一. 概念。
1. 相关关键字。
CUDA(Compute Unified Device Architecture)。
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。
2. CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。。
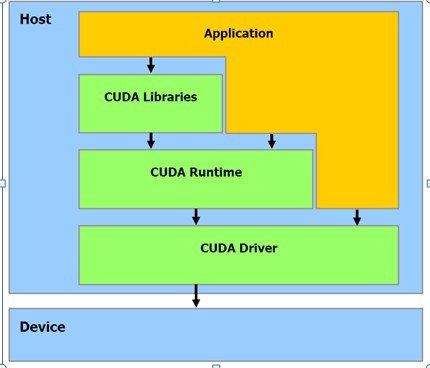
3. 从CUDA体系结构的组成来说,包含了三个部分:开发库、运行期环境和驱动。开发库是基于CUDA技术所提供的应用开发库。运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。驱动部分基本上可以理解为是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。
4. 应用领域例如游戏、高清视频、卫星成像等数据规模庞大的场景。
二. 初探。
1. CUDA框架
CUDA 是 NVIDIA 的 GPGPU 模型,它使用 C 语言为基础,可以直接以大多数人熟悉的 C 语言,写出在显示芯片上执行的程序,而不需要去学习特定的显示芯片的指令或是特殊的结构。
在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 "kernel"。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
2. Cpu与Gpu的各自领域
CPU和GPU各有所长。一般而言,CPU擅长处理不规则数据结构和不可预测的存取模式,以及递归算法、分支密集型代码和单线程程序。这类程序任务拥有复杂的指令调度、循环、分支、逻辑判断以及执行等步骤。例如,操作系统、文字处理、交互性应用的除错、通用计算、系统控制和虚拟化技术等系统软件和通用应用程序等等。而GPU擅于处理规则数据结构和可预测存取模式。例如,光影处理、3D 坐标变换、油气勘探、金融分析、医疗成像、有限元、基因分析和地理信息系统以及科学计算等方面的应用。显示芯片通常具有更大的内存带宽。具有更大量的执行单元。和高阶 CPU 相比,显卡的价格较为低廉。
目前设计GPU+CPU架构平台的指导思想是:让CPU的更多资源用于缓存,GPU的更多资源用于数据计算。把两者放在一起,不但可以减小在传输带宽上的花销,还可以让CPU和GPU这两个PC中运算速度最快的部件互为帮衬。其原因是,CPU中的运算器通常只有几个ALU,而GPU中的ALU则比CPU的数目多很多。另外,CPU中高速缓存相对比较多,而GPU中的高速缓存则比CPU少很多。必要的时候,CPU可以帮助GPU分担一部分软件渲染工作,另一方面GPU可以使用主流编程语言来处理通用计算问题。这就相当于CPU多了一个强大的浮点运算部件,而GPU多了一个像素处理单元。
从微架构上看,CPU和GPU看起来完全不是按照相同的设计思路设计的,当代CPU的微架构是按照兼顾“指令并行执行”和“数据并行运算”的思路而设计,就是要兼顾程序执行和数据运算的并行性、通用性以及它们的平衡性。CPU的微架构偏重于程序执行的效率,不会一味追求某种运算极致速度而牺牲程序执行的效率。GPU的微架构就是面向适合于矩阵类型的数值计算而设计的,大量重复设计的计算单元,这类计算可以分成众多独立的数值计算——大量数值运算的线程,而且数据之间没有像程序执行的那种逻辑关联性。
从主频上来看,GPU执行每个数值计算的速度并没有比CPU快,从目前主流CPU和GPU的主频就可以看出了,CPU的主频都超过了1GHz,2GHz,甚至3GHz,而GPU的主频最高还不到1GHz,主流的也就500~600MHz。要知道1GHz = 1000MHz。所以GPU在执行少量线程的数值计算时并不能超过CPU。
从每个时钟周期执行的指令数来看,这个方面,CPU和GPU无法比较,因为GPU大多数指令都是面向数值计算的,少量的控制指令也无法被操作系统和软件直接使用。如果比较数据指令的IPC,GPU显然要高过CPU,因为并行的原因。但是,如果比较控制指令的IPC,自然是CPU的要高的多。原因很简单,CPU着重的是指令执行的并行性。
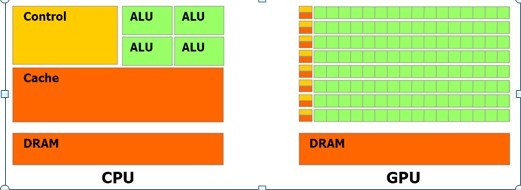
GPU 的设计能使更多晶体管用于数据处理,而非数据缓存和流控制。
更具体地说,GPU 专用于解决可表示为数据并行计算的问题——在许多数据元素上并行执行的程序,具有极高的计算密度(数学运算与存储器运算的比率)。由于所有数据元素都执行相同的程序,因此对精密流控制的要求不高;由于在许多数据元素上运行,且具有较高的计算密度,因而可通过计算隐藏存储器访问延迟,而不必使用较大的数据缓存。
3. Gpu的线程层次结构
执行内核的每个线程都会被分配一个独特的线程 ID。线程的索引及其线程 ID 有着直接的关系:对于一维块来说,两者是相同的;对于大小为 (Dx,Dy) 的二维块来说,索引为 (x,y) 的线程的ID 是(x + yDx);对于大小为(Dx,Dy, Dz)的三维块来说,索引为(x, y, z)的线程的ID 是(x + yDx + ZDxDy)。
一个块内的线程可彼此协作,通过一些共享存储器来共享数据,并同步其执行来协调存储器访问。一个线程块最多可以包含 512 个线程。但一个内核可能由多个大小相同的线程块执行,因而线程总数应等于每个块的线程数乘以块的数量。这些块将组织为一个一维或二维线程块网格。
线程块需要独立执行:必须能够以任意顺序执行、能够并行或顺序执行。这种独立性需求允许跨任意数量的核心安排线程块,从而使程序员能够编写出可伸缩的代码。
4. 存储器层次结构
CUDA 线程可在执行过程中访问多个存储器空间的数据。每个线程都有一个私有的本地存储器。每个线程块都有一个共享存储器,该存储器对于块内的所有线程都是可见的,并且与块具有相同的生命周期。最终,所有线程都可访问相同的全局存储器。
此外还有两个只读的存储器空间,可由所有线程访问,这两个空间是固定存储器空间和纹理存储器空间。
5. 软件栈
CUDA 软件栈包含多个层,设备驱动程序、应用程序编程接口(API)及其运行时、两个较高级别的通用数学库,即 CUFFT 和 CUBLAS。