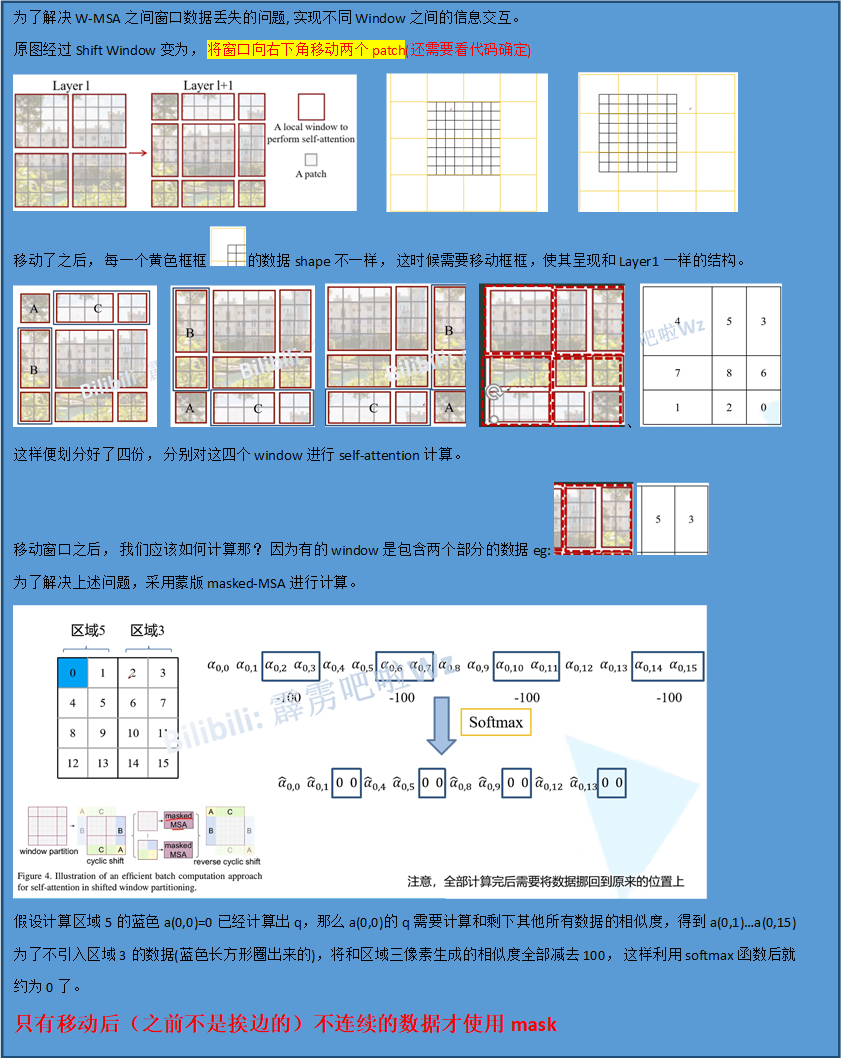
CNN理解
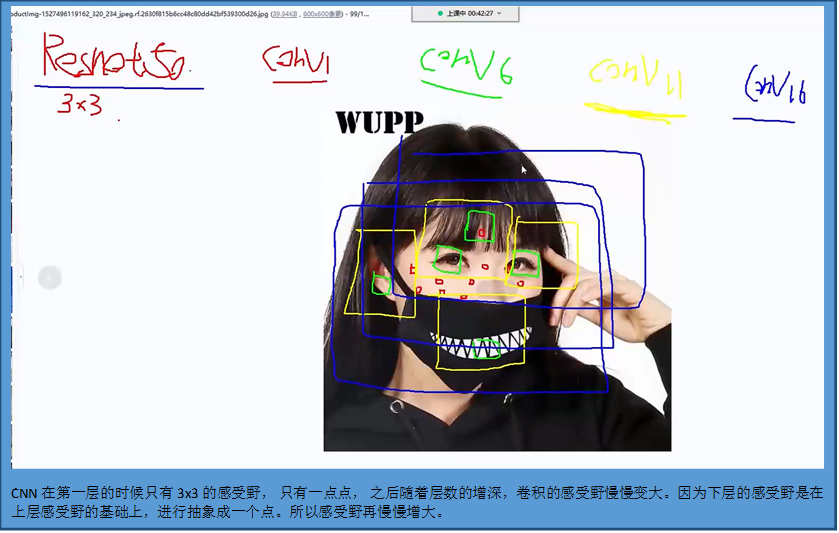
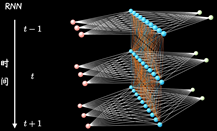
RNN
Why:
CNN都是水平方向延伸,没有考虑单个隐藏层在时间上时序的变化。RNN关注每一个神经元在时间维度上的不断成长
普通的结构
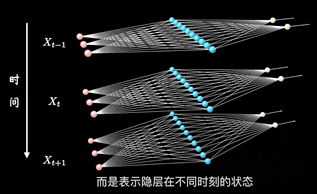
加入时序关联的结构:表示隐藏层在不同时刻的状态
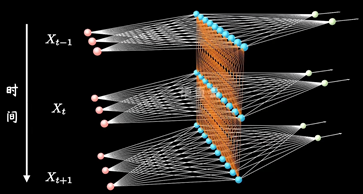
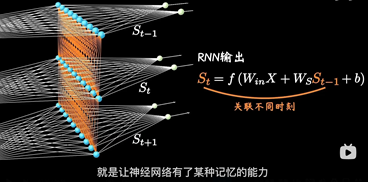
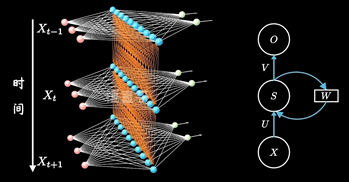
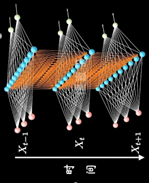
其中每个时间段的UWV权重矩阵都是共享一个
参考资料:
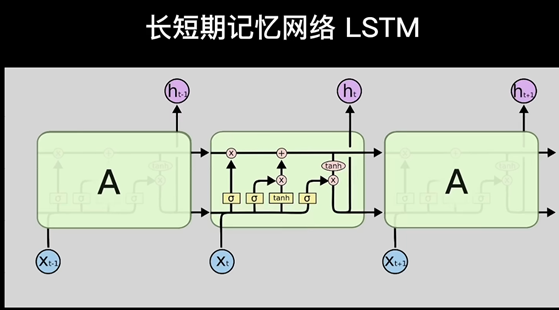
LSTM
参考: 【LSTM长短期记忆网络】3D模型一目了然,带你领略算法背后的逻辑_哔哩哔哩_bilibili
Why:
就像人的记忆不能无线延伸, 机器也是,通常超过十步就不行了,为了解决这个问题
研究者在普通RNN的基础上提出了LSTM(长短期记忆网络Long Short-term Memory)
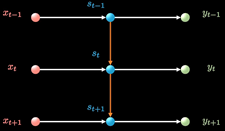
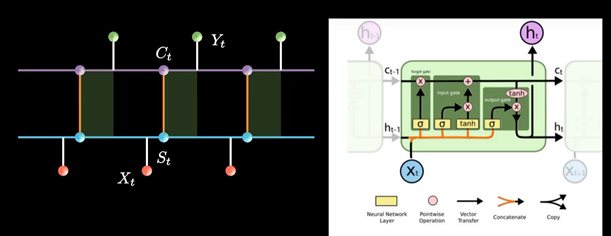
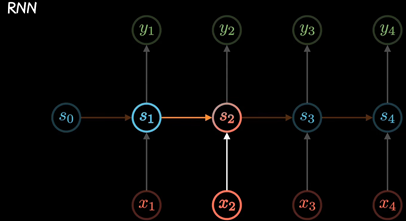
RNN以三个时间点为例,简化模型(xt是不同时间的输入, St是不同时间的隐藏层, y输出)
LSTM增加了一条新的时间链, 记录Long Term Memory, 用C表示, 同时增加了两条链接的关联关系
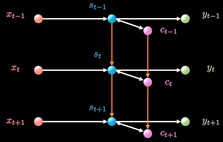
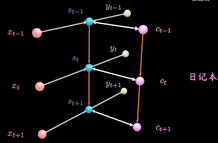
新增加的链条相当于日记本.
当计算隐藏层St的信息时, 除了输入Xt, 前一刻信息St-1 外还要包含当前的时刻记录的日记信息.
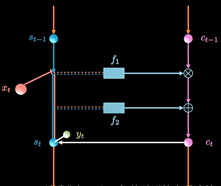
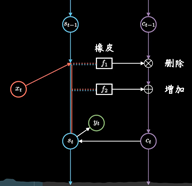
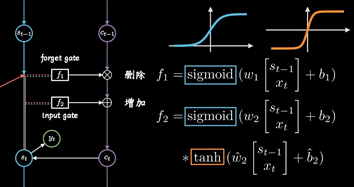
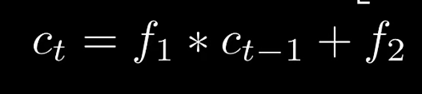
同时保持短期记忆链条St和长期记忆链条Ct, 并且相互更新, 这便是LSTM成功改的奥秘
Attention
参考: 【Attention 注意力机制】近年最流行的AI算法,transformer它爹_哔哩哔哩_bilibili
RNN模型建立了网络隐藏层之间的时序关联 , 每一时刻的隐藏层St, 不仅取决于输入Xt, 还取决于上一时刻转台St-1
两个RNN组合形成Encoder-Decoder模型
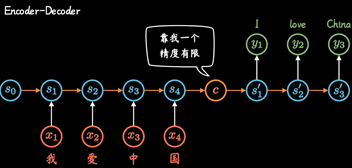
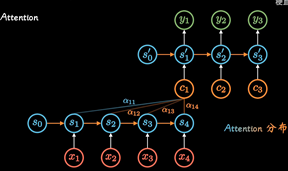
但是这种不管输入多长, 都统一压缩成形同长度编码C的做法,(眉毛胡子一把抓),会导致翻译精度下降.
Attention机制:通过每个时间输入不同的C解决这个问题, 其中ati表明了在t时刻所有输入的权重, 以Ct
的视角看过去,a权重就是不同输入的注意力, 因此也被称为Attention分布.
后来随着GPU等大规模并行运算的发展 , 人们发现RNN的顺序结构很不方便, 那以并行运算,效率太低
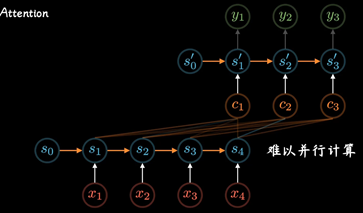
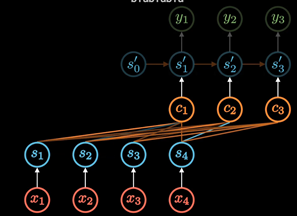
便去掉了RNN顺序, 变为self-attention, 在Encoding阶段计算每个单词和其他所有单词的关联

Transformer
参考资料:
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)_哔哩哔哩_bilibili
Transformer的PyTorch实现_哔哩哔哩_bilibili
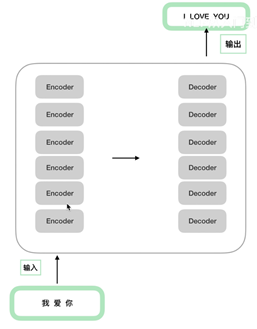
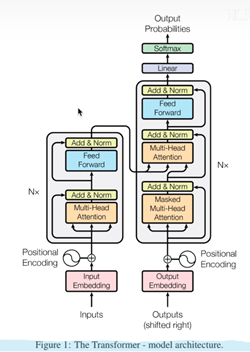
6(经验而得)个encoder和decoder的结构一样参数不一样。
Encoder
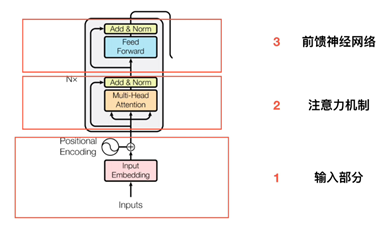
输入部分(Embedding, 位置嵌入)
Embedding
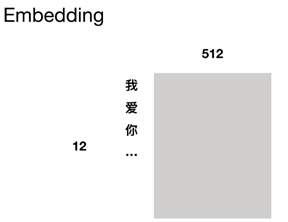
位置编码(不进行训练)

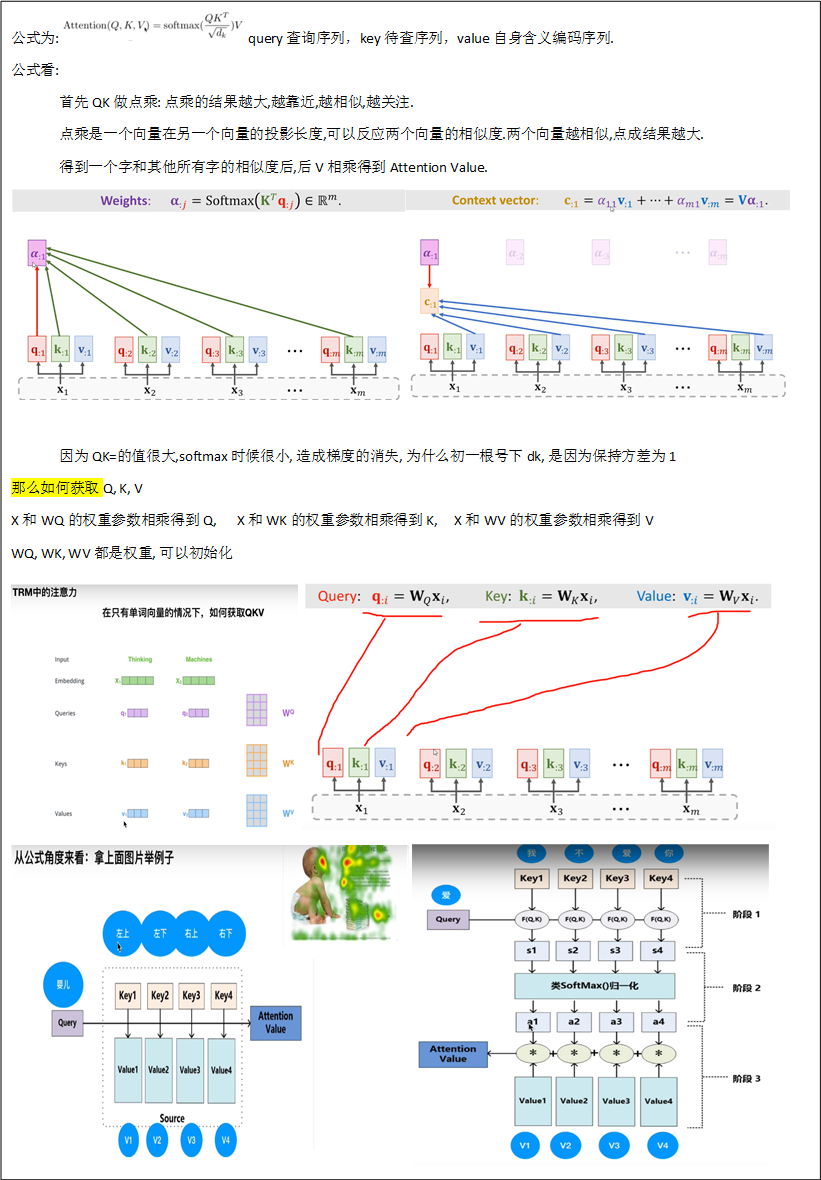
self-Attention
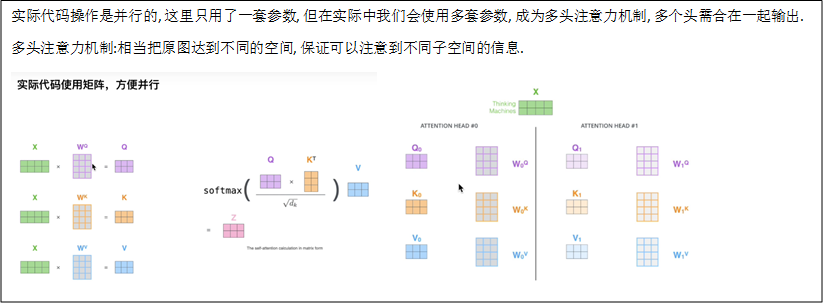
Layer Normalization

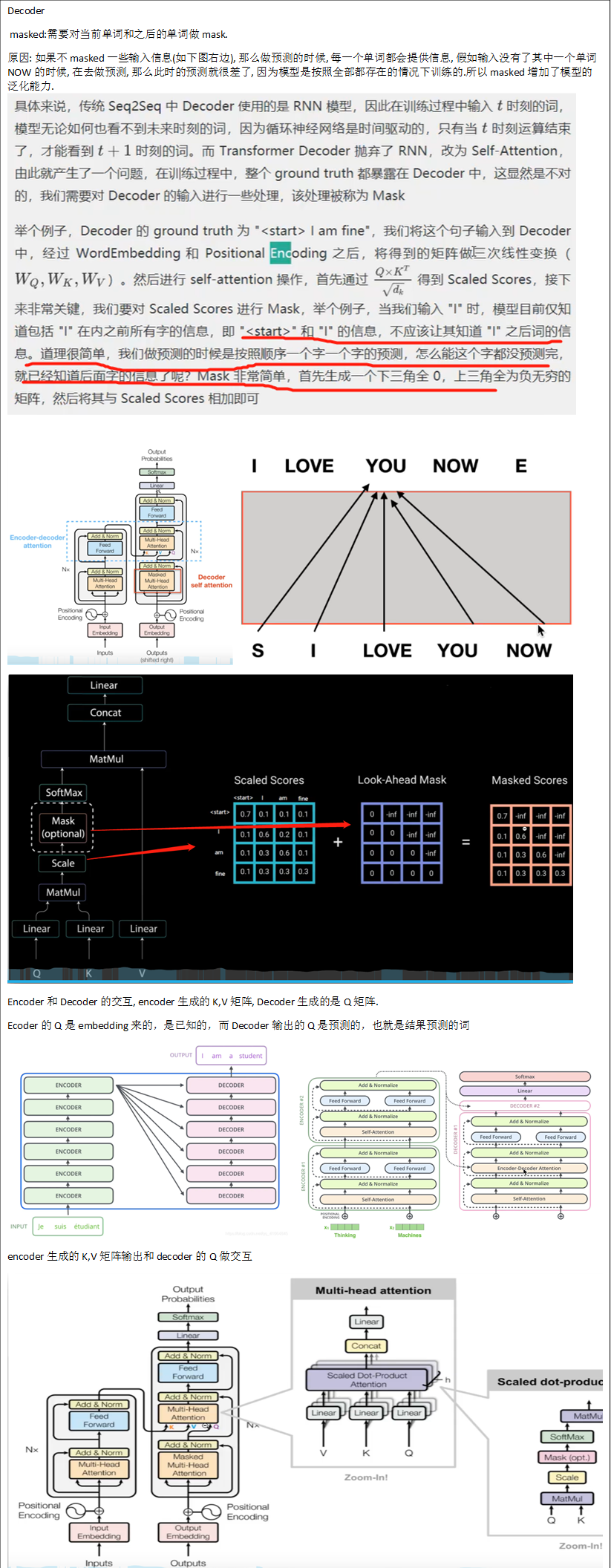
Decoder
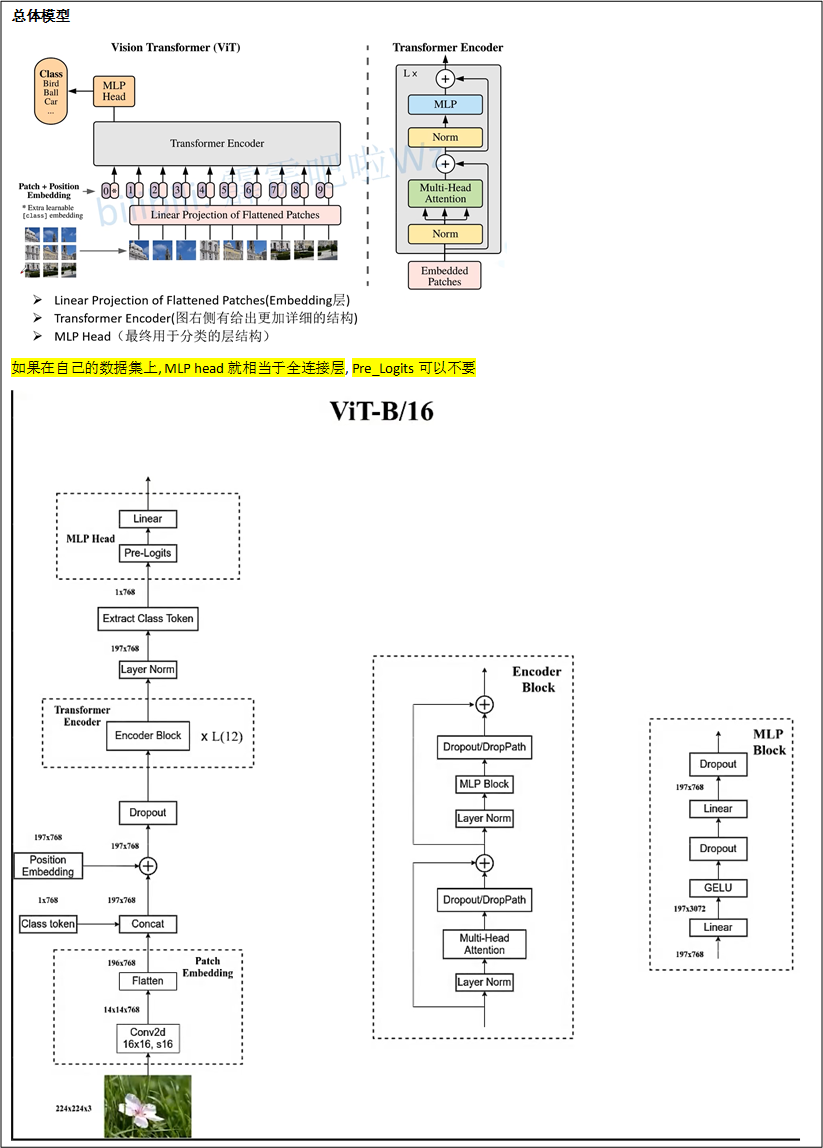
Vision-transformer
参考: 11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili
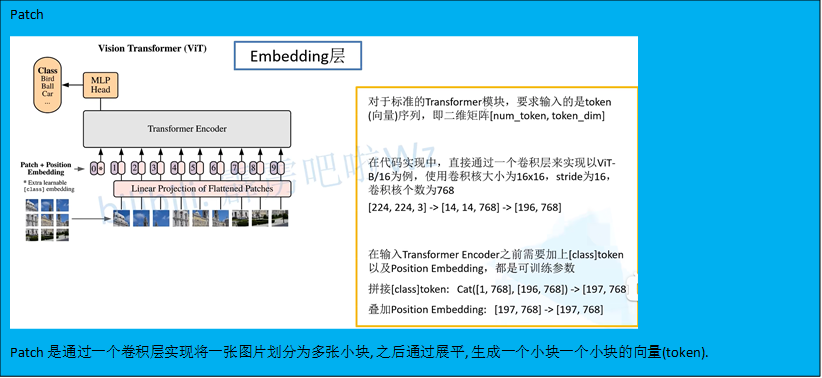
Patch embedding
代码
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
'''
patch_size: 将2D图片划分成16个小块
embed_dim: 每个小块的channels=embed_dim=768
grid_size: 每个小块的(w, h)
'''
super().__init__()
img_size = (img_size, img_size)
patch_size = (patch_size, patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1] # 这个是为了展平小块的一个向量,起了个这个名字
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) # 利用卷积实现
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
# 不可以更改输入图片的大小224
assert H == self.img_size[0] and W == self.img_size[1], f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten: [B, C, H, W] -> [B, C, HW] 从第二个维度展平
# transpose: [B, C, HW] -> [B, HW, C] 更换文职
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
return x
encoder
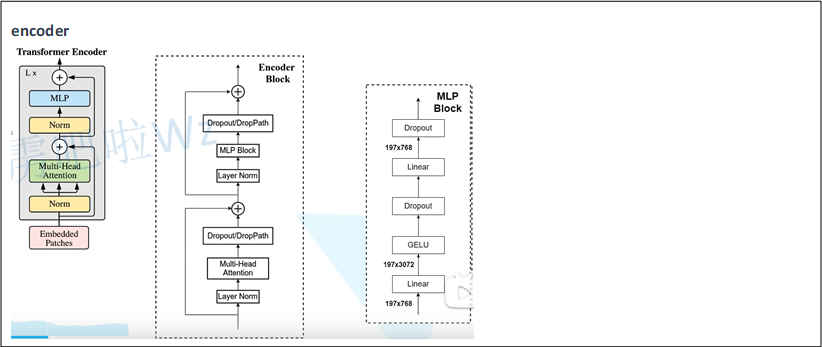
Attention代码

class Attention(nn.Module):
def __init__(self,
dim, # 输入token的dim
num_heads=8, # 8组共享Q, K, V的权重参数
qkv_bias=False,
qk_scale=None,
attn_drop_ratio=0., #
proj_drop_ratio=0.):
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads # 根据head的数目, 将dim 进行均分, Q K V 深度上进行划分多个head, 类似于组卷积
self.scale = qk_scale or head_dim ** -0.5 # 根号下dk分之一, 为了避免梯度过小
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # Q K V的计算是通过全连接层实现的?
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop_ratio)
# 一个小块中包14 x 14 = 197 个深度为768的单像素向量,
def forward(self, x):
# [batch_size, num_patches + 1, total_embed_dim] torch.Size([2, 197, 768]) num_patches + 1是小块的w * h + class, # total_embed_dim是一小块的深度
B, N, C = x.shape
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1) # 对每一行惊醒处理
attn = self.attn_drop(attn)
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
Swin-transform
参考:12.1 Swin-Transformer网络结构详解_哔哩哔哩_bilibili
Vision transformer 和Swin-transformer的区别
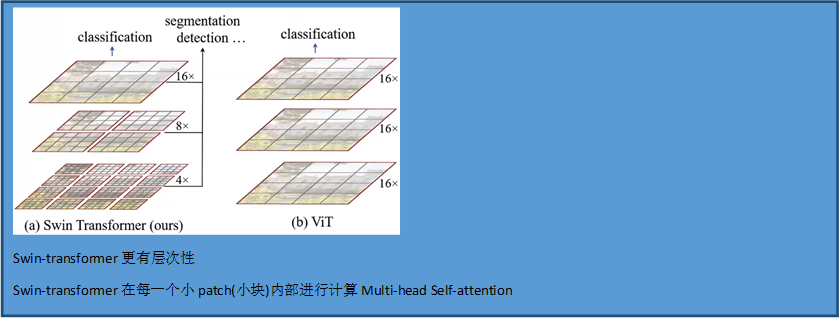
整体模型结构
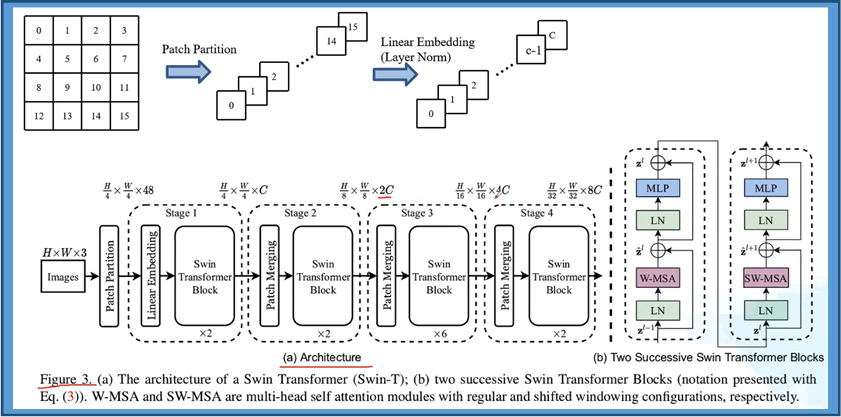
Patch

Shift Windows