1. Flume Channel
Channels是events在agent上进行的存储库。Source添加events,Sink移除events。
Channel 是位于Source 和Sink 之间的缓冲区。因此,Channel 允许Source 和Sink 运作在不同的速率上。Channel 是Flume 保证数据不丢失的关键(当然,这是在正确配置的情况下)。Source 写入数据到一个或多个Channel 中,再由一个或多个Sink 读取。Sink只能从一个Channel 读取数据,而多个Sink 可以从相同的Channel 读取以获得更好的性能。Channel 有事务语义,允许Flume 为写进Channel 的数据提供明确的保证。
位于Source 和Sink 之间作为缓冲区的Channel 操作,有几个优点。Channel 允许Source在同一Channel 上操作,以拥有自己的线程模型而不必担心Sink 从Channel 读取数据,反之亦然。位于Source 和Sink 之间的缓冲区也允许它们工作在不同的速率,因为写操作发生在缓冲区的尾部,读取发生在缓冲区的头部。这也使得Flume Agent 能处理Source“高峰小时”的负载,即使Sink 无法立即读取Channel。
Channel 允许多个Source 和Sink 在它们上面进行操作。Channel 本质上是事务性的。每次从Channel 中写入和读取数据,都在事务的上下文中发生。只有当写事务被提交,事务中的事件才可以被任意Sink 读取。同样,如果一个Sink 已经成功读取了一个事件,该事件对于其他Sink 是不可用的,除非该Sink 回滚事务。
在大多数实时应用程序临时负载出现峰值是很常见的,Flume 被设计用来处理这些情况。事件将缓冲到Channel 直到Sink 移除它们,让Agent 处理传入负载的变化。每个Agent可以处理多少额外的数据取决于Channel 的容量。分配Channel 的容量应根据预期的所有写入Channel 的Source 最大峰值负载和所有Sink 的读取速度的总和。这个设计还允许Source 和Sink 对失败具备重试逻辑。对于失败,Source 可以尝试再次写入Channel,Sink 可以尝试再次读取。
事务工作流
在第2 章“Flume Channel 中的事务”一节中讨论过,Flume Channel 是事务性的。事务本质上是原子性写入Channel 的批量事件。事件要么全部批量地存在在Channel 要么全都不存在。事务提供了重要的保证,它能知晓什么时候事件被写入Channel 或从Channel 移除。例如,Sink 可以从Channel 中读取一个事件,试图把它写到HDFS 但是失败了,在这种情况下,事件应该回滚到Channel,这样就可以被这个可用的Sink 或另外一个Sink 读取并写到HDFS。
只有在事务提交后事件才被移除能保证事件不会丢失,即使写失败一次,此时Sink 可以回滚该事务。事务可以有一个或多个事件,但由于性能的原因总是推荐每个事务有相当大数量的事件。
批量写入Channel 是很重要的,尤其是持久的Channel。甚至Agent 或机器重启的情况下,持久Channel 也能保证没有数据丢失,所以它们必须在事务提交期间刷新和同步所有缓冲事件的数据到磁盘,每批量发生一次。同步到磁盘是昂贵和耗时的操作,应该只在相当大部分的数据写入页面缓存时完成。另外,同步到磁盘需要时间,包括在实际同步之前重要的系统调用的消耗,这一切都随着时间的推移而增加。每一个这样的批量也表示为一个事务,使得事务对于性能以及可靠性越来越重要。
每个Channel 可以有多个Source 和Sink,分别写入Channel 和从Channel 读取。Source和Sink 关于事务以稍微不同的方式工作。Source 不直接处理事务;相反,Source 的Channel 处理器代表它处理事务。Channel 处理器处理事务的工作方式与Sink 几乎是相同的(除了Sink 是从Channel 读取数据,而Channel 处理器是将数据放入Channel)。
Sink 用Channel 发起事务是通过调用Channel 的getTransaction 方法,这个方法返回Transaction 的一个实例。然后Sink 开始调用事务对象,它允许Channel 设置任何事务所需的内部状态。通常,这包括队列的创建,以用来暂时托管事件直到事务完成。
事务一旦开始,Sink 在Channel 上调用take 方法(Channel 处理器的情况下是put 方法),直到Sink 准备提交事务。一旦Sink 读取一个事件,该事件将不会被用于相同的或另一个Sink,除非事务回滚。
由于性能的原因Sink(和Channel 处理器)通常会将一些事件批量放入一个事务中。一旦Sink 完成了它的批量任务,Sink 就对事务调用commit 方法。一旦sink-side 事务(只进行读取的事务)被提交,该事务中的事件被Channel 标记为删除,也不能被其他Sink再次使用。一旦source-side 事务(Channel 处理器所拥有的事务)被提交,Channel 中的事件就是安全的。另外,这意味着只有当Sink 读取完事件并提交,这些事件才能从Channel 中被删除。
我们需要注意的是,如果Sink 读取完一个事件,该事件对于其他Sink 就是不可用的,除非该Sink 回滚事务,导致该Sink 中的事务能被再次读取。这是专门设计用来当多个Sink 操作相同的Channel 时,避免重复的。Channel 的每一个事件实际上可以读取和提交一次,之后事件从Channel 中移除。
取决于所使用的特定的Channel,即使机器或JVM 重启,Channel 中的事件也可能是可用的。Sink 写所有的事件到任意它所支持的地方也有可能失败,因此必须重试。在这种情况下,Sink 在事务中使用rollback 方法回滚整个事务。一旦事务被回滚到Sink 这边,Channel 重新存储事件到Channel 并使它们对Sink 可用以用来读取。在source-side 事务回滚的情况下,就好像这个事务从来没有发生过,在事务期间写入的事件从来没有写入Channel。当回滚是由超时或其他失败引起的,这时事件可能已经提交到下一阶段的Channel 中,回滚可能会造成重复。
当事务提交或回滚之后,通过调用close 方法关闭事务,来清理事务使用的任何资源。图4-1 说明了事务的工作流。

单个事务不能同时写入和读取事件。这保证了Source 只能往Channel 中放入事件,Sink只能从Channel 中取走事件。
flime内置的几个Channel:
1.1 Memory Channel(内存Channels)
events存储在配置最大大小的内存队列中。对于流量较高和由于agent故障而准备丢失数据的流程来说,这是一个理想的选择。


agent a1示例:

1.2 JDBC Channel
events存储在持久化存储库中(其背后是一个数据库)。JDBC channel目前支持嵌入式Derby。这是一个持续的channel,对于可恢复性非常重要的流程来说是理想的选择。

agent a1示例:

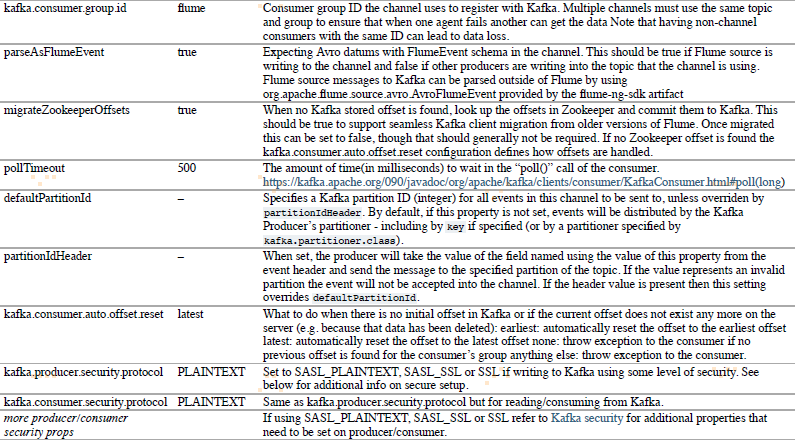
1.3 Kafka Channel
events存储在Kafka集群中。Kafka提供高可用性和高可靠性,所以当agent或者kafka broker 崩溃时,events能马上被其他sinks可用。
Kafka channel可以被多个场景使用:
- Flume source和sink - 它为events提供可靠和高可用的channel
- Flume source和interceptor,但是没sink - 它允许写Flume evnets到Kafka topic
- Flume sink,但是没source - 这是一种低延迟,容错的方式从Kafka发送events到Flume sinks 例如 HDFS, HBase或者Solr

agent a1示例:

Security and Kafka Channel:
省略...
TLS and Kafka Channel:
省略...
Kerberos and Kafka Channel:
省略...
上述详情可以查看官网:
http://flume.apache.org/FlumeUserGuide.html#kafka-channel
或者flume1.8 使用指南学习感悟(一)、flume1.8 使用指南学习感悟(二)关于Kafka部分
http://www.cnblogs.com/swordfall/p/8095213.html 4.6.8 Kafka Source
http://www.cnblogs.com/swordfall/p/8157766.html 1.11 Kafka Sink
1.4 File Channel
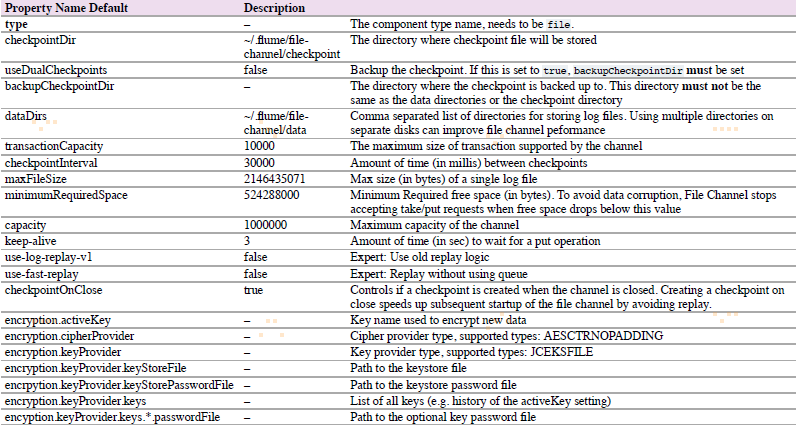
agent a1示例:

1.5 Spillable Memory Channel
events存储在内存队列和磁盘中。该channel目前正在试验中,不要求在生产环境中使用。

agent a1示例:

让内存channel队列使用失效,功能类似file channel:

让磁盘溢出使用失效,功能类似in-memory channel:
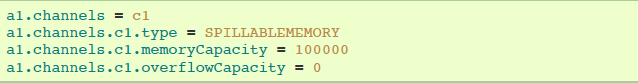
1.6 Pseudo Transaction Channel
注意:Pseudo Transaction Channel只用于单元测试,不用于生产环境使用。

1.7 Custom Channel
自定义channel是你实现Channel接口。当Flume agent启动时,一个自定义channel类和它依赖项必须包含在agent的classpath。

agent a1的示例:

2. Flume Channel Selectors
如果类型没有指定,那么默认“replicating”。
2.1 Replicating Channel Selector(default) (复制channel选择器)

agent a1和它的source 为 r1:

在上面的配置中,c3是一个可选性的channel。写event到c3出错将会被忽略。因为c1和c2没有标记为可选,写到这些channels失败将会导致事务提交失败。
2.2 Multiplexing Channel Selector (多路复用Channel选择器)

agent a1和它的source为r1:

2.3 Custom Channel Selector (自定义Channel选择器)
一个自定义channel选择器(selector)是实现ChannelSelector的接口。当Flume agent启动时,一个自定义channel selector类和它依赖项必须包含在agent的classpath。

agent a1和它的source为r1:

参考资料: