 只是用来制作简单的原子计数器; 锁和条件变量在逻辑编程时使用的较多. 但是Linux pthread提供的mutex并不是一个简单实现的锁, 而是带有SpinLock和Futex多级缓冲的高效实现.
所以在Linux下使用Mutex编程, 一般不太会遇到严重的性能问题. Windows下就需要注意, Windows下也有类似的同步机制(毕竟操作系统原理是类似的), 只是Windows下的Mutex是一个系统调用, 意味着任何粒度大小的Mutex调用都会陷入到内核. 本来你可能只是用来保护一个简单的计数器, 但是显然内核的话就要消耗微秒级别的时间, 显然得不偿失. 所以Windows上还有一种不跨进程的同步机制Critical Section, 该API提供了一个Spin Count的参数. Critical Section提供了两级缓冲, 在一定程度上实现了pthread mutex的功能和效率.
C#提供的锁机制, 和Windows上的有一些类似, 不够轻量级的锁是通过lock关键字来提供的, 背后的实现是Monitor.Enter和Monitor.Exit.
条件变量在多种语言的系统编程里面, 都是类似的. 一般用来实现即时唤醒(的生产者消费者模型). C#里面的实现是Monitor.Wait和Monitor.Pulse, 具体可以看看MSDN.
除了这些底层的接口, C#还提供了并发容器, 其中比较常用的是:
- ConcurrentDictionary
- ConcurrentQueue
其中Queue主要用来做线程间发送消息的容器, Dictionary用来放置线程间共享的数据.
多线程编程的最佳实践
多线程编程需要注意的是锁的粒度和业务的抽象.
一般来讲, 锁的效率是很高的. 上面我们提到pthread mutex和Critical Section都有多级缓冲机制, 其中最重要的一点就是每次去lock的时候, 锁的实现都会先去尝试着Spin一段时间, 拿不到锁之后才会向下陷入, 直到内核. 所以, 在编写多线程程序的时候, 至关重要的是减少临界区的大小.
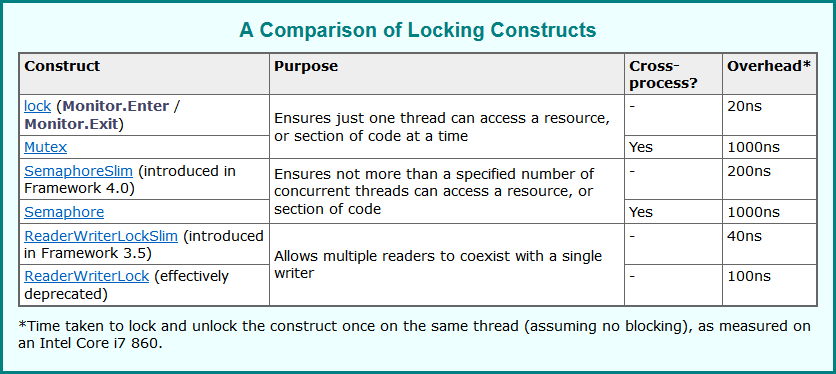
可以看到上面这张图, Monitor.Enter的成本是20ns左右, 实际上和CAS的时间消耗差不多(CAS是17ns左右).
所以不能在锁内部做一些复杂的, 尤其是耗时比较长的操作. 只要做到这一点, 多线程的程序, 效率就可以简单的做到最高. 而无锁编程, 本质上还是在使用CAS, 编程的难度指数级的提升, 所以不建议逻辑编程里面使用无锁编程, 有兴趣的话可以看多处理器编程的艺术.
多线程逻辑的正确性是最难保证的. 但是据我观察下来, 之所以困难, 大多数是因为程序员对业务的理解程度和API设计的抽象程度较低造成的.
对一个所有变量都是public的类进行多线程操作, 难度必然非常大, 尤其是在MMOG服务器内有非常复杂的业务情况下, 更是难以做到正确性, 很有可能多个线程同时对一个容器做各种增删改查操作. 这种无抽象的编程就是灾难, 所以做到合理封装, 对模型的抽象程度至关重要.
充血模型
上面说的无抽象的编程是灾难, 面向对象里面把这种设计叫做贫血模型, 只有数据没有行为; 而我们做的MMOG服务器, 里面包含大量的业务, 即行为. 这时候用贫血模型做开发, 会导致业务处理的地方代码写的非常多, 而且难以重用, 外加上多线程引入新的复杂性, 导致编写正确业务的多线程代码难以实现. 所以需要在数据的层次上加上领域行为, 即充血模型.
充血模型没有统一的处理方式, 而是需要在业务的接触上面不断的提炼重构. 举例来说, 我们有一个场景类Scene, 玩家Player可以加入到Scene里面来, 也可以移除, 那么就需要在Scene类上面增加AddPlayer和RemovePlayer. 而对于多线程交互, 只需要保证这些Scene上面的领域API线程安全性, 就可以最起码保证Scene类内部的正确性; 外部的正确性, 例如过个API组合的正确, 是很难保证的. 当然这个例子只是一个简单的例子, 实际的情况要通过策划的真实需求来设计和不断重构.
这边之所以把充血模型提出来说, 是我发现大部分项目组里面实现的抽象级别都过低. 合理的抽象使代码的规模减少, 普通人也能更容易维护.
并行容器的选择
C#虽然提供了ConcurrentDictionary, 但是不代表任何场景下该容器都是适用的. 具体问题需要具体分析.
首先要看我们的临界区是不是那么大, 如果临界区很小, 而且访问的频率没有那么高(即碰撞没那么高). 那么是不需要适用ConcurrentDictionary.
例如游戏服务器, 每个玩家都在单独的场景内, 他所访问的对象, 大部分都是自己和周围的人, 那么是不太会访问到其他线程内的复杂对象. 那么就只需要用Dictionary, 最多用lock保护一下就行了.
只有真正需要在全局共享的容器, 还有很多线程高频率的访问, 才需要使用ConcurrentDictionary.
某游戏服务器里面有不少使用ConcurrentDictionary容器的代码, 其中有一些非常没有必要. 而且我们看代码也会发现:
[__DynamicallyInvokable]
public ConcurrentDictionary() : this(ConcurrentDictionary<TKey, TValue>.DefaultConcurrencyLevel, 31, true, EqualityComparer<TKey>.Default)
{
}
private static int DefaultConcurrencyLevel
{
get
{
return PlatformHelper.ProcessorCount;
}
}C#默认将ConcurrentDictionary的并发度设置成机器的CPU线程个数, 比如我是8核16线程的机器, 那么并发度是16.
某游戏服务器, 一个场景的线也就是四五十人, 大部分情况下都小于四五十人. 但是用16或者更高的并发度, 显然是不太合适的. 一方面浪费内存, 另外一方面性能较差. 所以后面大部分ConcurrentDictionary并发度都改成了4左右.
多读少写场景下的优化
多写场景下, 代码实际上很那优化, 基本思路就是队列. 因为你多个线程去竞争的写, 锁的碰撞会比较激烈, 所以最简单的方式就是队列(观察者消费者).
多读场景下, 有办法优化. 因为是多线程程序, 程序的一致性是很难保证. 时时刻刻针对最新值编程是极其困难的, 所以可以退而求其次取最近值, 让程序达到最终一致性.
每次数据发生变化的时候, 对其做一个拷贝, 做读写分离, 就可以很简单的实现最终一致性. 而且读取性能可以做到非常高.
private object mutex = new object()
private readonly List<int> array = new List<int>();
private List<int> mirror = array.ToList();
public List<int> GetArray()
{
return mirror;
}
//这个只是示例代码, 为了表达类似的意思
private void OnArrayChanged()
{
lock(mutex) mirror = array.ToList();
}多线程检测机制
某游戏服务器里面碰到一个非常棘手的问题, 就是多线程逻辑. 好的一点是副本地图是分配到不同的线程内, 大部分的业务逻辑在地图内执行, 但是因为某些原因写了很多逻辑可能并没有遵守约定, 导致交叉访问, 进而产生风险. 解决这个问题, 思路也有很多, 最简单的方式就是把服务器拆开, 让服务器与服务器之间他通过网络来通讯, 那么他们很显然就访问不到其他进程的领域独享(非共享内存), 也就不会出现多线程的问题, 但是时间上不太允许这么干.
所以后来选择了一条比较艰难的道路.
Rust语言有一种概念叫所有权Ownership. 在rust内, 拥有对象生命周期的所有者把持, 其他对象不能对他进行写操作, 因为写操作需要所有权, 但是可以进行读操作(类似于C++的const &). 这种所有权的实现有两种, 一种是编译时期的静态检测, 一种是动态时期的检测. 动态检测是通过reference count来实现.
而某游戏服务器内, 领域对象实际上也有自己归属的线程(地图). 所以我们可以在领域对象进入地图的时候做标记, 出地图的时候做比较, 然后在读写其属性的时候, 就可以检测出来, 是不是在访问不属于自己线程的对象. 进而实现跨线程对象检测机制.
具体代码侧, 在每次实现public属性的时候, 看看是不是访问了复杂容器, 如果访问了, 插入检测代码, 就可以了. 最后就变成一个工作量问题.
//这是一个扩展方法, 检测当前线程和含有CurrentThreadName对象的线程是不是相等
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static void CheckThread(this ICurrentThreadName obj)
{
if (obj.CurrentThreadName == "IdleThread" || string.IsNullOrEmpty(Thread.CurrentThread.Name))
return;
if (!string.IsNullOrEmpty(obj.CurrentThreadName) && obj.CurrentThreadName != Thread.CurrentThread.Name)
{
nlog.Error($"Thread:{Thread.CurrentThread.Name} Access Thread:{obj.CurrentThreadName}'s Object:{obj.GetType().FullName}, StackTrace:{Environment.NewLine}{LogTool.GetStackTrace()}");
var stackTrace = new StackTrace();
ReportThreadError.PostThreadError(Thread.CurrentThread.Name, obj.CurrentThreadName, obj.GetType().Name, stackTrace.ToString());
}
}
public CreDelayerContainer CreDelayerContainer
{
get
{
this.CheckThread();
return this.xxxx;
}
}通过这种方式, 把服务器内上千处错误的调用找到并且修复掉. 让服务器在多线程环境下变的稳定. 当然, 这个没有解决本质问题, 本质问题就是多线程有状态服务器非常难实现.
如果项目走到这个阶段, 可以尝试着使用这种方式抢救一下.
通过这种方式, 把服务器内上千处错误的调用找到并且修复掉. 让服务器在多线程环境下变的稳定. 当然, 这个没有解决本质问题, 本质问题就是多线程有状态服务器非常难实现.
如果项目走到这个阶段, 可以尝试着使用这种方式抢救一下.
参考: