用到了requests 和BeautifulSoup库 ,安装使用pip命令在cmd进行安装就行,这里都是先进行了解,之后再做几个小实例进行练习
先解释下爬虫,python爬虫可以通过获取网页的html代码,对其进行分析,得到可见和不可见的数据,也可以像网络发送请求,执行相应的操作,概括来说就这样
流程分为以下几步:
1.通过域名获取html代码数据
2.根据我们所需要的信息来对数据进行解析
3.存储目标信息
这是一个页面的基本流程,抓取多个页面时,对多个页面这样子做就行了,
首先为了对HTML代码进行分析,我们必须要了解下它,html比较简单我感觉,自己看看文档就能看得懂了,这里不说了,
下面先看一个简单的例子,对整个流程有一个认知
使用requests获取html,注意这里获取的是字符串,
import requests url ="http://www.runoob.com/html/html-intro.html"
r = requests.get(url) #对获取的内容用他的编码方式进行编码并解码,解决乱码问题 html = r.text.encode(r.encoding).decode()
获取之后,我们将其字符串转换为BeautifulSoup对象,html.parser是对解析器进行设置(Python标准库),还有html4lib,xml等,但是要安装其他c语言库,这里先用python标准库,具体用途不清楚,这里先用着, 回头去官网看
from bs4 import BeautifulSoup soup = BeautifulSoup(html,'html.parser')
获取到之后,soup.标签名就可以获取到相应标签的信息,例soup.title
如果想要获取所有的,可以用findAll方法进行,soup.findAll('h2') 找出所有h2标签,我们更关注的是其中的具体内容,可以这样做,遍历并取出其中文本生成content列表
content = [x.text for x in soup.findAll('h2')]
下面使用pandas将其存储为Excel表格,,设置列名称为url,存储为csv文件,目录为 当前目录
import pandas as pd df = pd.DataFrame(content,columns=[url]) df.to_csv('爬虫.csv')
最后一个基础流程,转到其他网页进行爬取,注意在获取网址时,注意网址时相对地址还是绝对地址,相对地址的话需要在前面添加字符拼接成绝对网址,后面才能访问,并且要根据需要对网址进行筛选,
比如需要获取html下面的网址,就需要判断网址的前面几个字符是否是html才行,如下
获取所有/html开头的链接,需要先判断是否有链接属性 links = [x for x in soup.findAll('a') if x.has_attr('href') and x.attrs['href'][0:5] == '/html'] urls = set([x.attrs['href'] for x in links]) absoulte_urls = {'http://www.runoob.com' + i for i in urls} absoulte_urls.discard(url)
获取所有链接之后,由于链接是相对路径,所以需要进行拼接得到绝对路径,为了避免重复元素,我们将它存储为一个集合:set() 之后再拼接存储为字典,并去除并去除本身的url,
之后我们可以进行循环爬取,比如下面的,
df = pd.DataFrame() for i in absoulte_urls: r = requests.get(i) html = r.text.encode(r.encoding).decode() soup = BeautifulSoup(html, 'html.parser') content = [x.text for x in soup.findAll('h2')] dfi = pd.DataFrame(content, columns=[i]) df = df.join(dfi, how='outer')
遍历获取好的绝对链接,按照原本的步骤进行分析, 找到h2标题,并将其整合存储到df当中去,这里还是比较简单的,下面的记录一下常用的网络爬虫工具
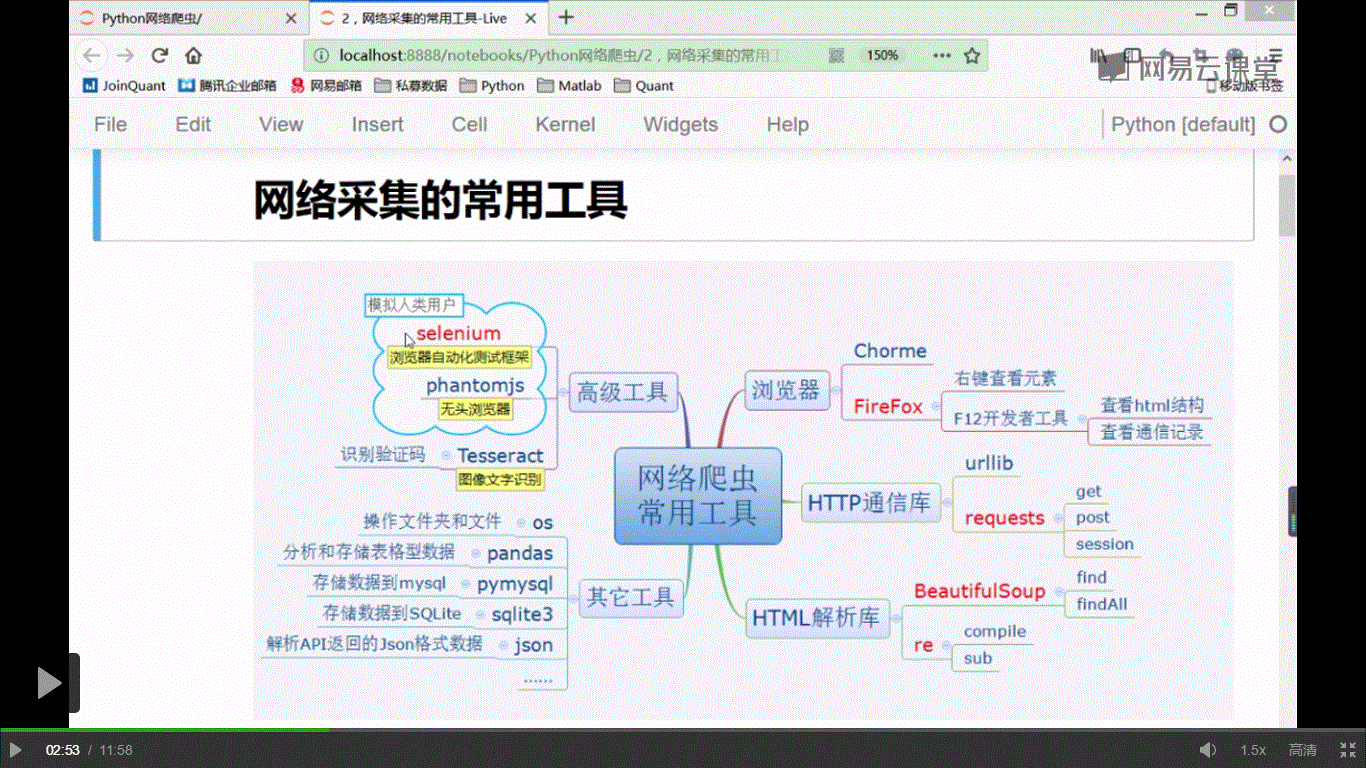
下面对requests进行说明,
request可以进行post和get等请求的处理,也可以处理form表单,进行身份验证等,主要用于和服务器进行通信的,具体查看官方文档http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
status_code 返回的状态码
1.查看网页元素
2.查看网络通信
3.查看请求的headers(这个有时候请求失败时就需要进行设置,之前爬取校园网时候就是这样)
4.定位xhr动态请求url(比如有一些信息必须时下拉时才会刷新出新的东西,并不在刚开始的网址,而是要看他的通信记录,抓取相应的包才行,这就是动态请求,所以获取url时,需要先查看响应再查看headers里面是否有想要的 )
BeautifulSoup和re
正则表达式是按照一定规则进行字符串匹配的,BeautifulSoup本质上就是用re实现的,对html代码进行分析,具体的看收藏的博客文档进行学习吧,根据需要的功能进行学习就行哈,
对于一些动态网页来说,需要将鼠标点击或者放置在某个位置才会显示相应的信息,requests无法运行css,js脚本(不改变当前的url),这时就需要来模拟用户的操作,使用selenium进行,它本来是用于进行测试脚本能否在不同的浏览器上面能否执行的,
phantom是一种无头浏览器, 可以进行运行,js脚本,解析css,html文件但是却不需要图形界面,selenium和phantom联合可以进行破解反爬虫,抓包,抓取动态网页等,但是它的速度相应的会慢一点
下面记录一下对于复杂html的解析
一般常用的就是find和findAll方法,他们前两个参数是标签和属性,name ,attr,一般也就用这两个
name = {'g1','h2'} 这是一个集合,满足一个就行了, attrs传入的是一个字典,对查找的属性进行限制比如 attrs = {'class':{'article','aaaa'}} 即标签当中的class属性必须是这两个当中的一个
、。。。。。。。好吧,忘记保存了,,,,,懒得写了,就贴一些代码供自己以后参考吧
# 获取风景图片 url ="http://sc.chinaz.com/tupian/fengjingtupian.html" headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER'} r = requests.get(url, headers=headers) soup = BeautifulSoup(r.text.encode(r.encoding).decode(), 'html.parser') # 得到图片地址 imgs = soup.findAll(lambda tag: tag.name == 'img' and tag.has_attr('src2')) src2s = [i.attrs['src2'] for i in imgs] j = 1 # 根据url获取图片并进行存储,wb表示二进制存储,content用于获取图片内容 os.chdir('C:\learn\python\爬虫基础学习') filedir = os.getcwd() + '\风景' if not os.path.exists(filedir): os.mkdir(filedir) for i in src2s: ri = requests.get(i, headers=headers) if ri.status_code == 200: with open(filedir+'\%s.jpg' % j, mode='wb') as f: print('正在下载第%d张图片' % j) f.write(ri.content) j = j+1
下面学习一下如何获取所有页当中的内容,这里先说下具体思路,对于分页来说,一般情况下它的每一页的链接都是有规律的,你可以根据得出他的页数然后进行循环获取所有的链接,但是这样太麻烦了,。。。想起来我第一次完成test时候什么都不会就是这样做的,真的蠢。另一种方法是,每一个页面如果它有下一页的话,都会有下一页的链接,我们可以根据标签获取到下一页的链接,相当于每一页就是获取了该页的文章链接以及它下一页的链接,可以使用字典进行存储,之后将获取的下一页链接再作为参数继续获取下一页的内容,注意最后一页是没有下一页的,所以这里要进行异常处理,捕捉异常并将下一页链接设置为空,这样子只需要循环获取每一页的内容直到下一页链接为空就可以了。
贴下代码供自己以后参考
# 获取苏轼的所有诗词 baseUrl = "http://www.shicimingju.com" url = 'http://www.shicimingju.com/chaxun/zuozhe/9.html' # 定义获取一页之中所有诗词链接和下一页对应的链接 def get_One_Page(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER' } r = requests.get(url) soup = BeautifulSoup(r.text.encode(r.encoding).decode(), 'html.parser') # 筛选出www-shadow-card www-main-container下的h3标题并获取其中的链接 div = soup.find('div', class_='www-shadow-card www-main-container') list = [i.find('a').attrs['href'] for i in div.findAll('h3')] hrefs = [baseUrl + i for i in list] # 获取下一页的链接 try: # 找到相应的div下的text为下一页的标签a的href nextUrlDiv = soup.find('div', class_='pagination www-shadow-card') nextUrl = baseUrl + nextUrlDiv.find(re.compile(''), text='下一页').attrs['href'] except Exception as e: print('最后一页了。。。') nextUrl = '' ans = { 'hrefs': hrefs, 'nextUrl': nextUrl } return ans def write_To_Text(url,i): r = requests.get(url) soup = BeautifulSoup(r.text.encode(r.encoding).decode(), 'html.parser') content = soup.find('div', class_='shici-content').text txtDir = os.getcwd() + '\%s.txt' % i with open(txtDir, 'w') as f: f.write(content) ans = get_One_Page(url) allHrefs = ans['hrefs'] # 循环获取所有的链接,直至下一页不存在 while ans['nextUrl'] != '': ans = get_One_Page(ans['nextUrl']) allHrefs.extend(ans['hrefs']) os.chdir('C:\learn\python\爬虫基础学习') for i in range(1, 100): write_To_Text(allHrefs[i], i)