一、内部表与外部表的比较
Hive表概念和关系型数据库表概念差不多。在Hive里表会和HDFS的一个目录相对应,这个目录会存放表的数据。目录默认是/usr/hive/warehouse/。
比如你在hadoop09数据库创建了emp表,那么HDFS中就会有/user/hive/warehouse/hadoop09.db/emp这个目录来存放表里的数据。
管理表:管理表又被称之为内部表,他只管理着数据生命周期,当我们删除这张表时,元数据和存储的业务数据都会被删除,也就是说HDFS所对应的表目录应该被删除。
管理表有一个缺点:就是不方便和其他工作共享数据。
例如,假设我们有一份由pig或者其他工具创建并且主要由这一工具使用的数据,同时我们还想使用hive在这份数据上执行查询,可是没有给予hive对数据的所有权,我们可以创建一个外部表指向这份数据而不需要对其具有所有权。
内部表与外部表还有些区别:有些HiveQL语法结构并不适用于外部表。
对于管理表,用户还可以对一张存折的表进行表结构赋值(而不会复制数据):
create external table if not exists mydb.employees3 like mydb.employees location '/path/to/data';
这里,如果语句中省略掉external关键字而且源表是外部表的话,那么生成的新表也将是外部表。如果遇见中省略掉external关键字而且源表是管理表的话,那么生成的新表也将是管理表。但是,如果语句中包含有external关键字而且源表是管理表的话,那么生成的新表将是外部表。
二、分区表
2.1、为什么要创建分区表
1、select查询中会扫描整个表内容,会消耗大量时间。由于相当多的时候人们只关心表中的一部分数据,故建表时引入了分区概念。
2、hive分区表:是指在创建表时指定的partition的分区空间,若需要创建有分区的表, 需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。
2.2、实现创建、删除分区表
注意:
1、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
2、hive的表和列名不区分大小写(故建表时,都是小写)
3、分区是以字段的形式在表结构中存在,通过"desc table_name"命令可以查看到字段存在,该字段仅是分区的标识。
4、建表的语法(建分区可参见PARTITIONED BY参数):
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
5、分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
a、单分区建表语句:create table test_table (id int, content string) partitioned by (dt string);
单分区表,按天分区,在表结构中存在id,content,dt三列。
b、双分区建表语句:create table test_table_2 (id int, content string) partitioned by (dt string, hour string);
双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
6、增加分区表语法(表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ... partition_spec: : PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
用户可以用 ALTER TABLE ADD PARTITION 来向一个表中增加分区。当分区名是字符串时加引号。例:
ALTER TABLE test_table ADD PARTITION (dt='2016-08-08', hour='10') location '/path/uv1.txt' PARTITION (dt='2017-08-08', hour='12') location '/path/uv2.txt';
7、删除分区语法:
ALTER TABLE table_name DROP partition_spec, partition_spec,...
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:
ALTER TABLE test_table DROP PARTITION (dt='2016-08-08', hour='10');
8、数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
例:
LOAD DATA INPATH '/user/uv.txt' INTO TABLE test_table_2 PARTITION(dt='2016-08-08', hour='08'); LOAD DATA local INPATH '/user/hh/' INTO TABLE test_table partition(dt='2013-02- 07');
当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录,文件存放在该分区下。
9、基于分区的查询的语句:
SELECT test_table.* FROM test_table WHERE test_table.dt>= '2008-08-08';
10、查看双分区语句:
hive> show partitions test_table_2; OK dt=2016-08-08/hour=10 dt=2016-08-09/hour=10 dt=2008-08-09/hour=10
11、动态分区
如果需要创建非常多的分区,那么用户就需要写非常多的SQL!不过幸运的是,Hive提供了一个动态分区的功能,其可以基于查询参数推断出需要创建的分区名称。相比之下,到目前为止我们所看到的都是静态分区。
insert overwrite table employees partition (country, state) select ..., se.cnty, se.st from staged_employees se;
Hive根据select语句中最后2列来确定分区字段country和state的值。这就是为什么在表staged_employees中我们使用了不同的命名,就是为了强调源表字段值和输出分区值之间的关系是根据位置而不是根据命名来匹配的。
假设表staged_employees中共有100个国家和州的话,执行完上面的查询后,表employees就会有100个分区。
用户也可以混合使用动态和静态分区。例如下面的例子指定了country字段的值为静态的US,而分区字段state是动态值:
insert overwrite table employees partition (country = 'US', state) select ..., se.cnty, se.st from staged_employees se where se.cnty = 'US';
动态分区默认情况下没有开启,开启后,默认是以“严格”模式执行的,在这种模式下要求至少有一列分区字段是静态的。这有助于阻止因设计错误导致查询产生大量的分区。

三、外部分区表
外部表同样可以使用分区。事实上,用户可能会发现,这是管理大型生成数据集最常见的情况。这种结合给用户提供了一个可以和其它工具共享数据得方式,同时也可以优化查询性能。
例如:假定将日志数据按照天进行划分,划分数据尺寸合适,而且按天这个粒度进行查询速度也足够快。
create external table if not exists log_messages ( hms int, serverity string, server string, process_id int, message string) partitioned by (year int, month int, day int) row format delimited fields terminated by ' ';
分区表的灵活性:
例如:
1、将分区下的数据拷贝到S3中,用户可以使用hadoop distcp命令:
hadoop distcp /data/log_message/2011/12/02 s3n://ourbucket/logs/2011/12/02
2、修改表,将分区路径指向到S3路径:
alter table log_messages partition(year=2011,month=12,day=2) set location 's3n://ourbucket/logs/2011/01/02';
3、使用hadoop fs -rmr 命令删除掉HDFS中的这个分区数据:
hadoop fs -rmr /data/log_messages/2011/01/02
顺便说一下,Hive不关心一个分区对应的分区目录是否存在或者分区目录下是否有文件。如果分区目录不存在或分区目录下没有文件,则对于这个过滤分区的查询将没有返回结果。当用户想在另外一个进程开始往分区中些数据之前创建好分区时,这样做很方便的。数据一旦存在,对于这份数据得查询就会有返回结果。
分区的另一个好处是:通过分区为新旧数据进行隔离。可以将新数据写入到一个专用的目录中,并与位于其它目录中的数据存在明显的区别。不管用户是将旧数据转移或直接删除掉,新数据被篡改的风险都被降低了,因为新数据得数据子集位于不同目录下。
和非分区外部表一样,Hive并不控制这些数据。即使表被删除,数据也不会被删除。
和分区管理表一样,通过show partitions命令可以查看一个外部表的分区:

通常会使用分区外部表,因为它具有非常多的优点,例如逻辑数据管理、高性能的查询等。
alter table ...add partition语句并非只有对外部表才能够使用。对于管理表,当有分区数据不是由我们之前讨论过的load和insert语句产生时,用户同样可以使用这个命令指定分区路径。
四、表的常见操作
4.1、删除表
Hive支持和SQL中drop table命令类似的操作:
drop table if exists employees;
可以选择是否使用if exists关键字。如果没有使用这个关键字而且表并不存在的话,那么僵会抛出一个错误信息。
对于管理表(内部表),表的元数据信息和表内的数据都会被删除。
对于外部表,表的元数据信息会被删除,但是表中的数据不会被删除。
4.2、修改表
大多数表属性可以通过alter table语句来进行修改。这种操作会修改元数据,但不会修改数据本身。这些语句可以用于修改表模式中出现的错误、改变分区路径,以及其他一些操作。
4.3、表重命名
使用以下这个语句可以将表log_messages重命名为logmsgs:
alter table log_messages rename to logmsgs;
4.4、增加、修改和删除表分区
alter table table1 add partition ...用于为表(通常是外部表)增加一个新的分区。这里我们增加可提供的可选项,然后多次重复前面的分区路径语句:
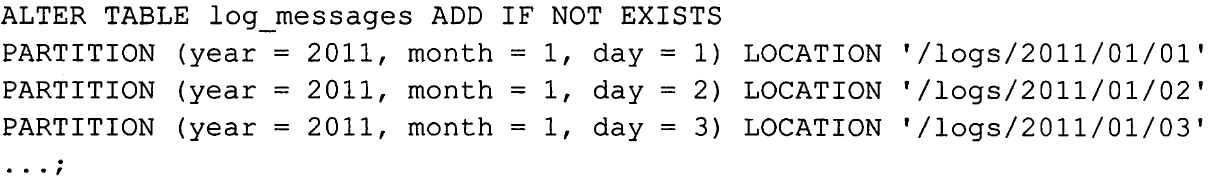
4.5、修改列信息
用户可以对某个字段进行重命名,并修改其位置、类型或者注释:
alter table log_messges change column hms hours_minutes_seconds int comment 'the hours, minutes, and seconds part of the timestamp' after severity;
4.6、增加列
用户可以再分区字段之前增加新的字段到已有的字段之后。
alter table log_messages add columns ( app_name string comment 'application name', session_id long comment 'the current session id');
4.7、删除或者替换列
下面这个例子移除了之前所有的字段并重新指定了新的字段:
alter table log_messages replace columns ( hours_mins_secs int comment 'hour, minute, seconds from timestamp', severity string comment 'the message severity' message string comment 'the rest of the message');
4.8、修改表属性
用户可以增加附加的表属性或者修改已经存在的属性,但是无法删除属性:
alter table log_messages set tblproperties ( 'notes' = 'the process id is no longer captured; this column is always null'):
4.9、修改存储属性
有几个alter table 语句用于修改存储格式和SerDe属性。
下面这个语句将一个分区的存储格式修改成了sequence file,
alter table log_messages partition(year=2012, month = 1, day = 1) set fileformat sequencefile;
如果表是分区表,那么需要使用partition子句。
用户可以指定一个新的SerDe,并为其指定SerDe属性,或者修改已经存在的SerDe的属性。下面这个例子是一个名为com.example.JSONSerDe的java类来处理记录使用JSON编码的文件:
alter table table_using_JSON_storage set serde 'com.example.JSONSerDe' with serdeproperties ( 'prop1' = 'value1', 'prop2' = 'value2');
serdeproperties中的属性会被传递给SerDe模块(本例中,也就是com.example.JSONSerDe这个java类)。需要注意的是,属性名(如prop1)和属性值(如value1)都应当是带引号的字符串。
serdeproperties这个功能是一种方便的机制,它使得SerDe的各种事项都允许用户进行自定义。
例如:如何向一个已经存在着的SerDe增加新的serdeproperties属性:
alter table table_using_JSON_storage set serdeproperties( 'prop3' = 'value3', 'prop4' = 'value4');
4.10、其它的修改表语句
为各种操作增加执行“钩子”的技巧。
alter table ...touch语句用于触发这些钩子:
alter table log_messages touch partition(year=2012, month=1,day=1);
五、示例
5.1、内部表、外部表示例
1.Hive内部表,语句如下
CREATE TABLE ods.s01_buyer_calllogs_info_ts( key string comment "hbase rowkey", buyer_mobile string comment "手机号", contact_mobile string comment "对方手机号", call_date string comment "发生时间", call_type string comment "通话类型", init_type string comment "0-被叫,1-主叫", other_cell_phone string comment "对方手机号", place string comment "呼叫发生地", start_time string comment "发生时间", subtotal string comment "通话费用", use_time string comment "通话时间(秒)" ) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,record:buyer_mobile,record:contact_mobile,record:call_date,record:call_type,record:init_type,record:other_cell_phone,record:place,record:start_time,record:subtotal,record:use_time") TBLPROPERTIES("hbase.table.name" = "s01_buyer_calllogs_info_ts");
建好表之后,进入hbase shell执行list能看到表s01_buyer_calllogs_info_ts,hive drop掉此表时,hbase也被drop。
2.这样我们就在Hive里面创建了一张普通的表,现在给这个表导入数据:
load data local inpath '/home/wyp/data/wyp.txt' into table wyp;
3.创建外部表多了external关键字说明以及location ‘/home/wyp/external’
create 'buyer_calllogs_info_ts', 'record', {SPLITS_FILE => 'hbase_calllogs_splits.txt'} CREATE EXTERNAL TABLE ods.s10_buyer_calllogs_info_ts( key string comment "hbase rowkey", buyer_mobile string comment "手机号", contact_mobile string comment "对方手机号", call_date string comment "发生时间", call_type string comment "通话类型", init_type string comment "0-被叫,1-主叫", other_cell_phone string comment "对方手机号", place string comment "呼叫发生地", start_time string comment "发生时间", subtotal string comment "通话费用", use_time string comment "通话时间(秒)" ) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,record:buyer_mobile,record:contact_mobile,record:call_date,record:call_type,record:init_type,record:other_cell_phone,record:place,record:start_time,record:subtotal,record:use_time") TBLPROPERTIES("hbase.table.name" = "buyer_calllogs_info_ts");
从方式需要先在hbase建好表,然后在hive中建表,hive drop掉表,hbase表不会变。
创建外部表,需要在创建表的时候加上external关键字,同时指定外部表存放数据的路径(当然,你也可以不指定外部表的存放路径,这样Hive将 在HDFS上的/user/hive/warehouse/文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里)
外部表导入数据和内部表一样:load data local inpath '/home/wyp/data/wyp.txt' into table exter_table;
==================================================
CREATE EXTERNAL TABLE hivebig (key string,CUST_NAME string,PHONE_NUM int,BRD_WORK_FLUX double)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,bd:CUST_NAME,bd:PHONE_NUM#b,bd:BRD_WORK_FLUX#b")
TBLPROPERTIES ("hbase.table.name" = "bigtable2");
https://blog.csdn.net/jameshadoop/article/details/42162669
==================================================
4.和上面的导入数据到表一样,将本地的数据导入到外部表,数据也是从本地文件系统复制到HDFS中/home/hdfs/wyp.txt文件中,但是,最后 数据不是移动到外部表的/user/hive/warehouse/exter_table文件夹中(除非你创建表的时候没有指定数据的存放路径)!大家 可以去HDFS上看看!对于外部表,数据是被移动到创建表时指定的目录(本例是存放在/home/wyp/external文件夹中)!
5.内部表删除
hive> drop table wyp;
Moved: 'hdfs://mycluster/user/hive/warehouse/wyp' to
trash at: hdfs://mycluster/user/hdfs/.Trash/Current
OK
Time taken: 2.503 seconds
如果你要删除外部表:drop table exter_table;
hive> drop table exter_table;
OK
Time taken: 0.093 seconds
和上面删除Hive的表对比可以发现,没有输出将数据从一个地方移到任一个地方!那是不是删除外部表的的时候数据直接被删除掉呢?答案不是这样的,你会发现删除外部表的时候,数据并没有被删除,而只是删除了元数据,这是和删除表的数据完全不一样的
总结:
1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的,而表则不一样;
2、在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
那么,应该如何选择使用哪种表呢?在大多数情况没有太多的区别,因此选择只是个人喜好的问题。但是作为一个经验,如果所有处理都需要由Hive完成,那么你应该创建内部表,否则使用外部表!
5.2、分区表示例
创建一个分区表,分区的单位时dt和国家名
hive> create table logs(ts bigint,line string)
> partitioned by (dt String,country string);
接下来我们创建要给分区
hive> load data local inpath '/root/hive/partitions/file1' into table logs
> partition (dt='2001-01-01',country='GB');
上面语句的效果是在hdfs系统上建立了一个层级目录
-logs
-dt=2001-01-01
-country=GB

我们继续执行下面语句,先看一下什么效果 hive> load data local inpath '/root/hive/partitions/file2' into table logs > partition (dt='2001-01-01',country='GB'); Loading data to table default.logs partition (dt=2001-01-01, country=GB) OK Time taken: 1.379 seconds hive> load data local inpath '/root/hive/partitions/file3' into table logs > partition (dt='2001-01-01',country='US'); Loading data to table default.logs partition (dt=2001-01-01, country=US) OK Time taken: 1.307 seconds hive> load data local inpath '/root/hive/partitions/file4' into table logs > partition (dt='2001-01-02',country='GB'); Loading data to table default.logs partition (dt=2001-01-02, country=GB) OK Time taken: 1.253 seconds hive> load data local inpath '/root/hive/partitions/file5' into table logs > partition (dt='2001-01-02',country='US'); Loading data to table default.logs partition (dt=2001-01-02, country=US) OK Time taken: 1.07 seconds hive> load data local inpath '/root/hive/partitions/file6' into table logs > partition (dt='2001-01-02',country='US'); Loading data to table default.logs partition (dt=2001-01-02, country=US) OK Time taken: 1.227 seconds
我们到HDFS上查看,发现建立了下面层级目录
/user/hive/warehouse/logs
├── dt=2001-01-01/
│ ├── country=GB/
│ │ ├── file1
│ │ └── file2
│ └── country=US/
│ └── file3
└── dt=2001-01-02/
├── country=GB/
│ └── file4
└── country=US/
├── file5
└── file6
是加上所有files的内容基本上一样,蓝色的^A是系统默认分隔符。八进制是‘�01’.随后参考我的另一个文章。比较详细解释了分隔符。
