对于卷积神经网络的详细介绍和一些总结可以参考以下博文:
https://www.cnblogs.com/pinard/p/6483207.html
https://blog.csdn.net/guoyunfei20/article/details/78055192
这里记录的是结合网上资料的一些总结思考
卷积计算
矩阵的卷积,即两个矩阵对应位置的元素相乘后相加。这里是张量的卷积。
卷积层和池化层的作用
卷积层试图将神经网络中的每一小块进行更加深入地分析从而得到抽象程度更高的特征。池化层可以进一步聚合特征或者抽取更加重要的特征以缩小最后全连接层中节点的个数,从而达到减少整个神经网路中参数的目的。
为什么能进行卷积这种操作?
因为包括图像处理,语言识别以及NLP等任务的数据都具有局部相关性,(图像由元素组成,词组成句子)而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
引发的思考:
卷积的作用?进行局部的感知提取局部的特征。
为什么能进行卷积这种操作?因为深度学习适用数据的局部相关性。
为什么CNN往往是多层的?并行计算快允许其多层,多层才能抽取出全局的以及抽象的特征。
多个卷积核的作用?
多角度的提取局部的特征,使得特征更加充分。
池化的作用?
通过池化能够进一步的减少特征的个数,一定程度上能够防止过拟合,一般用最大池化可能是为了只留下最重要的特征,避免不重要特征带来的影响。Attention有点权重池化的意思。
CNN一层参数的个数:
卷积核的高*宽*个数*通道数+卷积核的个数(这是计算的偏置值的个数)
CNN中的权重共享问题
对于CNN不同的卷积层会定义不同的W,b,只有同一卷积核中的w是共享的,不同的通道卷积核中的w不同,不同大小的卷积核其w自然也不同,多通道同一个卷积核之间的b是共享的,不同卷积核以及不同卷积层的b不同。所以对于CNN而言,同一通道同一卷积核的W一样,同一卷积核即使不同通道的卷积核之间的b也是一样的。
TextCNN部分
对于论文的讲解可参照
https://www.cnblogs.com/bymo/p/9675654.html
实现代码如下:
pool_outputs = [] for filter_h in self.config.filter_hs: with tf.variable_scope('conv_pool_{}'.format(filter_h)): #这里的是否添加偏执值和卷积核的初始化都是需要调节的点 conv=tf.layers.conv2d(x,filters=self.config.num_filters,kernel_size=(filter_h,self.config.vector_size+self.config.pseg_size) ,activation=tf.nn.relu,use_bias=False,kernel_initializer=tf.contrib.layers.xavier_initializer(),name='conve') pooled=tf.nn.max_pool(conv,ksize=[1,self.config.sentence_length-filter_h+1,1,1],strides=[1,1,1,1],padding='VALID',name='pool') pool_outputs.append(pooled) #全连接层操作 print('begin full_connection') with tf.name_scope("full_connection"): h_pool = tf.concat(pool_outputs, 3) # 把3种大小卷积核卷积池化之后的值进行连接 num_filters_total = self.config.num_filters * len(self.config.filter_hs) # 因为随后要经过一个全连接层得到与类别种类相同的输出,而全连接接收的参数是二维的,所以进行维度转换 h_pool_flaten = tf.reshape(h_pool, [-1, num_filters_total]) h_drop = tf.nn.dropout(h_pool_flaten, self.keep_prob) #分类器 W = tf.Variable(tf.truncated_normal([num_filters_total, self.config.num_classes])) self.l2_loss = tf.nn.l2_loss(W) b = tf.Variable(tf.constant(0., shape=[self.config.num_classes]), name="b") self.y_pred = tf.nn.xw_plus_b(h_drop, W, b, name="scores") # wx+b #预测类别 self.pred_label = tf.argmax(tf.nn.softmax(self.y_pred), 1)
其中TextCNN的详细过程原理图如下:
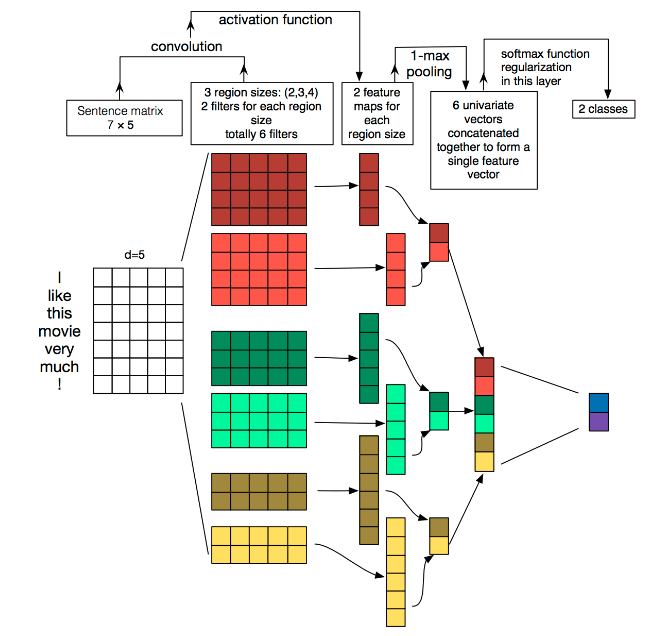
分析:
卷积窗口沿着长度为n的文本一个个滑动,类似于n-gram机制对文本切词,然后和文本中的每个词进行相似度计算,因为后面接了个Max-pooling,因此只会保留和卷积核最相近的词。这就是TextCNN抓取关键词的机制。TextCNN卷积用的是一维卷积,图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要通过设计不同的 filter_size 和 filter 获取不同宽度的视野。TextCNN设置不同高度的卷积核同时卷积核的宽度和词向量的维度相同,这就相当于不同的ngram。
在 TextCNN中使用的是Max-pooling,只保留最有用的表征,但是有些具体任务中也可保留多个,<<A Convolutional Neural Network for Modelling Sentences >>中使用了 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息。
缺点:
CNN网络受感受野的限制只能提取局部特征,一般是通过加深网络层以获得全局信息,但是即使加深网络层,相比于lstm也无法很好的获得长时依赖,要想获得更长时的依赖可以使用膨胀卷积神经网络(空洞网络)。
对于池化层,他能够很大程度减少参数,能够提高速度,防止过拟合等,但是它同样会造成不可逆转的信息丢失,会丢失对于NLP而言很重要的位置信息。一定程度上可以选用k-max pooling。
对于短文本的分类而言,抽取的这些关键词可能就有很好的区分性,因此TextCNN更适用于短文本分类。
由于它无法获得全局信息可以在输入部分和双向LSTM的输出结果进行拼接,从而获得全局信息。
NLP方面CNN比不上RNN,为什么还是选取了CNN,文本分词后一般会有粒度和语义的矛盾,粒度太大,分词效果不好,粒度太小,语义丢失,而CNN核心过程是卷积,我们可以通过CNN的卷积将分完词之后的词的语义结合在一起,从而获得更加准确的词向量。