报错
CUDNN_STATUS_INTERNAL_ERROR
重启pycharm
a leaf Variable that requires grad is being used in an in-place operation.


'NoneType' object is not callable
参考:解决TypeError: 'NoneType' object is not callable_小清华的小哥哥-CSDN博客


can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.


At least one stride in the given numpy array is negative, and tensors with negative strides are not currently supported. (You can probably work around this by making a copy of your array with array.copy().)
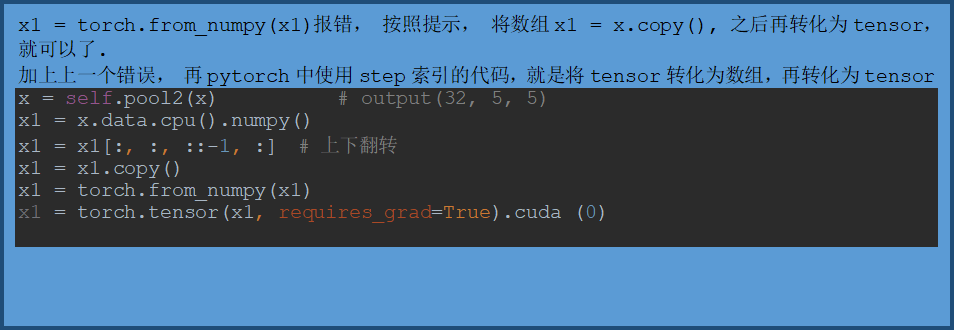

Pytorch一些有用的小代码
da = outputs.view(1, *outputs.size()) # 添加一维度
tensor.detach().numpy() # 能够实现对tensor 中数据的深拷贝, 转化为ndarray数据类型。
tensor.numpy()
# 循环添加模块
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# 变为连续的变量
x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
Pytorch的基本操作
维度变化
参考:numpy矩阵中维度的理解_Phoenix的博客-CSDN博客_numpy 矩阵维度


a=
tensor([[[4, 4, 5],
[1, 6, 8],
[4, 2, 2],
[4, 6, 2]],
[[5, 5, 2],
[9, 2, 5],
[1, 7, 4],
[6, 9, 1]]])
a.sum(0)
tensor([[ 9, 9, 7],
[10, 8, 13],
[ 5, 9, 6],
[10, 15, 3]])
a.sum(1)
tensor([[13, 18, 17],
[21, 23, 12]])
a.sum(2)
tensor([[13, 15, 8, 12],
[12, 16, 12, 16]])
# from __future__ import print_function # jupyter时导入print
import torch
# x = torch.Tensor([5, 3]) # 构造张量 #
# x = torch.zeros([5, 3]) # 全为 0 矩阵
# x = torch.empty([5, 3]) # 未初始化二维矩阵, 会用无用的数据填充
# x = x.new_ones([5,4]) # 基于tensor构造1矩阵
x = torch.randint(low=0, high=10, size=[5, 3]) # 创建三行四列的矩阵(整型数组),随机值区间为[low, high)
x = torch.randint_like(input=x, low=3, high=5) # 构造相同shape的矩阵
x = torch.rand([5, 3]) # 随机初始化矩阵,随机值区间为[0, 1)
#
# x = torch.add(x, x) # 加法
# x = x[1, 1] # 矩阵分割
# x = x.item() # 就获取【单个】Tensor的value
print(x)
# numpy和tensor的转换
print(torch.prod(torch.Tensor(list([1,2,3,4])))) # 将numpy或list转化为tensor
print(x.numpy()) # 将tensor转化为numpy
# 形状的修改
# view只适合对满足连续性条件(contiguous)的tensor进行操作,并且该操作不会开辟新的内存空间,只是产生了对原存储空间的一个新别称和引用,返回值是视图。
x = x.view([3, 5])
# 而reshape()方法的返回值既可以是视图,也可以是副本,当满足连续性条件时返回view,否则返回副本[ 此时等价于先调用contiguous()方法在使用view() ]。
# 因此当不确能否使用view时,可以使用reshape。如果只是想简单地重塑一个tensor的shape,那么就是用reshape,但是如果需要考虑内存的开销而且要确保重塑后的tensor与之前的tensor共享存储空间,那就使用view()。
x = x.reshape([5, 3]) # 而reshape同时还可以对不满足连续性条件的tensor进行操作,具有更好的鲁棒性
print(x)
# 矩阵的基本函数
max = x.max() # 最大值
dim = x.dim() # 获取维度 torch.Size([5, 3])
size = x.size() # size = shape
shape = x.shape
std = x.std() # 标准差, 必须是float类型的数据
T = x.t() # 转置
# 矩阵交换,高纬转置
x2 = torch.randint(low=1, high=10, size=(3, 2, 4))
print(x2)
# x3 = x3.transpose(0, 1) # 将0,1维度交换
x4 = x2.transpose(0, 2) # 将0,1维度交换
# x3 = x3.permute(1, 0, 2) # # 将0,1维度交换
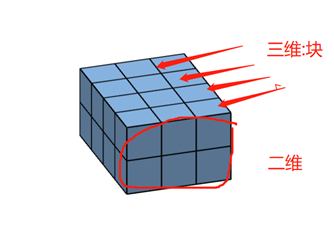
# 如何理解维度交换或高维转置
'''
首先转置,就是换一个角度观看数据,
想想魔方换一个角度去看
x2=
tensor([[[7, 2, 7, 4],
[8, 2, 1, 8]],
[[9, 6, 2, 7],
[5, 5, 8, 7]],
[[4, 5, 3, 3],
[3, 8, 1, 3]]])
将x2想象成一个由一个个小正方体组成的立体图片给,或长宽不等的魔方。
[[7, 2, 7, 4],
[8, 2, 1, 8]], 将第三维度的数据分开,并将第三维度看成"块",
一整块一整块的的数据(就是魔方中的一面【长方体】)
[[9, 6, 2, 7],
[5, 5, 8, 7]],
[[4, 5, 3, 3],
[3, 8, 1, 3]]
那么,上述shape(3, 2, 4)的数据,共有3块,
长度为2,宽度为4的长方体(先想象一个长方体,然后再将3块长方体堆在一起)
那么将第0维度和第2维度交换后,就是将3, 4交换,
此时想象如何转动魔方能够看到(4, 2, 3)形状的数据,
首先将之前宽度为4旋转变为块,然后在旋转长和宽,得到
tensor([[[7, 9, 4],
[8, 5, 3]],
[[2, 6, 5],
[2, 5, 8]],
[[7, 2, 3],
[1, 8, 1]],
[[4, 7, 3],
[8, 7, 3]]])
关键是想象旋转
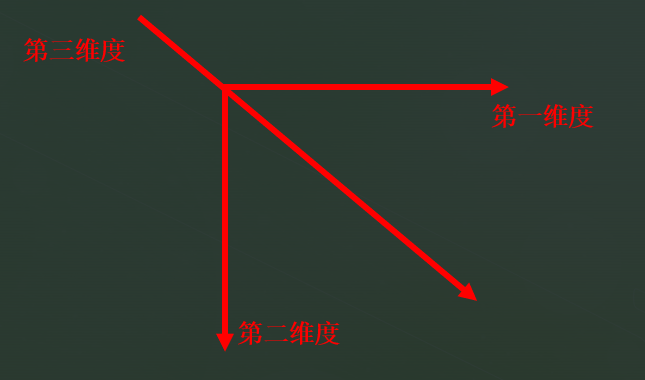
还有最重要的一点,如果是高维度的数据,就难以想象了,此时我们只需要记得, 最后一个维度代表的信息是以行的形式展出,
Eg(7, 9, 4), 记住本质数据没有动,只是观察的角度变了。
'''

torch.cat((array, array), dim=)
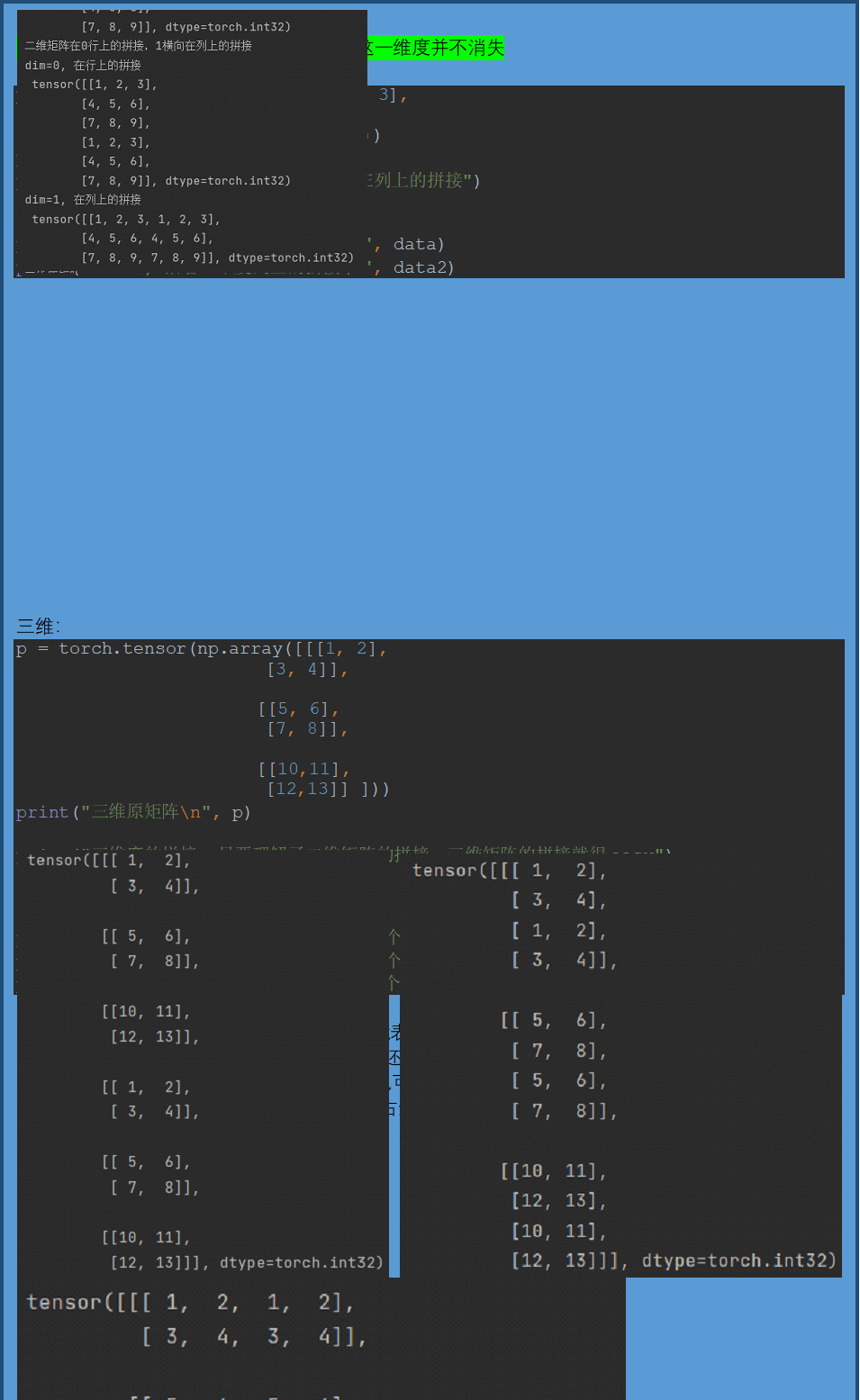

# 本质是:沿着哪一个维度进行拼接
import torch
import numpy as np
p = torch.tensor(np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]))
print("二维原矩阵\n", p)
print("二维矩阵在0行上的拼接,1横向在列上的拼接")
data = torch.cat((p, p), dim=0)
data2 = torch.cat((p, p), dim=1)
print("dim=0, 在行上的拼接\n", data)
print("dim=1, 在列上的拼接\n", data2)
p = torch.tensor(np.array([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]],
[[10,11],
[12,13]] ]))
print("三维原矩阵\n", p)
print("三维度的拼接, 只要理解了二维矩阵的拼接,三维矩阵的拼接就很easy")
data0 = torch.cat((p, p), dim=0) # 数据是三维度,dim=0,
是指的第三维度,则是将两个三维度中的二维度的数据纵向堆起来,
值改变了三维度的深度
data1 = torch.cat((p, p), dim=1) # 和二维维度的拼接一样,
在行上的拼接,二维度的行深度增加, 通道上的拼接操作
data2 = torch.cat((p, p), dim=2) # 和二维度的拼接一样,
在列上的拼接,二维度的列深度增加
print(data0)
torch.stack((array, array), dim=)
函数stack()对序列数据内部的张量进行扩维拼接,dim是选择生成的维度。
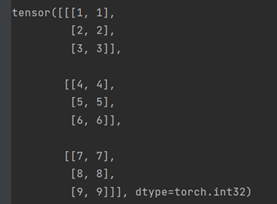
a = tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]], dtype=torch.int32)
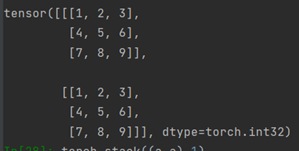
a是二维数据,stack((a, a), 0)
在dim=0时候,是生成比数据大一维度的数据,a是二维数据,则dim=0,意思是将第二维度整体看作一个tensor拼接生成第三维度,在第三维度上将两个a拼接。
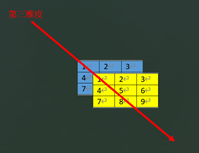
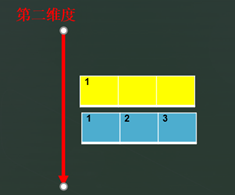
stack((a, a), 1)
在dim=1时候,准备生成第二维度,则将a的第一维度行整体看作一个tensor拼接生成第二维度,在第一维度上将两个a拼接。
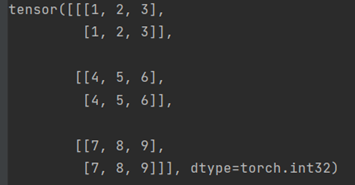
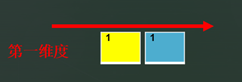
stack((a, a), 2)
在dim=2时候,准备生成第第一维度,则将a的单个数据看作一个tensor拼接生成第一维度。
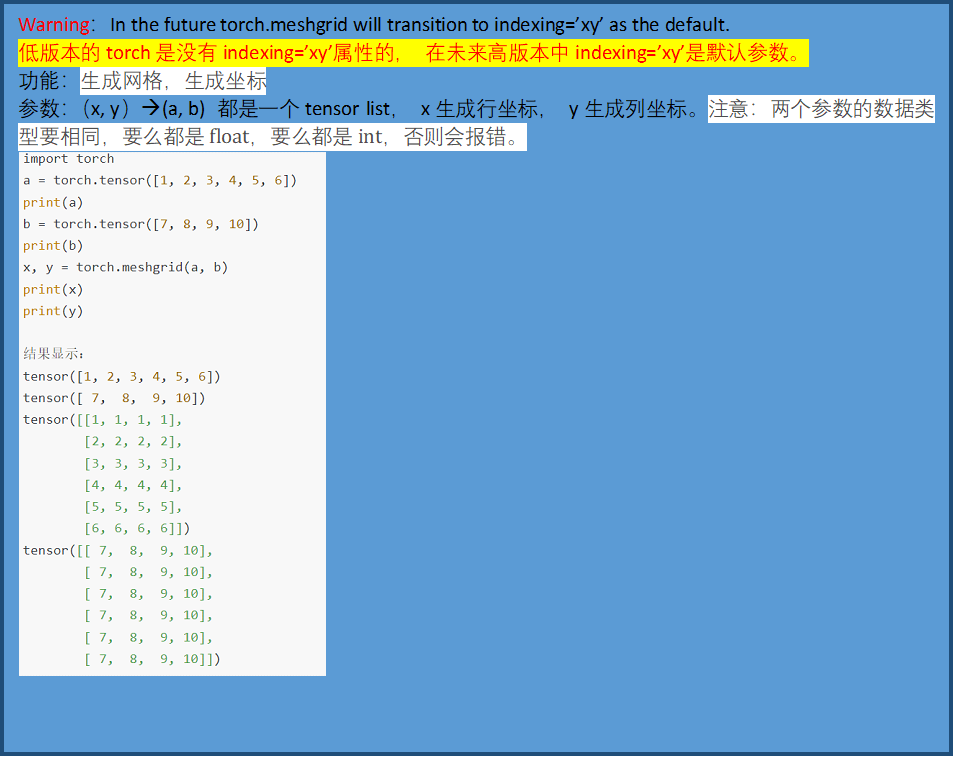
torch.meshgrid(*tensors, indexing=None)
参考:
https://blog.csdn.net/weixin_39504171/article/details/106356977
https://blog.csdn.net/qq_41375609/article/details/102828154

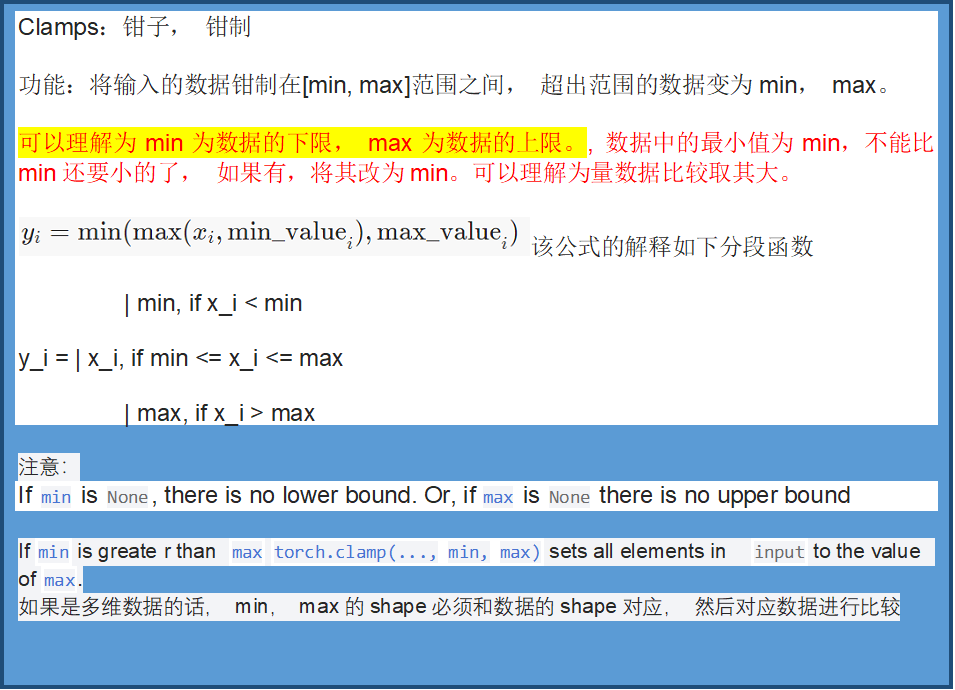
torch.clamp(input, min=None, max=None, *, out=None) → Tensor
参考:https://blog.csdn.net/qq_41375609/article/details/102828154

import torch
a = torch.randint(1, 10, size=(2, 2))
min = torch.randint(1, 10, size=(2, 2))
print("a:", a)
print("min:", min)
print("torch.clamp(a, min=min):", torch.clamp(a, min=min))
# 可以看到当min取列表的时候, a和min会对应元素比较,
print("torch.clamp(a, max=min):", torch.clamp(a, max=min))
输出为:
a: tensor([[5, 7],
[7, 1]])
min: tensor([[9, 7],
[5, 8]])
torch.clamp(a, min=min): tensor([[9, 7],
[7, 8]])
torch.clamp(a, max=min): tensor([[5, 7],
[5, 1]])
torch.flatten(input, start_dim=0, end_dim=- 1)


import torch
a = torch.randint(1, 10, size=(3, 3, 3)) # start_dim = [0, 1, 2]
b = torch.flatten(a)
c = torch.flatten(a, start_dim=0)
d = torch.flatten(a, start_dim=1)
e = torch.flatten(a, start_dim=2)
f = torch.flatten(a, start_dim=0, end_dim=1) # 还需要继续理解
print("a:", a)
print("torch.flatten(a):", b)
print("torch.flatten(a, start_dim=0):", c) # 在第一维度上展平, 展平成一行
print("torch.flatten(a, start_dim=1):", d) # 在第二维度上展平, 将二维中的一维度数据展平
print("torch.flatten(a, start_dim=2):", e) # 在第三维度上展平, 将三维中的二维度数据展平, 和原数据一样
print("torch.flatten(a, start_dim=0, end_dim=1):", f) # 还需要理解
# a: tensor([[[5, 7, 5],
# [8, 9, 2],
# [3, 4, 9]],
#
# [[1, 5, 4],
# [8, 4, 1],
# [7, 5, 3]],
#
# [[4, 4, 8],
# [1, 9, 1],
# [6, 9, 4]]])
# torch.flatten(a): tensor([5, 7, 5, 8, 9, 2, 3, 4, 9, 1, 5, 4, 8, 4, 1, 7, 5, 3, 4, 4, 8, 1, 9, 1,
# 6, 9, 4])
# torch.flatten(a, start_dim=0): tensor([5, 7, 5, 8, 9, 2, 3, 4, 9, 1, 5, 4, 8, 4, 1, 7, 5, 3, 4, 4, 8, 1, 9, 1,
# 6, 9, 4])
# torch.flatten(a, start_dim=1): tensor([[5, 7, 5, 8, 9, 2, 3, 4, 9],
# [1, 5, 4, 8, 4, 1, 7, 5, 3],
# [4, 4, 8, 1, 9, 1, 6, 9, 4]])
# torch.flatten(a, start_dim=2): tensor([[[5, 7, 5],
# [8, 9, 2],
# [3, 4, 9]],
#
# [[1, 5, 4],
# [8, 4, 1],
# [7, 5, 3]],
#
# [[4, 4, 8],
# [1, 9, 1],
# [6, 9, 4]]])
# torch.flatten(a, start_dim=0, end_dim=1): tensor([[5, 7, 5],
# [8, 9, 2],
# [3, 4, 9],
# [1, 5, 4],
# [8, 4, 1],
# [7, 5, 3],
# [4, 4, 8],
# [1, 9, 1],
# [6, 9, 4]])
torch.linspace()


functional.pad()
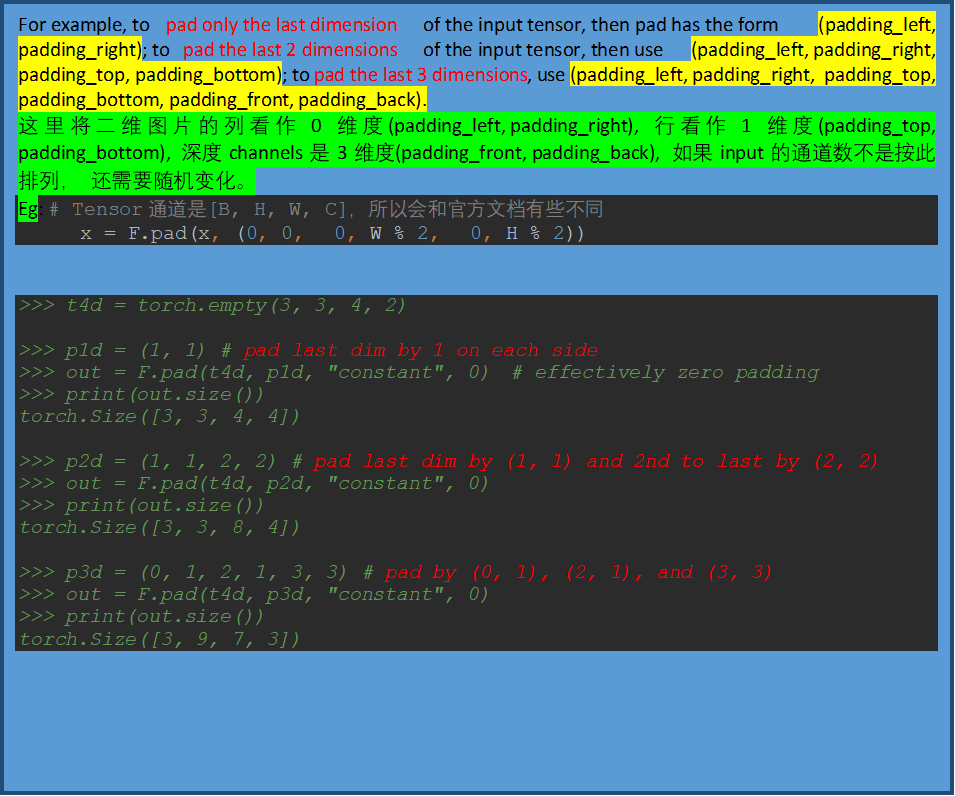

p[0::2, 0::2]矩阵的分割
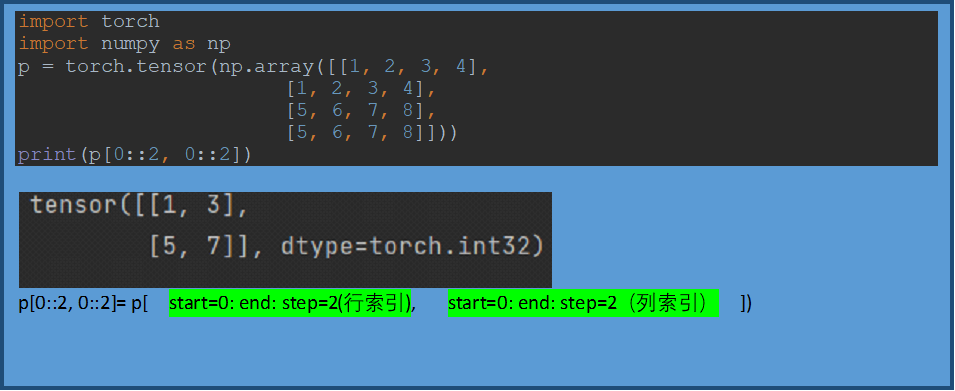

torch.unsqueeze()
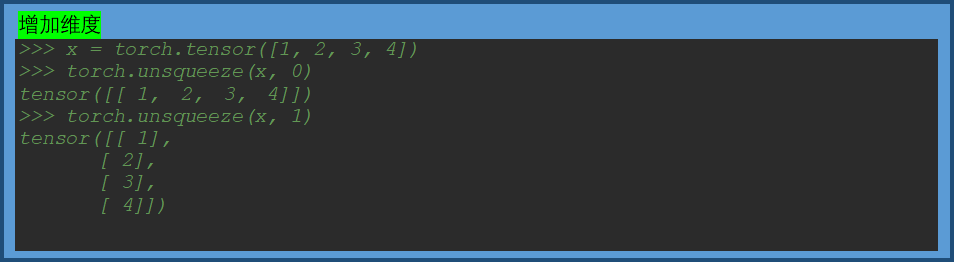

torch.nn.Parameter()
参考:PyTorch中的torch.nn.Parameter() 详解_Adenialzz的博客-CSDN博客

Torch.tensor.mean()
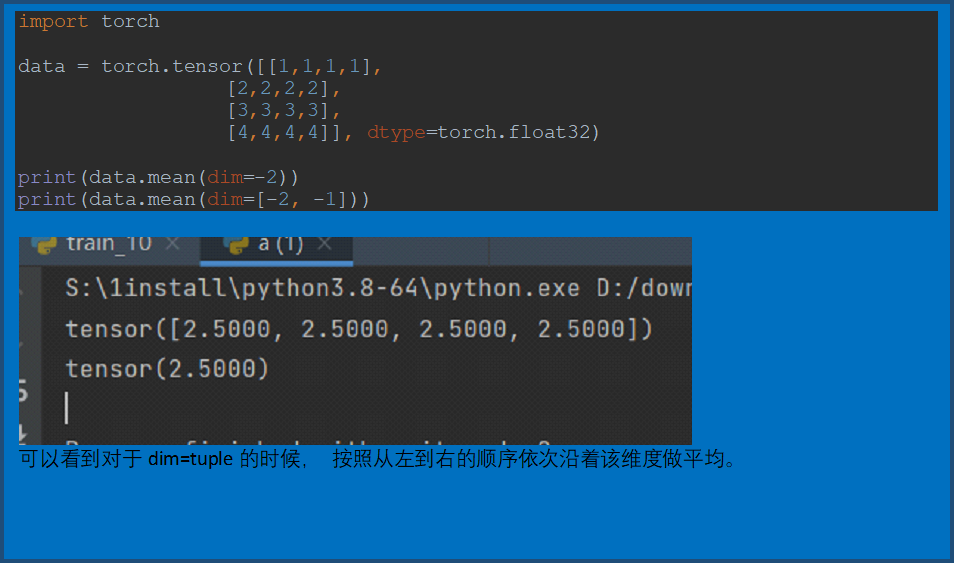

torch.roll()
广播机制
Pytorch的梯度操作
import torch
import torch
'''
每个张量都有一个 .grad_fn 属性保存着创建了张量的 Function 的引用,(如果用户自己创建张量,则grad_fn 是 None )
tensor的requires_grad 默认False, 如果开启了之后,那其操作也都开启
# backward之后, 只保存叶子节点的梯度, 中间梯度不保存
'''
# x = torch.ones([2,2], requires_grad=True) # 设置 requires_grad=True 来跟踪与它相关的所有计算
x = torch.tensor([2.], requires_grad=True)
y1 = x * x # 4
y2 = x * x * x # 8 # grad_fn=<AddBackward0> # 操作1 requires_grad = True
y3 = y1 + y2 # 12
'''
其实这里有更加重要的原因,就是避免向量(甚至更高维张量)对张量求导,而转换成标量对张量求导。但是pytorch不允许张量对张量求导,只允许标量对张量求导,求导结果是和自变量同形的张量。
所以必要时我们要把张量通过将所有张量的元素加权求和的方式转换为标量
'''
y3.backward()
print(y3.grad, y2.grad, y1.grad, x.grad)
# 输出:None None None tensor([16.]), backward之后, 只保存叶子节点的梯度, 中间梯度不保存
# y3对y1, y2的梯度都为1, y1对x的求导为2 * X, y3对x求导为3 * X * X, 则y3 对 X 的导数为 2 * X + 3 * X * X, 将X=2带入得16
# 如何获取中间节点的梯度, 需要使用retain_grad(), 获知hook函数, 或者自己创建一个list保存梯度
x = torch.tensor([2.], requires_grad=True)
y1 = x * x # 4
y2 = x * x * x # 8
y2.retain_grad() # 保存梯度
y3 = y1 + y2 # 12
y3.backward()
print(y3.grad, y2.grad, y1.grad, x.grad)
# 输出为: None tensor([1.]) None tensor([16.]),
# 如何停止梯度更新那, 假如说停止y2的梯度更新和使用
x = torch.tensor([2.], requires_grad=True)
y1 = x * x # 4
with torch.no_grad(): # 停止跟踪requires_grad
y2 = x * x * x # 8
print(y2.requires_grad) # requires_grad = False
y3 = y1 + y2 # 12
y3.backward()
print(y3.grad, y2.grad, y1.grad, x.grad)
# 输出为: None None None tensor([4.]), 可见y3对X的梯度变为4了, y2没有梯度
# 如何对X的梯度进行改变那
x = torch.tensor([2.], requires_grad=True)
y1 = x * x # 4
y2 = x * x * x # 8
y3 = y1 + y2 # 12
x.grad = torch.tensor([-16.])
y3.backward()
print(y3.grad, y2.grad, y1.grad, x.grad)
# 输出为: None None None tensor([0.]), 可以看到,y3对x的梯度变为0, 因为backward()计算完梯度之后是累加的,可以通过这种形式,进行变化梯度
# (对梯度进行初始化, 要改变的初始化,可以在loss出来后),
# 这也就为什么在实战的时候,我们要进行梯度清零, 我们也可以利用这一变化进行改变梯度
# 如何对中间特征进行改变那, 但是又不希望被autograd记录(即不会影响反向传播),那么可以对tensor.data进行操作
x = torch.tensor([2.], requires_grad=True)
y1 = x * x # 4
y2 = x * x * x # 8
y3 = y1 + y2 # 12
x.data = torch.tensor([1.]) # 梯度还是以x = 2进行计算
y3.backward()
print(y3.grad, y2.grad, y1.grad, x.grad)
# None None None tensor([16.])
print(x.data)
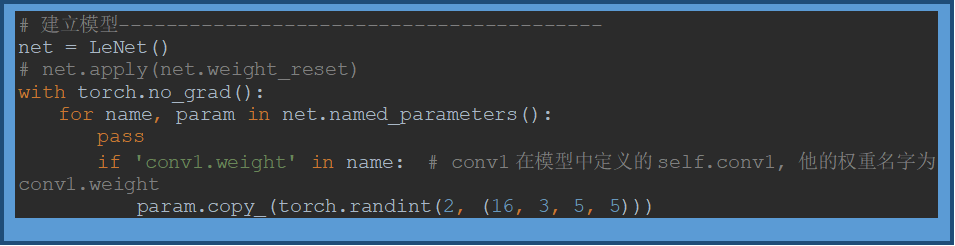
卷积层梯度的重新赋值
参考:【最佳实践】pytorch模型权重的重置与重新赋值_sailist的记录站-CSDN博客_pytorch 给权重赋值

torchnet
参考:python 版本 torchnet 简单使用文档_kdh的专栏-CSDN博客_torchnet
torch.meter(9中方法)
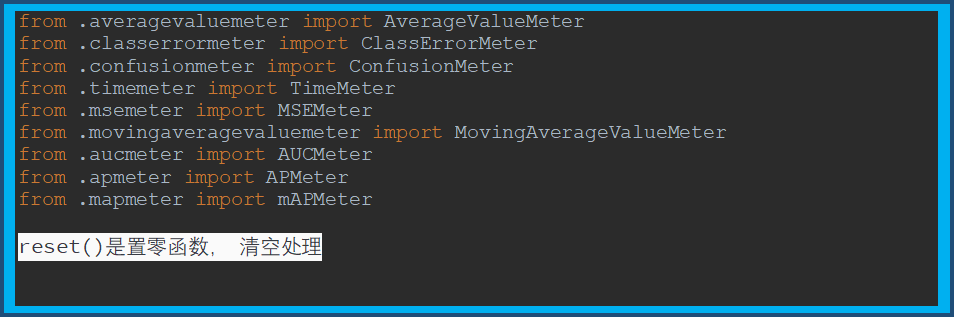

AverageValueMeter(计算平均值)
添加单值数据,进行取平均值及标准差计算。
ClassErrorMeter(topk=[1], accuracy=False)
计算top[i]的准确率
ConfusionMeter (混淆矩阵)
TimeMeter ()
MSEMeter
MovingAverageValueMeter
AUCMeter
APMeter
mAPMeter
Tensorboard的使用
创建代码
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
# creat object
writer = SummaryWriter("logs2")
# add image, show the image in net
image = Image.open("data/test.png")
image = np.array(image)
writer.add_image("img", image, 0, dataformats='HWC')
for i in range(100):
writer.add_scalar("y=2x", 2 * i, i)
writer.close()
# run
# tensorboard --logdir=logs2
# tensorboard --logdir "logs2"
会在和该代码文件同目录下生成的logs文件夹如下:

运行
在pycharm的终端中
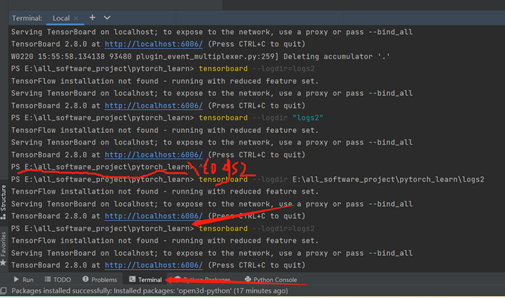
tensorboard --logdir=logs2
tensorboard --logdir "logs2"
tensorboard --logdir logs2
错误1 : DLL load failed while importing pybind:
- Traceback (most recent call last):
- File "S:\1install\python3.8-64\lib\runpy.py", line 194, in _run_module_as_main
- return _run_code(code, main_globals, None,
- File "S:\1install\python3.8-64\lib\runpy.py", line 87, in _run_code
- exec(code, run_globals)
- File "S:\1install\python3.8-64\Scripts\tensorboard.exe\__main__.py", line 7, in <module>
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\main.py", line 42, in run_main
- plugins=default.get_plugins(),
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\default.py", line 105, in get_plugins
- return get_static_plugins() + get_dynamic_plugins()
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\default.py", line 140, in get_dynamic_plugins
- return [
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\default.py", line 141, in <listcomp>
- entry_point.resolve()
- File "S:\1install\python3.8-64\lib\site-packages\pkg_resources\__init__.py", line 2456, in resolve
- module = __import__(self.module_name, fromlist=['__name__'], level=0)
- File "S:\1install\python3.8-64\lib\site-packages\open3d\__init__.py", line 90, in <module>
- from open3d.cpu.pybind import (camera, geometry, io, pipelines, utility, t)
- ImportError: DLL load failed while importing pybind: 找不到指定的模块。
原因由open3d包导致的,没有安好,我把它卸载后,重新安装open3d-python之后问题解决。
此时报出另外一个错误
错误2:48. ValueError: Duplicate plugins for name projector
- Traceback (most recent call last):
- File "S:\1install\python3.8-64\lib\runpy.py", line 194, in _run_module_as_main
- return _run_code(code, main_globals, None,
- File "S:\1install\python3.8-64\lib\runpy.py", line 87, in _run_code
- exec(code, run_globals)
- File "S:\1install\python3.8-64\Scripts\tensorboard.exe\__main__.py", line 7, in <module>
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\main.py", line 46, in run_main
- app.run(tensorboard.main, flags_parser=tensorboard.configure)
- File "S:\1install\python3.8-64\lib\site-packages\absl\app.py", line 312, in run
- _run_main(main, args)
- File "S:\1install\python3.8-64\lib\site-packages\absl\app.py", line 258, in _run_main
- sys.exit(main(argv))
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\program.py", line 276, in main
- return runner(self.flags) or 0
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\program.py", line 292, in _run_serve_subcommand
- server = self._make_server()
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\program.py", line 476, in _make_server
- app = application.TensorBoardWSGIApp(
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\backend\application.py", line 139, in TensorBoardWSGIApp
- return TensorBoardWSGI(
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\backend\application.py", line 252, in __init__
- raise ValueError(
- ValueError: Duplicate plugins for name projector
- PS E:\all_software_project\pytorch_learn> tensorboard --logdir=logs
- TensorFlow installation not found - running with reduced feature set.
- Traceback (most recent call last):
- File "S:\1install\python3.8-64\lib\runpy.py", line 194, in _run_module_as_main
- return _run_code(code, main_globals, None,
- File "S:\1install\python3.8-64\lib\runpy.py", line 87, in _run_code
- exec(code, run_globals)
- File "S:\1install\python3.8-64\Scripts\tensorboard.exe\__main__.py", line 7, in <module>
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\main.py", line 46, in run_main
- app.run(tensorboard.main, flags_parser=tensorboard.configure)
- File "S:\1install\python3.8-64\lib\site-packages\absl\app.py", line 312, in run
- _run_main(main, args)
- File "S:\1install\python3.8-64\lib\site-packages\absl\app.py", line 258, in _run_main
- sys.exit(main(argv))
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\program.py", line 276, in main
- return runner(self.flags) or 0
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\program.py", line 292, in _run_serve_subcommand
- server = self._make_server()
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\program.py", line 476, in _make_server
- app = application.TensorBoardWSGIApp(
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\backend\application.py", line 139, in TensorBoardWSGIApp
- return TensorBoardWSGI(
- File "S:\1install\python3.8-64\lib\site-packages\tensorboard\backend\application.py", line 252, in __init__
- raise ValueError(
- ValueError: Duplicate plugins for name projector
是因为之前一直鼓捣torch和tensorboard好几次,把下面箭头所指info删掉即可。
Transforms的使用
from torchvision import transforms
from PIL import Image
# 如何使用transforms
# 为什么需要tensor数据
img = Image.open("data/test.png")
# 转换为tnesor
img_tensor = transforms.ToTensor()(img)
# 以为ToTensor类中构造了__call__(self, pic)方法,可以将类的实例当作方法,座椅ToTensor()是类实例,然后调用__call__(img)
# normalize 归一化,
img_normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])(img_tensor) # (mean, std)因为图片三个通道,对每一个通道归一化
# 因为 Normalize函数的forward函数的return F.normalize(),返回的是一个函数,所以后面有(img_tensor)
# output[channel] = (input[channel] - mean[channel]) / std[channel]
# resize更改尺寸 输入PIL类型,返回的也是PIL类型, 输入的是tensor类型返回的也是tensor类型
img_resize = transforms.Resize((512, 512))(img)
# 随机裁剪
img_random_crop = transforms.RandomCrop(512, 512)(img)
# 组合处理, 注意[]列表里的方法输入输出的类型要对应.
trans_compose = transforms.Compose([
transforms.Resize(512), # 正方形
transforms.ToTensor()
])(img)
# 不知道返回类型的时候可以print(type())
datasets 、transforms、Dataset、 DataLoader构建自己的数据集合
引用:【Pytorch】笔记三:数据读取机制与图像预处理模块 - 云+社区 - 腾讯云 (tencent.com)
from torchvision import datasets
from torch.utils.data import Dataset
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
from torchvision import transforms
import os
from PIL import Image
# 构建自己的数据集
class RMBDataset(Dataset):
def __init__(self, data, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.data = data #
self.transform = transform
def __getitem__(self, index):
img, label = self.data[index] # 已经是PIL格式
# img = Image.open(img).convert('RGB') # 0~255
if self.transform is not None: # 在这个时候进行预处理,也是单张单张的处理
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data)
# 下载并载入数据
train_data = datasets.CIFAR10("./data", train=True, download=False)
test_data = datasets.CIFAR10("./data", train=False, download=False)
# print(test_data.classes) # 打印标签属性
# image, label = test_data[0]
# print(type(image))
# print(len(train_data))
# # 数据预处理方法
data_transform = {
"train": transforms.Compose([transforms.ToTensor(), transforms.RandomHorizontalFlip(0.5)]), # 随机水平翻转
"test": transforms.Compose([transforms.ToTensor()])
}
## 构建MyDataset实例
train_data = RMBDataset(data=train_data, transform=data_transform["train"])
valid_data = RMBDataset(data=test_data, transform=data_transform["test"])
# 抽取数据的方式, 并做预处理
train_loader = DataLoader(dataset=train_data, batch_size=4, shuffle=True, drop_last=True)
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, drop_last=True)
# 迭代图片
for epoch in range(5):
loss_mean = 0.
correct = 0.
total = 0.
for i, data in enumerate(train_loader):
# forward
inputs, labels = data # 会分别将image, label打包返回
nn.Conv2d卷积操作,构建我的模型
如果自定义卷积的话,使用nn.founction.conv2d()
from typing import Union
import torch.optim as optim
import torch
import torchvision.transforms
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.utils.tensorboard import SummaryWriter
dataset = datasets.CIFAR10("data", train=False, download=False, transform=torchvision.transforms.ToTensor())
data_loader = DataLoader(dataset=dataset, batch_size=64, shuffle=False, drop_last=True)
class my_model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv(x)
return x # 返回的是nn.function.conv2d()
model = my_model()
write = SummaryWriter("logs")
for step, data in enumerate(data_loader): # 数据必须变为tensor格式才能
img, lab = data
outpus = model(img)
outpus = torch.reshape(outpus, (-1, 3, 30, 30))
write.add_images("org", img, step,) # 只能显示channel为3的图片,此外4维度多张图片,要用add_images, 不是add_image
write.add_images("chg", outpus, step)
tensorboard能够获取卷积的图片

如何测试单层效果输出
import torch
from torch.nn import functional
# 第一种方法,使用nn.function
input = torch.tensor([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
[5, 5, 5, 5, 5]], dtype=torch.float32)
kernel = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]], dtype=torch.float32)
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
conv_data = functional.conv2d(input=input, weight=kernel, stride=1, padding=0)
print("第一种方法: 使用nn.function.conv2d的卷积操作\n",conv_data)
# 第二种方法:使用nn.MaxPooling为例子
class my_model2(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.max = torch.nn.MaxPool2d(kernel_size=(3, 3), stride=1, padding=0)
def forward(self, x):
x = self.max(x)
print(x)
return x
net = my_model2()
outdata = net(input)
print("第二种方法: 使用nn.MaxPool2d的池化操纵\n", outdata)
组卷积
# torch.Size([1, 6, 2, 2]) # 特征深度为6,group=3, 每个特征含有(上层下来的out_channel / g)=(6 / 3)两个通道
# torch.Size([3, 2, 2, 2]) # kernel = (这一层的输出out_channel, (out_channel / g), kernel_size, kernel_size)
import torch
from torch.nn import functional
# # 第一种方法,使用nn.function
# input = torch.tensor([[[1, 1, 1],
# [2, 2, 2],
# [3, 3, 3]],
#
# [[1, 1, 1],
# [2, 2, 2],
# [3, 3, 3]],
#
# [[1, 1, 1],
# [2, 2, 2],
# [3, 3, 3]] ], dtype=torch.float32)
#
kernel1 = torch.tensor([[[1, 0],
[0, 0]],
[[0, 0],
[1, 0]],
[[1, 1],
[1, 1]]] ,dtype=torch.float32)
#
# input = torch.reshape(input, (1, 3, 3, 3))
# kernel = torch.reshape(kernel, (3, 1, 2, 2))
# print(kernel)
#
# conv_data = functional.conv2d(input=input, weight=kernel, stride=1, padding=0, groups=3)
# print("第一种方法: 使用nn.function.conv2d的卷积操作\n",conv_data)
# print(conv_data.shape)
# 第一种方法,使用nn.function
input = torch.tensor([[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
[[2, 2, 2],
[2, 2, 2],
[2, 2, 2]],
[[3, 3, 3],
[3, 3, 3],
[3, 3, 3]]], dtype=torch.float32)
kernel2 = torch.tensor([[[[1, 1],
[1, 1]],
[[1, 1],
[1, 1]],
[[1, 1],
[1, 1]]],
[[[1, 1],
[1, 1]],
[[1, 1],
[1, 1]],
[[1, 1],
[1, 1]]]], dtype=torch.float32)
#
input = torch.reshape(input, (1, 3, 3, 3))
kernel1 = torch.reshape(kernel1, (3, 1, 2, 2))
kernel2 = torch.reshape(kernel2, (6, 1, 2, 2))
#
conv_data1 = functional.conv2d(input=input, weight=kernel1, stride=1, padding=0, groups=3)
conv_data2 = functional.conv2d(input=input, weight=kernel2, stride=1, padding=0, groups=3)
# print("第一种方法: 使用nn.function.conv2d的卷积操作\n",conv_data)
# print(conv_data1)
# print(conv_data2)
print(conv_data1.shape)
print(conv_data2.shape)
kernel2 = torch.reshape(kernel2, (3, 2, 2, 2)) # (3, 1, 2, 2))
print(kernel2.shape)
conv_data1 = functional.conv2d(input=conv_data2, weight=kernel2, stride=1, padding=0, groups=3)
print(conv_data1)
对已有的模型修改
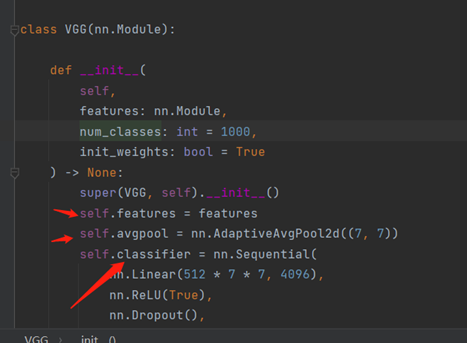
Vgg16的模型结构
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Vgg16模型添加层和修改层
from torchvision.datasets import CIFAR10
from torchvision import transforms
from torchvision.models import vgg16
import torch
import torch.nn
from torch.utils.data import DataLoader
# 加载数据集
train_data = CIFAR10("data", train=True, download=False, transform=transforms.ToTensor())
data, lab = train_data[0]
print(data.shape, lab)
# 迭代数据集
train_loader = DataLoader(dataset=train_data, batch_size=63, shuffle=False)
# 加载模型
vgg16_true = vgg16(pretrained=True, progress=True)
print(vgg16_true) # 打印模型结构
# 在模型的最后一层添加一层新的
vgg16_true.add_module("add_linear", torch.nn.Linear(1000, 10))
print(vgg16_true)
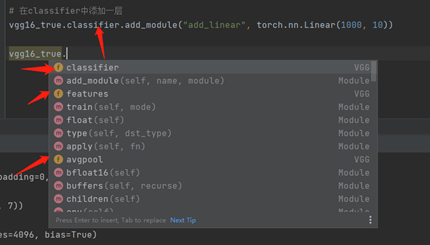
# 在classifier中添加一层
vgg16_true.classifier.add_module("add_linear", torch.nn.Linear(1000, 10))
print(vgg16_true)
# 修该[5]层
vgg16_true.classifier[5] = torch.nn.Dropout(p=0.8, inplace=True)
print(vgg16_true)
模型的保存和修改
import torch
from torchvision.models import vgg16
vgg16_false = vgg16(pretrained=False, progress=True)
# 保存模型的结构+ 模型的参数
torch.save(vgg16_false, "vgg.pth")
# 读取模型和参数
model1 = torch.load("vgg.pth")
print(model1)
# 将模型参数保存成字典的形式(官方推荐)
torch.save(vgg16_false.state_dict(), "vgg2.pth")
# 读取模型参数
model2_parameter = torch.load("vgg2.pth")
# 将模型参数载入模型中
vgg16_false.load_state_dict(model2_parameter)
print(vgg16_false)
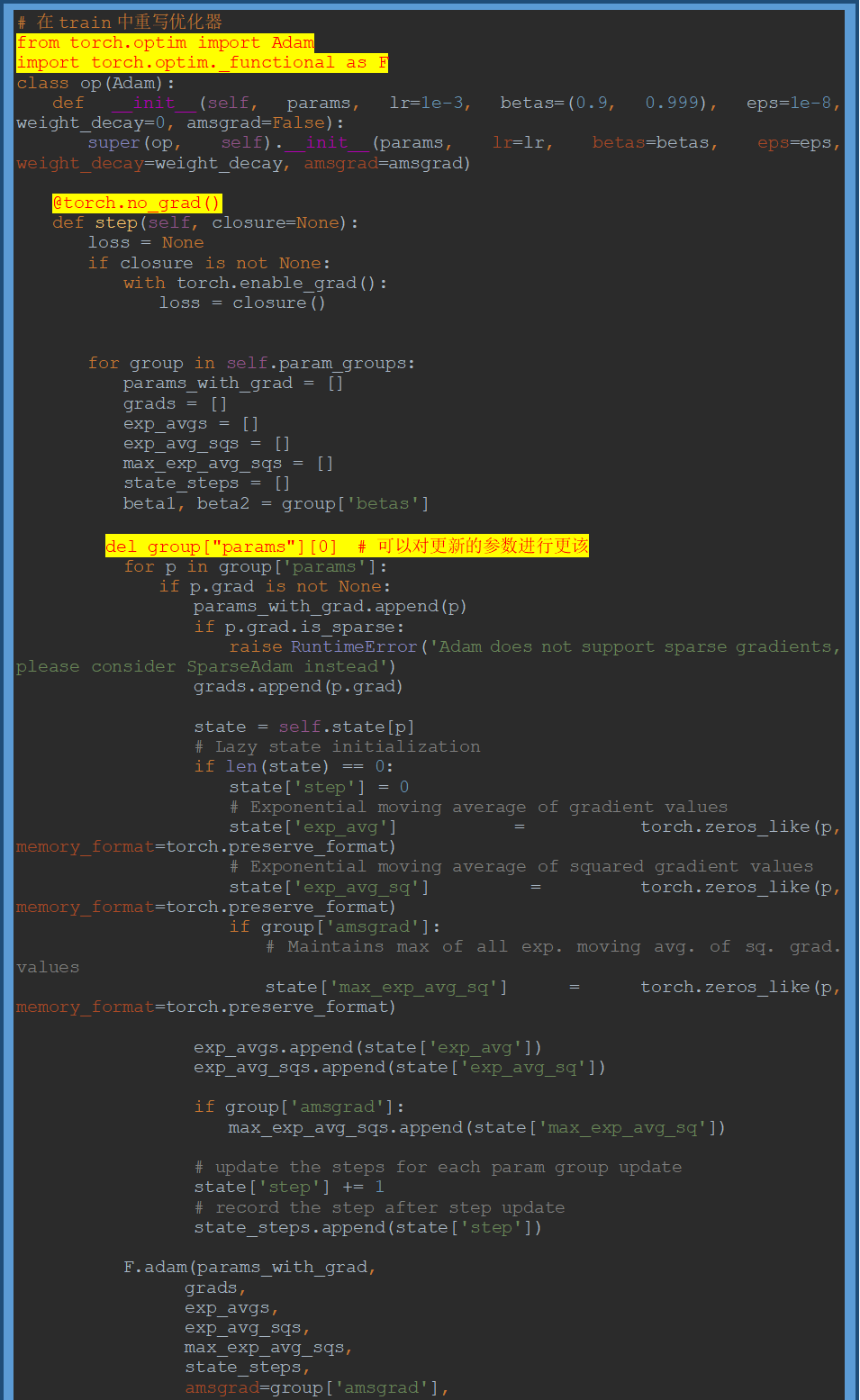
torch.optim中优化器的继承和重写问题
需再读:Pytorch torch.optim优化器个性化使用 - ranjiewen - 博客园 (cnblogs.com)

常见的优化算法介绍
引用:NLPnote/1.2.5调用 pytorch API完成线性回归.md at master · SpringMagnolia/NLPnote (github.com)
1 梯度下降算法(batch gradient descent BGD)
每次迭代都需要把所有样本都送入,这样的好处是每次迭代都顾及了全部的样本,做的是全局最优化,但是有可能达到局部最优。
2 随机梯度下降法 (Stochastic gradient descent SGD)
针对梯度下降算法训练速度过慢的缺点,提出了随机梯度下降算法,随机梯度下降算法算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。
torch中的api为:torch.optim.SGD()
3 小批量梯度下降 (Mini-batch gradient descent MBGD)
SGD相对来说要快很多,但是也有存在问题,由于单个样本的训练可能会带来很多噪声,使得SGD并不是每次迭代都向着整体最优化方向,因此在刚开始训练时可能收敛得很快,但是训练一段时间后就会变得很慢。在此基础上又提出了小批量梯度下降法,它是每次从样本中随机抽取一小批进行训练,而不是一组,这样即保证了效果又保证的速度。
4 动量法
mini-batch SGD算法虽然这种算法能够带来很好的训练速度,但是在到达最优点的时候并不能够总是真正到达最优点,而是在最优点附近徘徊。
另一个缺点就是mini-batch SGD需要我们挑选一个合适的学习率,当我们采用小的学习率的时候,会导致网络在训练的时候收敛太慢;当我们采用大的学习率的时候,会导致在训练过程中优化的幅度跳过函数的范围,也就是可能跳过最优点。我们所希望的仅仅是网络在优化的时候网络的损失函数有一个很好的收敛速度同时又不至于摆动幅度太大。
所以Momentum优化器刚好可以解决我们所面临的问题,它主要是基于梯度的移动指数加权平均,对网络的梯度进行平滑处理的,让梯度的摆动幅度变得更小。 $$ \begin{align*} &gradent = 0.8\nabla w + 0.2 history_gradent &,\nabla w 表示当前一次的梯度\ &w = w - \alpha* gradent &,\alpha表示学习率 \end{align*} $$
(注:t+1的的histroy_gradent 为第t次的gradent)
5 AdaGrad
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新,从而达到自适应学习率的效果 $$ \begin{align*} &gradent = history_gradent + (\nabla w)^2 \ &w = w - \frac{\alpha}{\sqrt{gradent}+\delta} \nabla w ,&\delta为小常数,为了数值稳定大约设置为10^{-7} \end{align*} $$
6 RMSProp
Momentum优化算法中,虽然初步解决了优化中摆动幅度大的问题,为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对参数的梯度使用了平方加权平均数。 $$ \begin{align*} & gradent = 0.8history_gradent + 0.2(\nabla w)^2 \ & w = w - \frac{\alpha}{\sqrt{gradent}+\delta} \nabla w \end{align*} $$
7 Adam
Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用的一种算法,能够达到防止梯度的摆幅多大,同时还能够加开收敛速度 $$ \begin{align*} & 1. 需要初始化梯度的累积量和平方累积量 \ & v_w = 0,s_w = 0 \ & 2. 第 t 轮训练中,我们首先可以计算得到Momentum和RMSProp的参数更新:\ & v_w = 0.8v + 0.2 \nabla w \qquad,Momentum计算的梯度\ & s_w = 0.8s + 0.2(\nabla w)^2 \qquad,RMSProp计算的梯度\ & 3. 对其中的值进行处理后,得到:\ & w = w - \frac{\alpha}{\sqrt{s_w}+\delta} v_w \end{align*} $$ torch中的api为:torch.optim.Adam()
8 效果演示:
