一.测试用例数据与代码分离
1.从之前的脚本来看,我还是把数据写在了脚本中,这样脚本的通用性很差。全局的数据其实可以从数据库、文本文件、Excel中直接读取。
2.代码和用户数据分离:

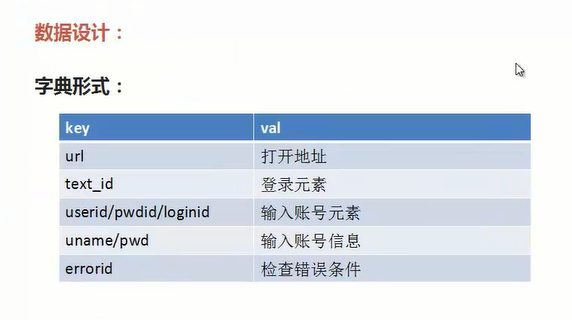
3.数据设计--以字典的形式
from selenium import webdriver import time from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support.ui import WebDriverWait def openBrower(): #配置浏览器 webdriver_handle = webdriver.Firefox() return webdriver_handle def openUrl(handle,url): #打开url handle.get(url) def get_ele_times(driver,times,func): return WebDriverWait(driver,times).until(func) #等待方法 def findElement(driver,arg): ''' arg must be dict 1.login:登录入口 2.user_xpath:用户名 3.pwd_xpath:密码 4.login_xpath:登录按钮 return useEle,pwdEle,loginEle ''' ele_login = get_ele_times(driver,10,lambda driver:driver.find_element_by_xpath(arg['login'])) ele_login.click() useEle = driver.find_element_by_xpath(arg['user_xpath']) pwdEle = driver.find_element_by_xpath(arg['pwd_xpath']) loginEle = driver.find_element_by_xpath(arg['login_xpath']) return useEle,pwdEle,loginEle def sendVals(eletuple,arg): ''' ele tuple account:uname,pwd ''' listkey = ['uname','pwd'] i = 0 for key in listkey: eletuple[i].send_keys('') eletuple[i].clear() eletuple[i].send_keys(arg[key]) i+=1 eletuple[2].click() def checkResult(driver,text): try: driver.find_element_by_link_text(test) print ("ACCOUNT AND PWD ERROR!") except: print ("ACCOUNT AND PWD RIGHT!") def login_test(ele_dict): driver = openBrower() openUrl(driver,ele_dict['url']) driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值 sendVals(ele_tuple,ele_dict) checkResult(driver,ele_dict['errorid']) driver.find_element_by_link_text('退出').click() if __name__ == '__main__': url = 'http://www.maiziedu.com/' #将数据都放入字典中 account = 'XXX' pwd = 'maizi123456' ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]', 'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]', 'errorid':'该账号不正确','uname':account,'pwd':pwd} login_test(ele_dict)
这样把用户名和密码也加入字典中是不合理的,所以要把用户名和密码抽出来单独用一个list存放:
def login_test(ele_dict,user_list): driver = openBrower() openUrl(driver,ele_dict['url']) driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值 for arg in user_list: sendVals(ele_tuple,arg) checkResult(driver,ele_dict['errorid']) if __name__ == '__main__': url = 'http://www.maiziedu.com/' account = 'XXX' pwd = 'maizi123456' ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]', 'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]', 'errorid':'该账号不正确'} user_list = [{'uname':account,'pwd':pwd}] login_test(ele_dict,user_list)
二.从文件导入数据
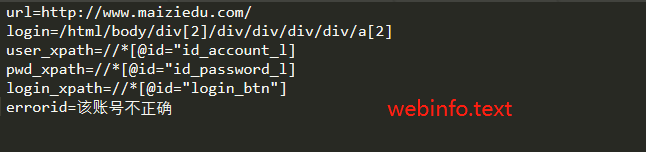

1.webinfo.py
#coding:UTF-8 import codecs def get_webinfo(path): web_info={} #定义一个空的字典 #config=open(path) config = codecs.open(path,'r','utf-8') #打开一个路径为path的txt文件 如果打印的话 会出现txt文件里的所有内容 for line in config: #一行一行的遍历txt文件中的内容 result = [ele.strip() for ele in line.split('=')] ''' 列表解析以'='符号为分隔,将遍历的一行的内容放在一个数组里,每一个result的形式都是[ , ] 可用来调试查看是否通过“=”分离开数据 print(result) ''' web_info.update(dict([result])) return web_info def get_userinfo(path): user_info = [] config = codecs.open(path,'r','utf-8') for line in config: user_dict = {} result = [ele.strip() for ele in line.split(' ')] for r in result: account = [ele.strip() for ele in r.split('=')] user_dict.update(dict([account])) user_info.append(user_dict) return user_info if __name__ == '__main__': webinfo = get_webinfo(r'C:Users胡廷祥Desktopwebinfo.txt') for key in info: print(key,info[key]) userinfo = get_userinfo(r'C:Users胡廷祥Desktopuserinfo.txt') for l in userinfo: print(l) print(userinfo)
2.login.py
from selenium import webdriver import time from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support.ui import WebDriverWait from webinfo import get_webinfo from webinfo import get_userinfo def openBrower(): #配置浏览器 webdriver_handle = webdriver.Firefox() return webdriver_handle def openUrl(handle,url): #打开url handle.get(url) def get_ele_times(driver,times,func): return WebDriverWait(driver,times).until(func) #等待方法 def findElement(driver,arg): ''' arg must be dict 1.login:登录入口 2.user_xpath:用户名 3.pwd_xpath:密码 4.login_xpath:登录按钮 return useEle,pwdEle,loginEle ''' ele_login = get_ele_times(driver,10,lambda driver:driver.find_element_by_xpath(arg['login'])) ele_login.click() useEle = driver.find_element_by_xpath(arg['user_xpath']) pwdEle = driver.find_element_by_xpath(arg['pwd_xpath']) loginEle = driver.find_element_by_xpath(arg['login_xpath']) return useEle,pwdEle,loginEle def sendVals(eletuple,arg): ''' ele tuple account:uname,pwd ''' listkey = ['uname','pwd'] i = 0 for key in listkey: eletuple[i].send_keys('') eletuple[i].clear() eletuple[i].send_keys(arg[key]) i+=1 eletuple[2].click() def checkResult(driver,text): try: driver.find_element_by_link_text(test) print ("ACCOUNT AND PWD ERROR!") except: print ("ACCOUNT AND PWD RIGHT!") def login_test(ele_dict,user_list): driver = openBrower() openUrl(driver,ele_dict['url']) driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值 for arg in user_list: sendVals(ele_tuple,arg) checkResult(driver,ele_dict['errorid']) if __name__ == '__main__': url = 'http://www.maiziedu.com/' account = 'XXX' pwd = 'maizi123456' ''' ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]', 'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]', 'errorid':'该账号不正确'} user_list = [{'uname':account,'pwd':pwd}] ''' ele_dict = get_webinfo(r'C:UsersXXXDesktopwebinfo.txt') user_list = get_userinfo(r'C:UsersXXXDesktopuserinfo.txt') #file webinfo/userinfo ele_dict = get_webinfo(path) user_list = get_userinfo(path) login_test(ele_dict,user_list)