情况:
ceph 在一次掉盘恢复后, 有 pg 出现 state unknown 的状况. 运行 ceph health detail, 显示:
[root@controller ~]# ceph health detail HEALTH_WARN Reduced data availability: 3 pgs inactive PG_AVAILABILITY Reduced data availability: 3 pgs inactive pg 3.4 is stuck inactive for 97176.554825, current state unknown, last acting [] pg 3.b is stuck inactive for 97176.554825, current state unknown, last acting [] pg 3.1e is stuck inactive for 97176.554825, current state unknown, last acting []
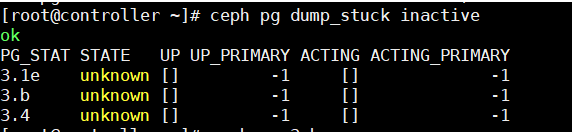
显示这3个 pg 卡住了
运行 pg query, 查看该 pg 的具体信息, 显示:
[root@controller ~]# ceph pg 3.1e query Error ENOENT: i don't have pgid 3.1e
无法找到该 pg id.
运行 pg dump_stuck unclean, 显示:
分析
看来是这几个 pgid 彻底找不到了. 我的 osd pool 有三个, 分别叫 l1 (1副本), l2 (2副本), l3 (3副本).
估计可能是之前写入 1 副本的数据由于硬盘挂掉导致的数据丢失.
既然是1副本, 也不要求数据可靠性了. 并且本身存储的也是一些下载到一半的数据, 也没什么关系
修正
通过阅读 CEPH 官方 PG troubleshooting 文档 , 发现了解决方案:
POOL SIZE = 1
If you have the osd pool default size set to 1, you will only have one copy of the object. OSDs rely on other OSDs to tell them which objects they should have. If a first OSD has a copy of an object and there is no second copy, then no second OSD can tell the first OSD that it should have that copy. For each placement group mapped to the first OSD (see ceph pg dump), you can force the first OSD to notice the placement groups it needs by running:
ceph osd force-create-pg <pgid>
即, 多 osd 副本可以互相通知 pg 信息, 但是单副本就会丢, 为了恢复这个pg, 我们可以强行创建它.
[root@controller ~]# ceph osd force-create-pg 3.1e Error EPERM: This command will recreate a lost (as in data lost) PG with data in it, such that the cluster will give up ever trying to recover the lost data. Do this only if you are certain that all copies of the PG are in fact lost and you are willing to accept that the data is permanently destroyed. Pass --yes-i-really-mean-it to proceed.
运行创建命令, 提示, 运行会永久的丢失该 pg 的数据, 需要加上 --yes-i-really-mean-it.
[root@controller ~]# ceph osd force-create-pg 3.1e --yes-i-really-mean-it pg 3.1e now creating, ok [root@controller ~]# ceph osd force-create-pg 3.b --yes-i-really-mean-it pg 3.b now creating, ok [root@controller ~]# ceph osd force-create-pg 3.4 --yes-i-really-mean-it pg 3.4 now creating, ok
执行成功.
查看新创建的 pg.
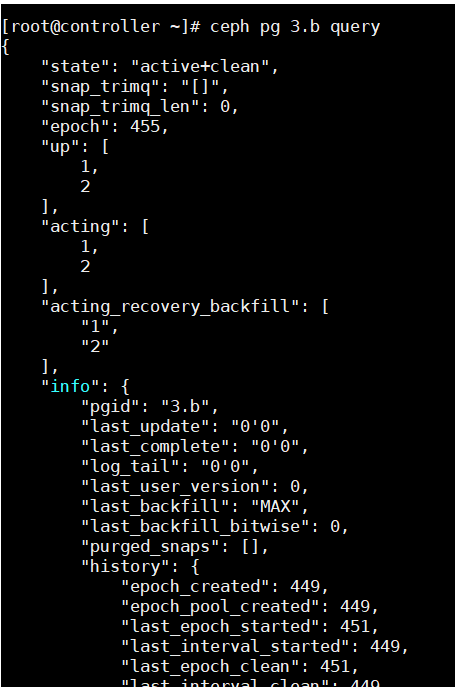
结论
至此, 修复完毕.
后续检查, 1 副本的下载文件夹丢了几个
建议在直到具体是什么问题的情况下才进行这样的操作. 如果是重要的数据, 请不要使用 1 副本, 并做好备份后再进行操作.
如果是2,3 副本情况下的 pg stat unknown, 建议做好心理准备... 很可能就是没了.
如果是其他 pg stuck 的情况, 建议仔细分析再进行操作.
以上
转载于:https://zhuanlan.zhihu.com/p/74323736?from_voters_page=true