根据需求进行人口数据分析:
需求:
- 导入文件,查看原始数据
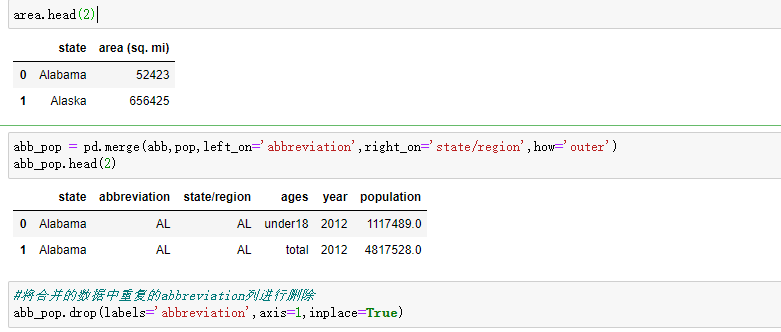
- 将人口数据和各州简称数据进行合并
- 将合并的数据中重复的abbreviation列进行删除
- 查看存在缺失数据的列
- 找到有哪些state/region使得state的值为NaN,进行去重操作
- 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
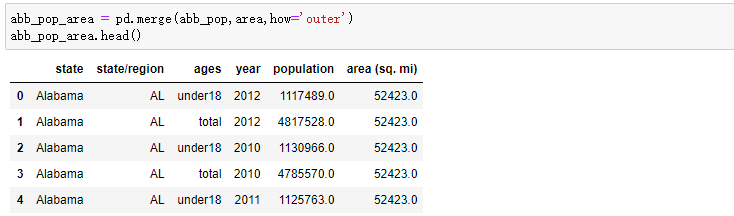
- 合并各州面积数据areas
- 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
- 去除含有缺失数据的行
- 找出2010年的全民人口数据
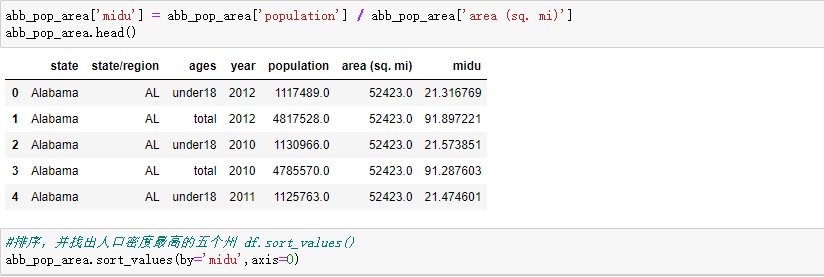
- 计算各州的人口密度
- 排序,并找出人口密度最高的五个州 df.sort_values()
import numpy as np import pandas as pd from pandas import Series,DataFrame
abb = pd.read_csv('./data/state-abbrevs.csv')
pop = pd.read_csv('./data/state-population.csv')
area = pd.read_csv('./data/state-areas.csv')
abb.head(2)
| state | abbreviation | |
|---|---|---|
| 0 | Alabama | AL |
| 1 | Alaska | AK |
pop.head(2)
| state/region | ages | year | population | |
|---|---|---|---|---|
| 0 | AL | under18 | 2012 | 1117489.0 |
| 1 | AL | total | 2012 | 4817528.0 |
#查看存在缺失数据的列 abb_pop.isnull().any(axis=0)
找到有哪些state/region使得state的值为NaN,进行去重操作(哪些简称对应的全程值为空,且对符合要求的简称进行去重)
#1.找出state的空对应的简称数据 #1.1找出state为空对应的行数据 abb_pop['state'].isnull() abb_pop.loc[abb_pop['state'].isnull()]
#2.对符合要求的简称进行去重 #2.1将符合要求的简称取出 abb_pop.loc[abb_pop['state'].isnull()]['state/region'] abb_pop.loc[abb_pop['state'].isnull()]['state/region'].unique()
为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN。 Puerto Rico
state这一列中的空起始可以分为两种类型:PR对应的空,USA对应的空
#1.找出PR简称对应的行数据 abb_pop['state/region'] == 'PR' abb_pop.loc[abb_pop['state/region'] == 'PR'] #2.找出符合要求行数据的行索引 indexs = abb_pop.loc[abb_pop['state/region'] == 'PR'].index #3,将indexs对应的行中的state列的空值批量赋值成Puerto Rico abb_pop.loc[indexs,'state'] = 'Puerto Rico'
abb_pop['state/region'] == 'USA' abb_pop.loc[abb_pop['state/region'] == 'USA'].index indexs = abb_pop.loc[abb_pop['state/region'] == 'USA'].index abb_pop.loc[indexs,'state'] = 'united status'
合并各州面积数据areas
#我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行 #1.将area (sq. mi)列中空值对应的行数据取出 abb_pop_area['area (sq. mi)'].isnull() abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()] indexs = abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()].index
#去除含有缺失数据的行 abb_pop_area.drop(labels=indexs,axis=0,inplace=True)
#找出2010年的全民人口数据
abb_pop_area.query('ages == "total" & year == 2010')
计算各州的人口密度