本文主要是基于《推荐系统实践》这本书的读书笔记,还没有实践这些算法。
LFM算法是属于隐含语义模型的算法,不同于基于邻域的推荐算法。
隐含语义模型有:LFM,LDA,Topic Model
这本书里介绍的LFM算法。书中内容介绍的很详细,不过我也是看了一天才看明白的。
开始一直没想明白,隐类的类别是咋来的,后来仔细读才发现是一个设置的参数。
下面开始进入正文:
对于基于邻域的机器学习算法来说,如果要给一个用户推荐商品,那么有两种方式。
一种是基于物品的,另一种是基于用户的。
基于物品的是,从该用户之前的购买商品中,推荐给他相似的商品。
基于用户的是,找出于该用户相似的用户,然后推荐给他相似用户购买的商品。
但是,推荐系统除了这两种之外,还有其他的方式。例如如果知道该用户的兴趣分类,可以给他推荐该类别的商品。
为了实现这一功能,我们需要根据用户的行为数据得到用户对于不同分类的兴趣,以及不同商品的类别归属。
先说类别归属:
对于一本书来说,获取书的类别可以通过它在货架上的类别,比如该一本书被归类为计算机,或者数学。但是一本书也可能属于多个类别,
比如《史记》可以归为历史,也可以归为古典文学。至于《史记》属于哪一类别多,应当根据用户行为来判定更加合理。
也就是说大部分用户读《史记》,是把它作为史料来读,还是古典文学来读。(反正我也不看,觉得没区别)。
一言以蔽之,根据用户行为来划分每件商品的归属类别。该方式还有一个好处是,一个商品可以分别属于不同类别,只是在各个类别中的权重不一样。
再说用户对于各个类别的喜爱程度:
用户对于不同的类别的喜好程度也不同,该算法可以根据用户的行为数据推测出用户对不同的类别的喜好。
下面开始介绍算法的内容:
首先是数据的处理,由于使用的是隐性数据集,只有正样本,例如用户点击了某件商品,没有负样本。
数据处理主要是选出数据集的负样本。
负样本的选取策略主要有以下要点:
(1)正负样本要均衡,基本保证正负样本的比例1:1
(2)负样本需要选择用户没有行为的热门商品。
选取完成之后,计算用户对于某件商品的喜爱程度,例如喜欢是1,不喜欢是0
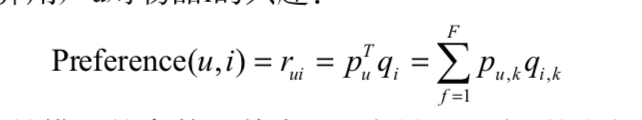
用户u对于商品i的喜爱程度等于,用户u对于类别k的喜爱程度 乘以 商品i在类别k的比重
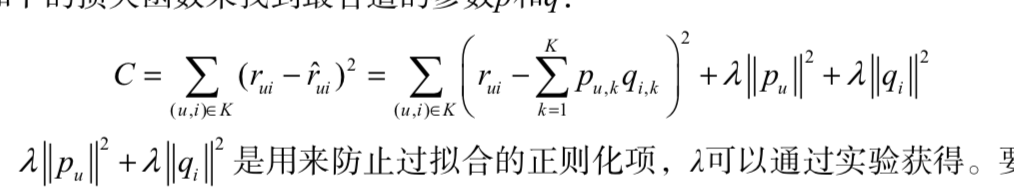
这是代价函数。
然后根据用户行为数据使用随机提督下降法训练。
该模型的参数有:
