对于二分查找的bug
1)对于代码:
//当l和r都很大时,容易溢出 int mid=(l+r)/2;
解决:
//改用减法替代加法 int mid=l+(r-l)/2;
2)可用递归或迭代的方式实现:
递归比迭代在性能上略差,但差异仅是常数级别的。
二分搜索树
二分搜索树的优势:
- 高效
- 不仅可查找数据;还可以高效地插入,删除数据 - 动态维护数据
- 可以方便地回答很多数据之间的关系问题: min, max, floor, ceil, rank, select
二分搜索树 Binary Search Tree概念(天然地包含了递归结构):
- 二叉树
- 每个节点的键值大于左孩子;每个节点的键值小于右孩子;
- 以左右孩子为根的子树仍为二分搜索树
- 不一定是完全二叉树(使用数组不经济,使用节点(用指针或引用,在java中就将结点封装成类,在类中定义自身类型的左右孩子节点))
二分搜索树的遍历:
- 深度优先遍历:前中后序遍历
- 层序遍历(广度优先遍历):要用到队列
二分搜索树的删除(最复杂的操作):
- 删除最大值、最小值;
- 删除任意节点:删除只有左孩子或者只有右孩子的节点;删除既有左孩子又有右孩子的节点(选左孩子中最大值或者右孩子中的最小值)。
- 删除二分搜索树的任意一个节点 时间复杂度 O(logn)
二分搜索树的顺序性:
- minimum , maximum,
- successor , predecessor,(对于树中存在的元素)
- floor , ceil,(对于树中不存在的元素)
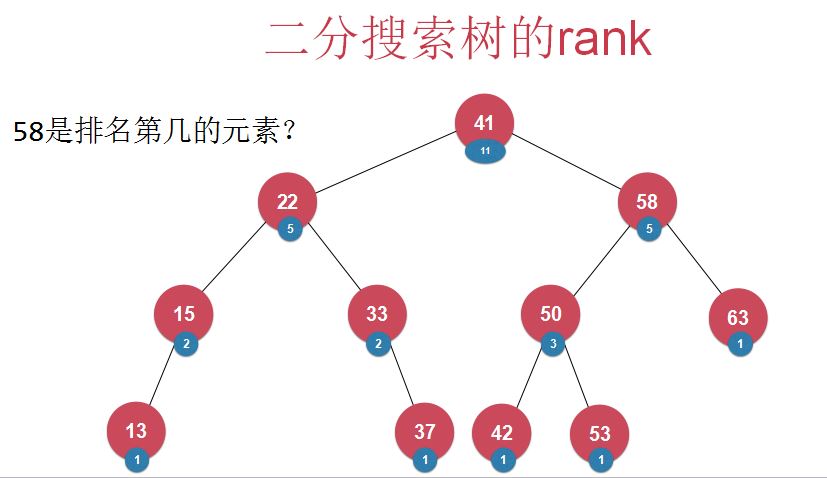
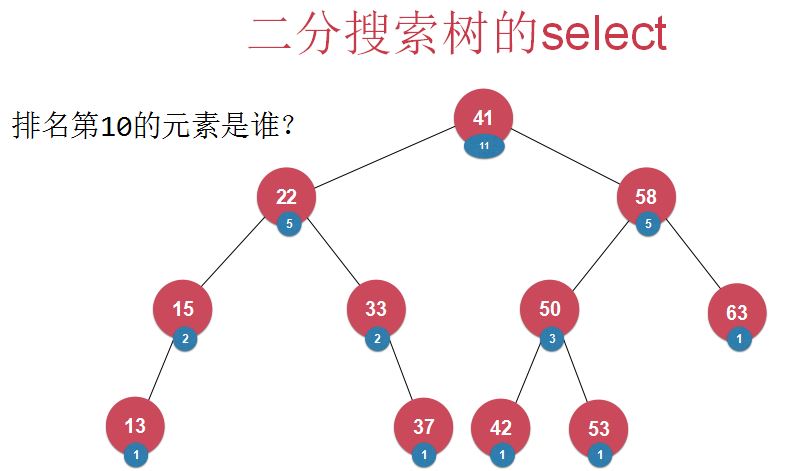
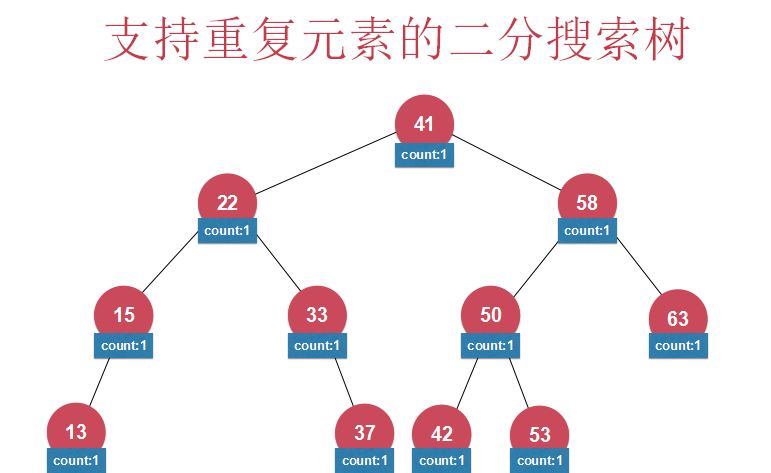
- rank , select(元素中增加以该元素为根的树的元素个数)(难点在于怎么在insert和delete操作时维护好新增的元素个数这一数据)
二分搜索数的局限性:
同样的数据,可以对应不同的二分搜索树。二分搜索树可能退化成链表。
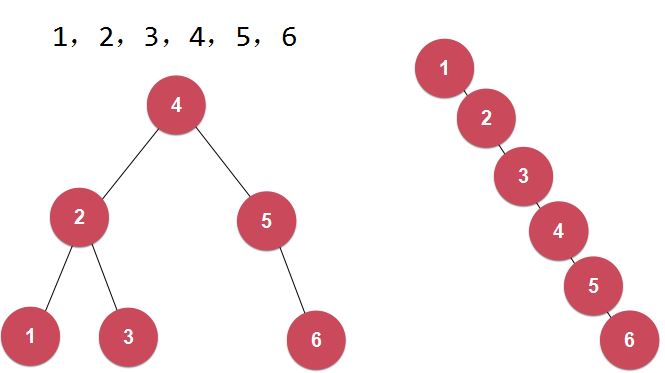
改进:平衡二叉树(概念)——红黑树(平衡二叉树的一种实现)
平衡二叉树和堆的结合:Treap。
其他的树形结构:
递归法——天然的树形性质
并查集 Union Find
非常高效的处理:
连接问题 Connectivity Problem。
- 网络中节点间的连接状态 网络是个抽象的概念:用户之间形成的网络。
- 数学中的集合类实现
对于一组数据,主要支持两个动作:
- union( p , q )
- find( p ) //找它的根
用来回答一个问题
- isConnected( p , q )
1)并查集的一种实现思路:
Quick Find:


Quick Find方式中,查找操作非常快,可是在“并”这个操作中操作将十分的慢。
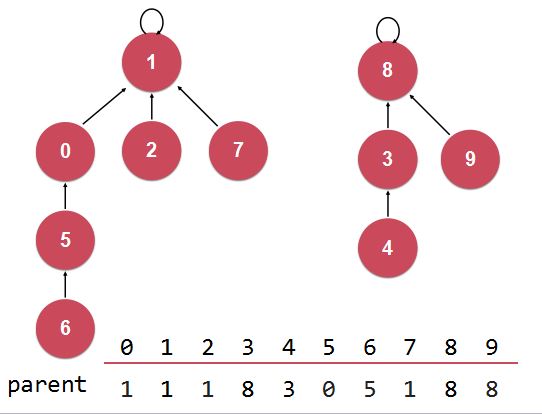
2)另一种实现思路(常规思路:Quick Union):
将每一个元素,看做是一个节点。在节点上建立连接关系,使当前节点指向其父结点。
使得并和查操作更快:
并:合并时,查到要合并的两个元素的根,让两个根连接在一起;
查:查找两个节点是否连接时,只需要查找到其根结点即可。

优化(针对Union操作):
1)基于size的优化。
size数组表示根节点为i的树的元素数量。
每次合并的标准为size数组的大小。
确定一下每个集合的大小,使得每次合并时都是数量小的那组根结点连接到数量多的那组根结点上,以减少树的层数。
2)基于rank的优化
在并查集中采用rank的数组来表示树的层数(树的高度)。
rank[i] 表示根节点为i的树的高度。
每次合并的标准为rank数组的大小。
对于要把4和2连接起来。
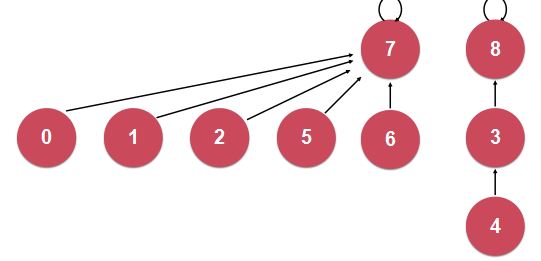
结果是这样呢:(树的层数为4)

还是这样:(树的层数为3)
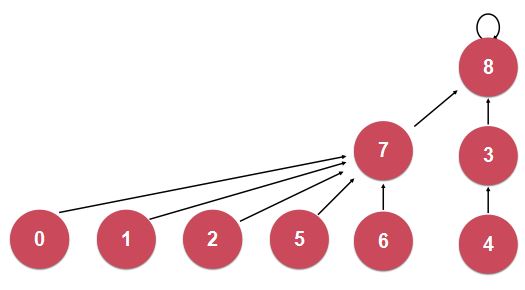
在该优化代码中,当一个小层次的树连接到一个高层次的树时,不需要维护rank数组,而是在两个数的高度相等时连接需要维护一下rank数组,即将被连接的树的根节点的rank中对应元素值加一。
3)另一种优化方式(针对find操作):路径压缩 Path Compression
理论上,在并查集中每个父节点可以连接无数个孩子节点(一层),路径压缩就是在find操作的过程中跳了两步。(本来是跳一步)
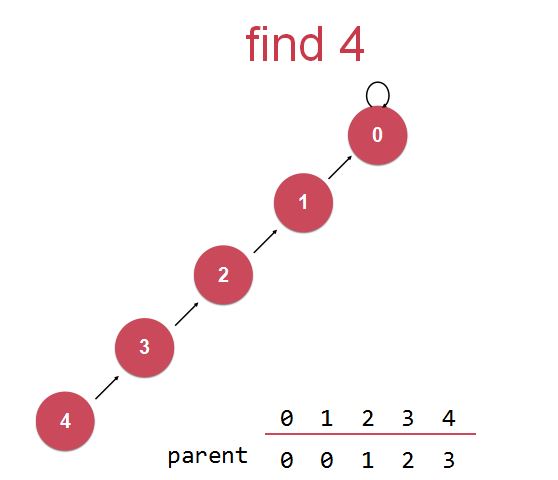
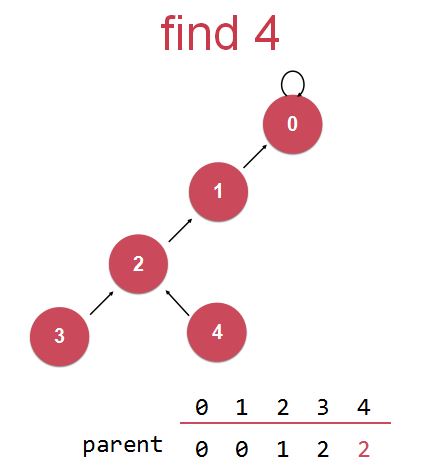
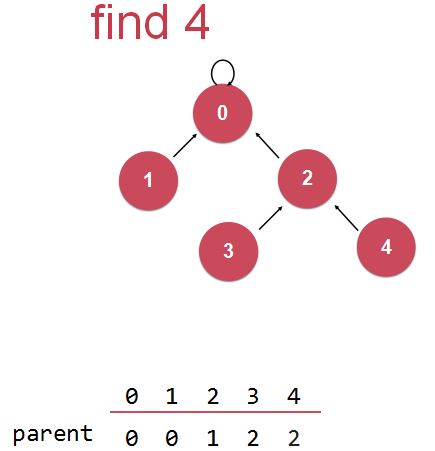
(以下图第一个节点find操作为例)
在查找某个节点的根结点时,(当前考察对象为节点4)若查到当前节点的父结点和当前节点不一样,即当前节点不是根结点,那么就压缩一步,把这个节点的位置往上挪一个(也就是让它去连接它父亲的父亲);
此时,当前节点(节点4)连接到了它原来父亲节点的父亲节点(即节点2),考察此当前节点(节点4)的当前父亲节点(节点2)是不是根节点(即考察它的父亲节点是不是自身),(当前考察对象转变为节点2,即原来节点“路径压缩”后的父节点)若不是,则再次进行路径压缩,让该节点的父结点去连接它父结点的父结点,然后再次进行考察对象转移。
实现路径压缩。

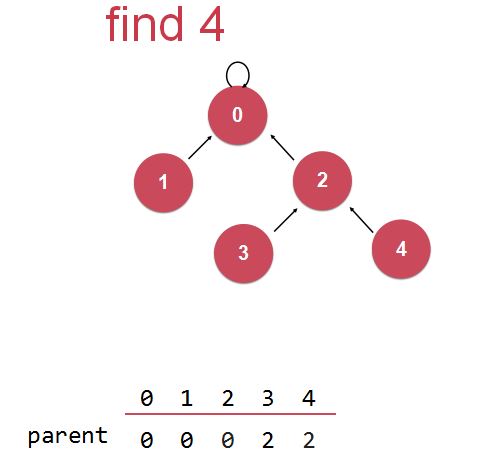
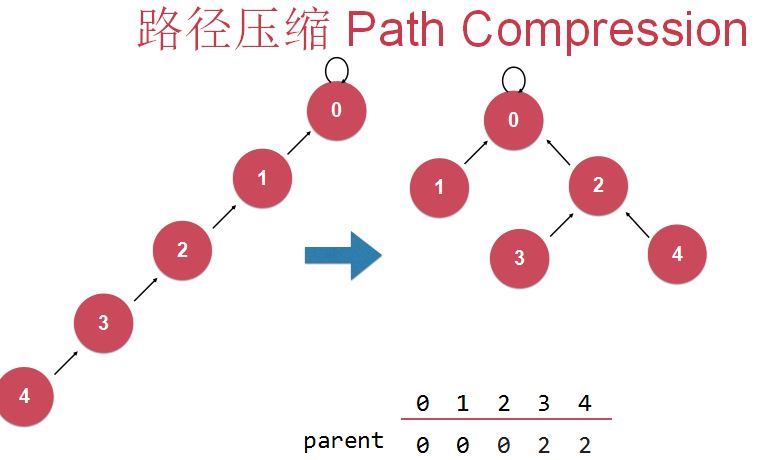
最优的路径压缩:(递归的路径压缩)

并查集的操作,时间复杂度近乎是O(1)的。
图论 Graph Theory
组成:
- 节点 ( Vertex )
- 边 ( Edge )
图的分类:
- 无向图(Undirected Graph)
- 有向图(Directed Graph)
无向图是一种特殊的有向图
- 无权图(Unweighted Graph)
- 有权图(Weighted Graph)
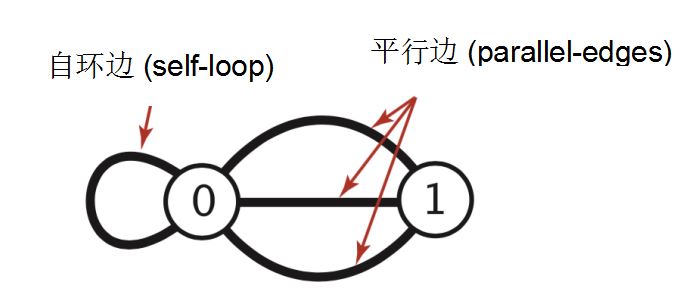
简单图 ( Simple Graph):没有自环边和平行边的图。
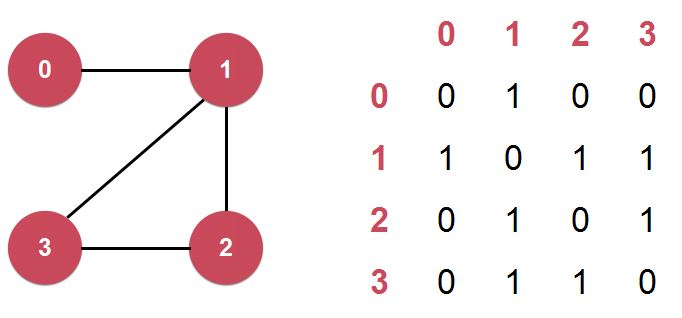
图的表示:
1)邻接矩阵(Adjacency Matrix):
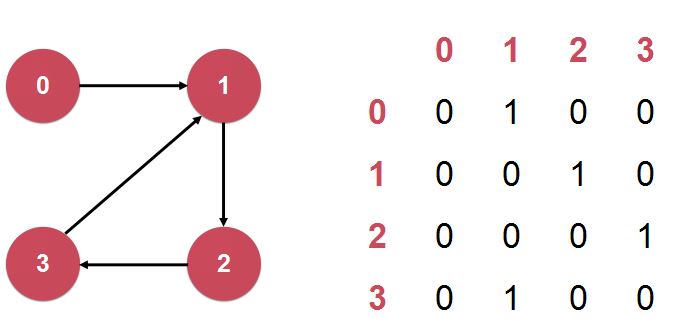
2)邻接表 (Adjacency Lists):

-
邻接表适合表示稀疏图 (Sparse Graph)
-
邻接矩阵适合表示稠密图 (Dense Graph)

平行边是邻接表的一个缺点。使用邻接表来处理平行边需要的成本比较高。通常情况下,在使用邻接表的图结构中,加入一条边的操作一般不去管是不是有平行边,也就是允许它有平行边。如果我们真的需要进行平行边的处理,我们要做的是在这个结构所有的边都加进来以后,对整个图的边做一次整体上的平行边处理。
遍历邻边 - 图算法中最常见的操作:
邻接表具有优势。
图的遍历:
深度优先遍历——求一个图的连通分量:
- 和树的深度优先遍历相似。由于图可能存在环路,所以不会出现像树中那样遍历不下去的情况,所以需要使用一个visited【】数组进行一下标记。
- 可以获得两点之间的路径。(并非最短)
- 使用一个from【】数组,可求出两点之间的路径的路线
- 深度优先遍历的时间复杂度:
- 稀疏图(邻接表): O( V + E )
- 稠密图(邻接矩阵):O( V^2 )
深度优先遍历算法对有向图依然有效。
广度优先遍历——使用队列(跟树中相似):
- 和树的深度优先遍历相似。由于图可能存在环路,所以不会出现像树中那样遍历不下去的情况,所以需要使用一个visited【】数组进行一下标记。
- 按跟第一个被遍历的节点的距离为标准作为遍历顺序。
- 广度优先遍历求出了无权图的最短路径
- 使用一个from【】数组,可求出最短路径的路线
- 图的广度优先遍历 - 复杂度:
- 稀疏图(邻接表): O( V + E )
- 稠密图(邻接矩阵):O( V^2 )
最小生成树
带权图 Weighted Graph:
邻接矩阵 (Adjacency Matrix) :为了和邻接表相统一,这里的边也使用封装起来的类,原来为0的位置现在应置为null

邻接表 (Adjacency Lists) :需将边封装成一个类

最小生成树问题 Minimum Span Tree:
- 针对带权无向图
- 针对连通图
目标:
- 找 V-1 条边
- 连接V个顶点
- 总权值最小
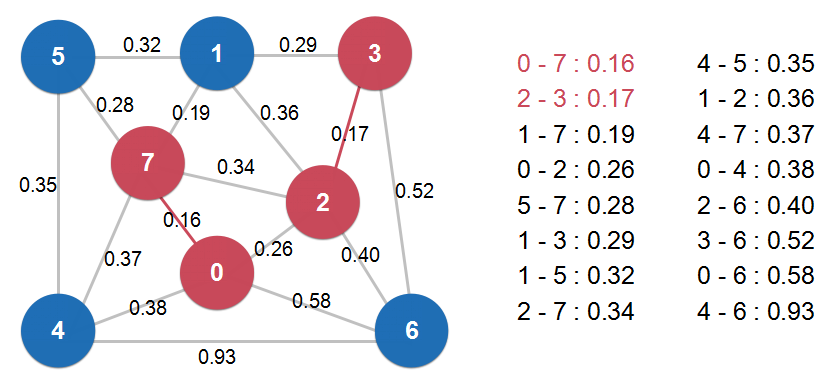
切分定理 Cut Property:
把图中的结点分为两部分,成为一个切分(Cut)。
如果一个边的两个端点,属于切分(Cut)不同的两边,这个边称为横切边(Crossing Edge)。(即图中一头连接蓝色节点,一头连接红色节点的边)
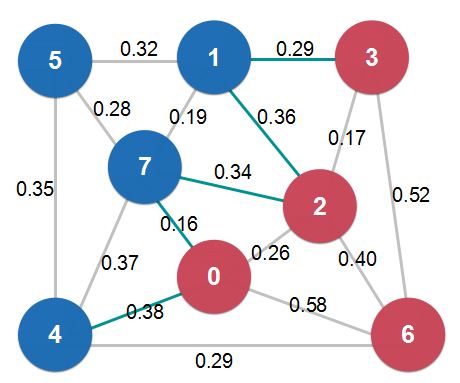
切分定理: 给定任意切分,横切边中权值最小的边必然属于最小生成树。(即上图中,所有横切边中权值最小的是0.16这条边,这条边必然属于最小生成树)
由于是任意切分,那么我们就可以从第一个节点开始,一点一点地扩散,直至求出整张图的最小生成树。
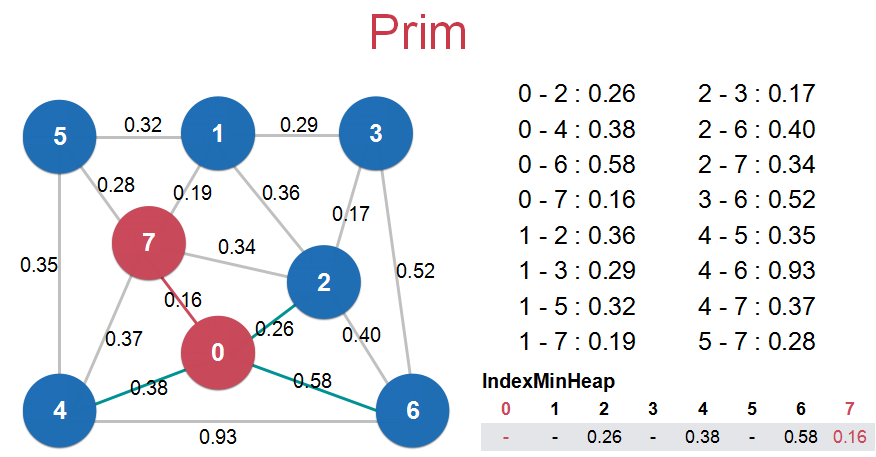
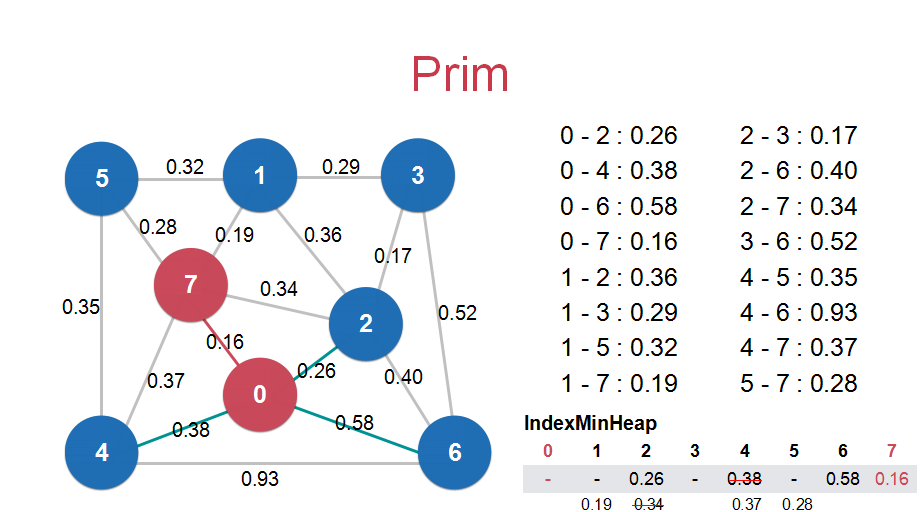
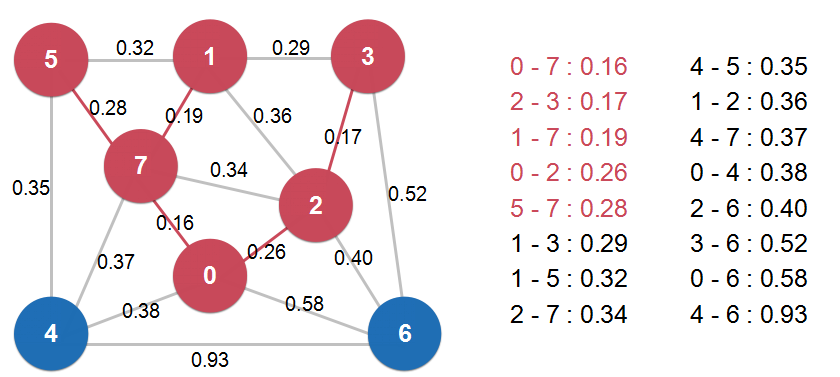
第一个最小生成树算法——Lazy Prim算法
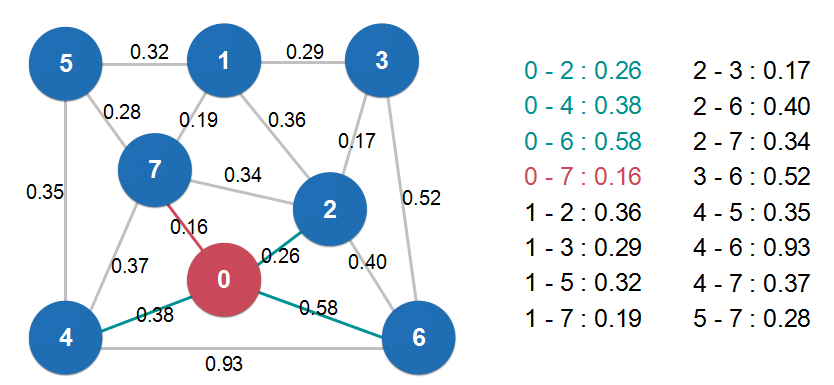


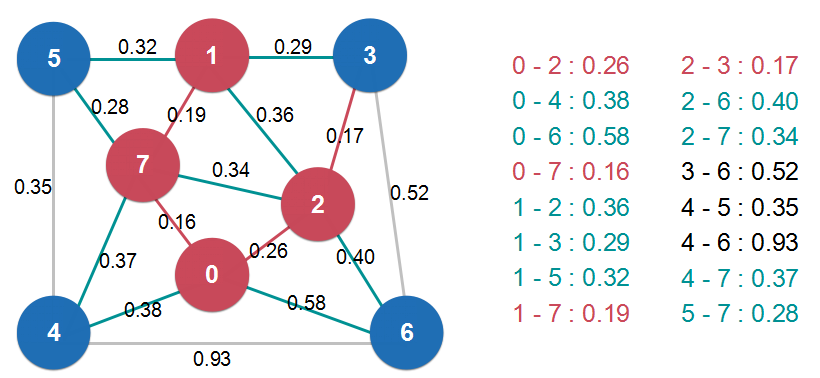


Lazy Prim算法懒就懒在将新的节点纳入到最小生成树中时,不能删掉内部非最短路径的边(如图4中的1和2,2和7之间的边),需要在下次寻找最小横切边时搜索到再删除。
在搜索最短横切边时,可以使用最小索引堆进行选择。
Lazy Prim 的时间复杂度 O(ElogE)。
Lazy Prim算法的优化——Prim算法,时间复杂度达到O(ElogV)。
增加了对Lazy Prim算法懒的改正。
当新加入的节点和剩下节点的连接路径中出现比现有连接路径权重小的路径时,将小的路径权重填入,舍弃大的路径权重。
另一种最小生成树算法——Kruskal 算法
如果每次我们都找最短的那条边,那么是不是这条边就是组成最小生成树的一条边呢?答案是只要不构成环,就是。
关键在于我们怎么确定会不会生成环?用并查集!



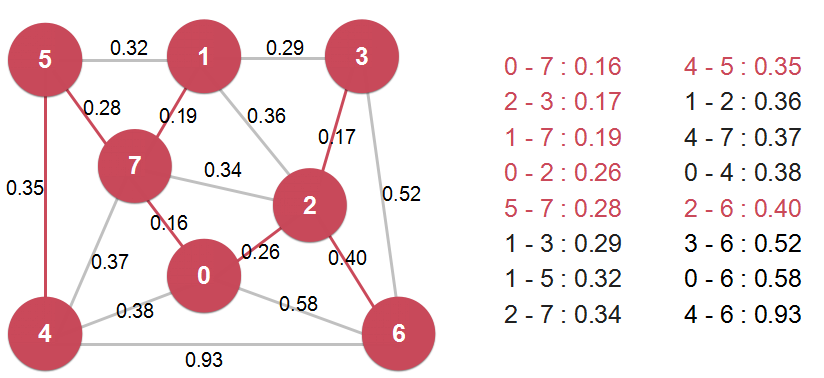
Kruskal算法的时间复杂度 O(ElogE)。
最小生成树问题 Minimum Span Tree:
- Lazy Prim O( ElogE )
- Prim O( ElogV )
- Kruskal O( ElogE )
如果横切边有相等的边,根据算法的具体实现,每次选择一个边 。此时,图存在多个最小生成树。
另一种生成最小生成树的思想——Vyssotsky’s Algorithm
将边逐渐地添加到生成树中 一旦形成环,删除环中权值最大的边。
最短路径问题 Shortest Path
广度优先遍历求最短路径:
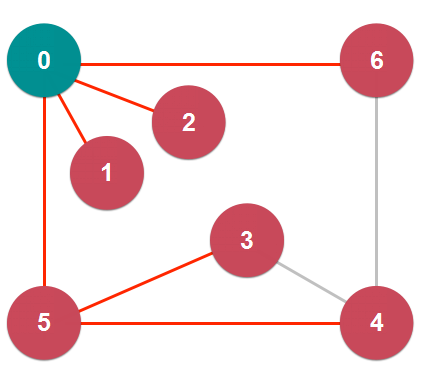
- 形成的是最短路径树 Shortest Path Tree
- 解决了单源最短路径 Single Source Shortest Path
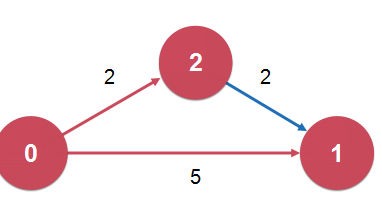
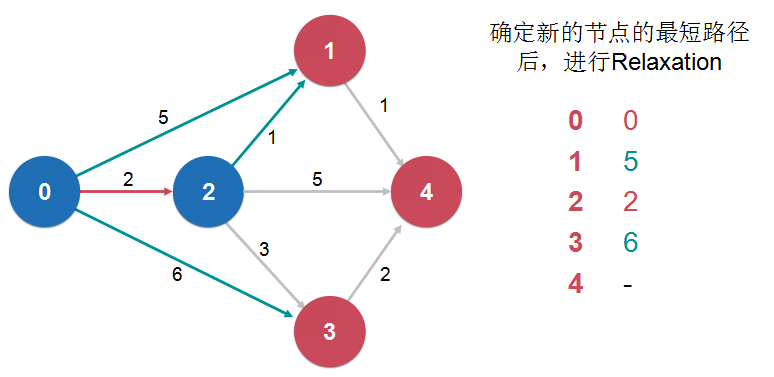
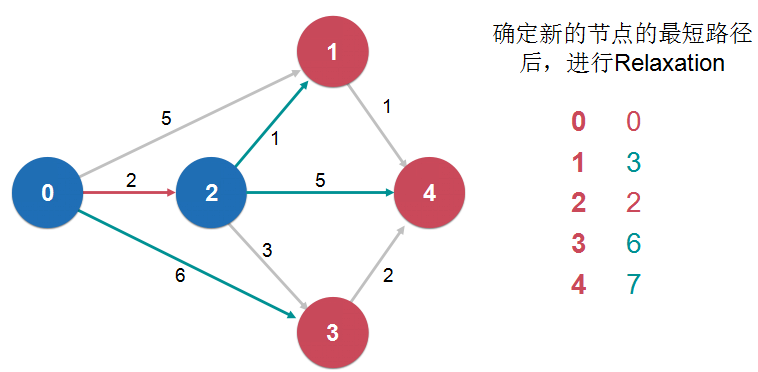
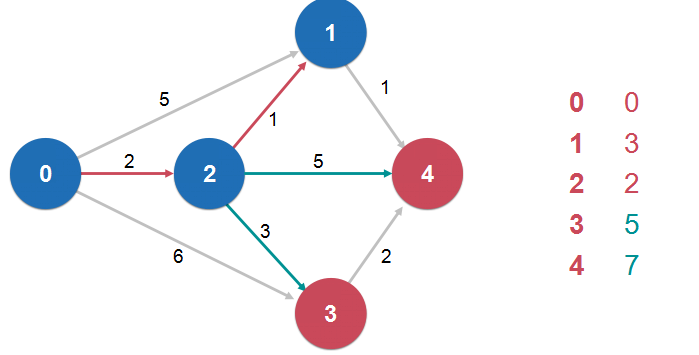
我们每经过一个节点,就要考虑一下,经过这个节点到达某个节点是不是比之前不经过这个节点到达某个节点的路径要短。如果更短的话,那么就要更新一下这个最短路径信息。
这个操作叫做“松弛操作 Relaxation”
松弛操作是最短路径求解的核心
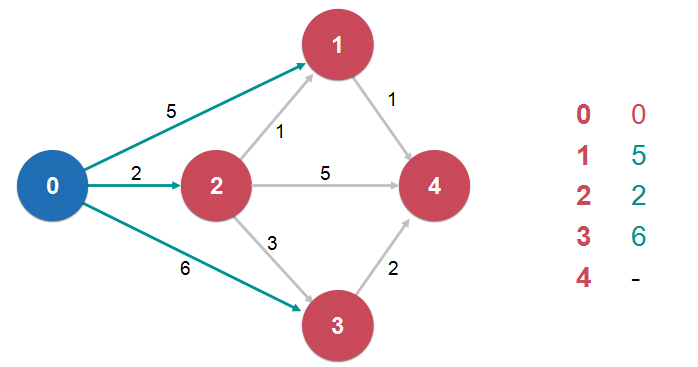
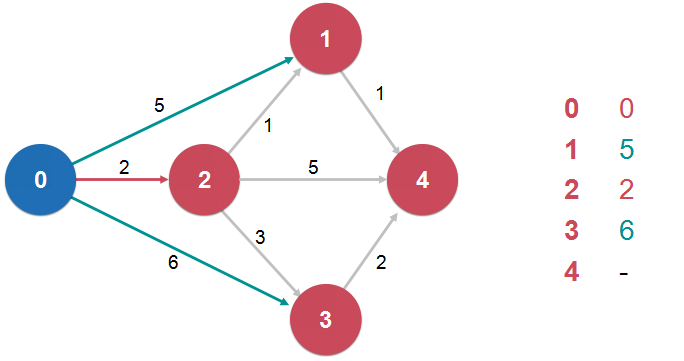
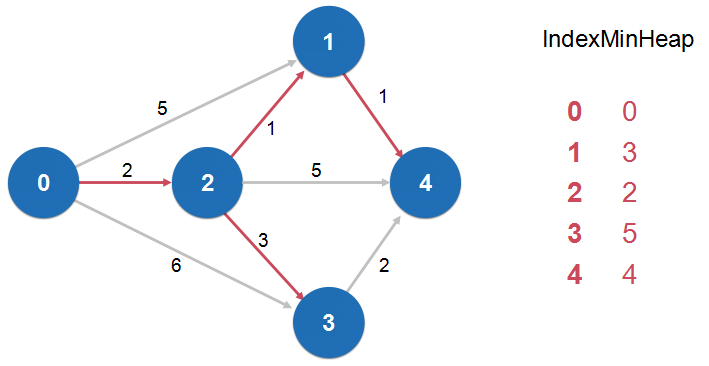
dijkstra 单源最短路径算法:
- 前提:图中不能有负权边(局限性)
- 复杂度 O( E log(V) )

处理负权边:
拥有负权环的图, 没有最短路径。
Bellman-Ford 单源最短路径算法:(同样依赖松弛操作)
- 前提:图中可以有负权边,不能有负权环
- Bellman-Ford可以判断图中是否有负权环
- 复杂度 O( EV )
如果一个图没有负权环, 从一点到另外一点的最短路径,最多经过所有的V个顶线,有V-1条边 否则,存在顶点经过了两次,既存在负权环

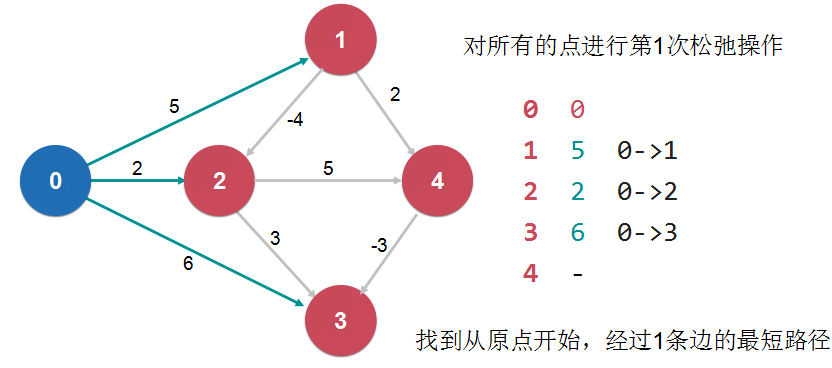
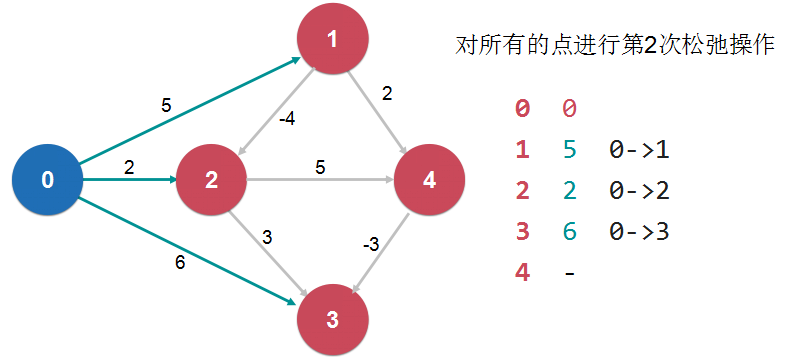
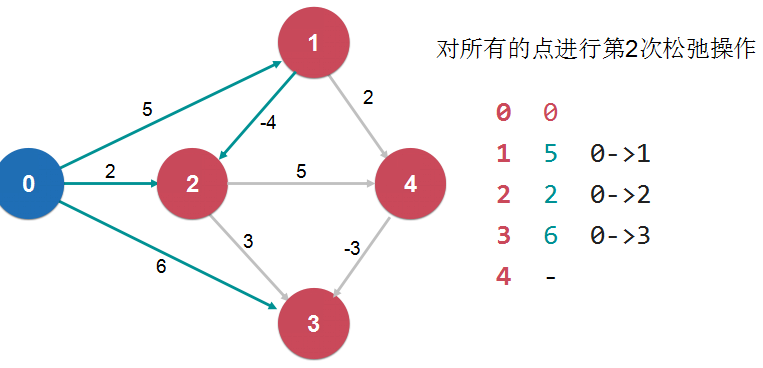

对一个点的一次松弛操作,就是找到经过这个点的另外一条路径,多一条边,权值更小。 如果一个图没有负权环,从一点到另外一点的最短路径,最多经过所有的V个顶线,有V-1条边 对所有的点进行V-1次松弛操作。
对所有的点进行V-1次松弛操作,理论上就找到了从源点到其他所有点的最短路径。 如果还可以继续松弛,所说原图中有负权环。
所有对最短路径算法:
Floyed算法,处理无负权环的图 O( V^3 )