因为做网页爬虫,需要用到一个爬新闻的BeautifulSoup 的包,然后再关网上下的是whl包,第一次装,虽然花了点时间,最后还是装上去了,记录一下,方便下次。
先发一下官方文档地址。http://www.crummy.com/software/BeautifulSoup/bs4/doc/
建议有时间可以看一下Python包的文档。
Beautiful Soup 相比其他的html解析有个非常重要的优势。html会被拆解为对象处理。全篇转化为字典和数组。
相比正则解析的爬虫,省略了学习正则的高成本。
相比xpath爬虫的解析,同样节约学习时间成本。虽然xpath已经简单点了。(爬虫框架Scrapy就是使用xpath)
先在网页上下载自己python版本对应的包。https://pypi.python.org/pypi/beautifulsoup4/#downloads
1.在安装pip前,请确认win系统中已经安装好了python,和easy_install工具,如果系统安装成功,easy_install在目录C:Python27Scripts 下面,确认截图如下:
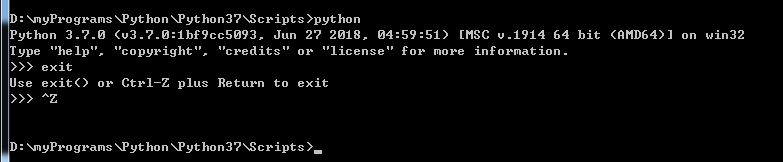
2.进入命令行,然后把目录切换到python的安装目录下的Script文件夹下,运行 easy_inatall pip。
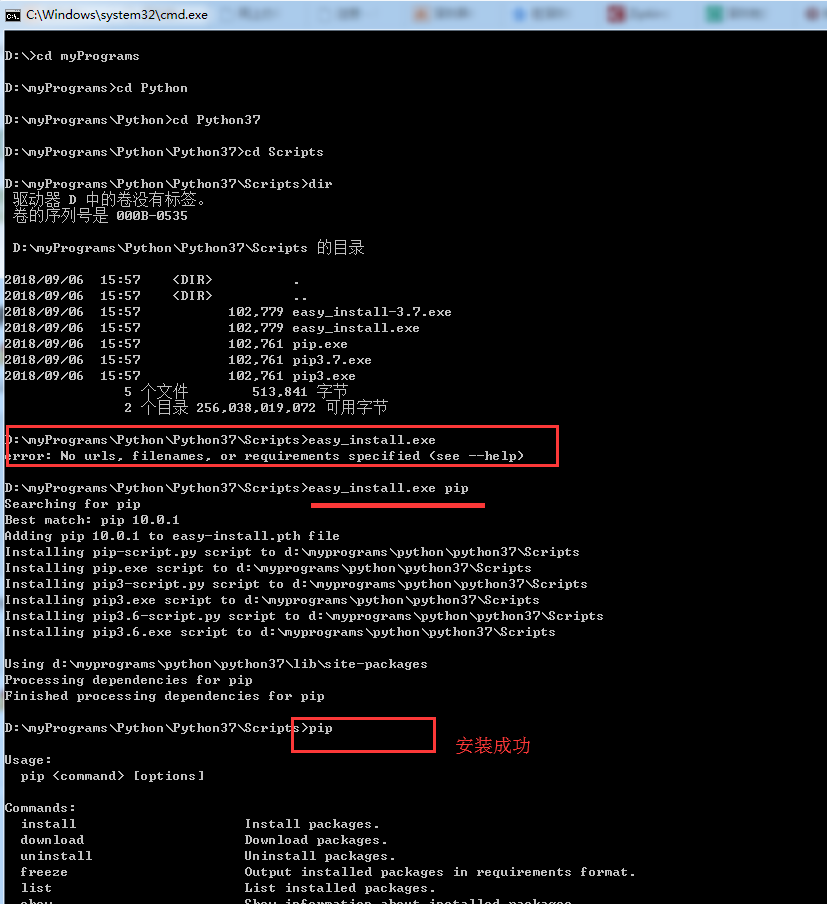
3.pip安装成功后,在cmd下执行pip,将会有如下提示。pip install 文件地址。安装成功后就可以看到pycharm里面已经有之前安装的包了

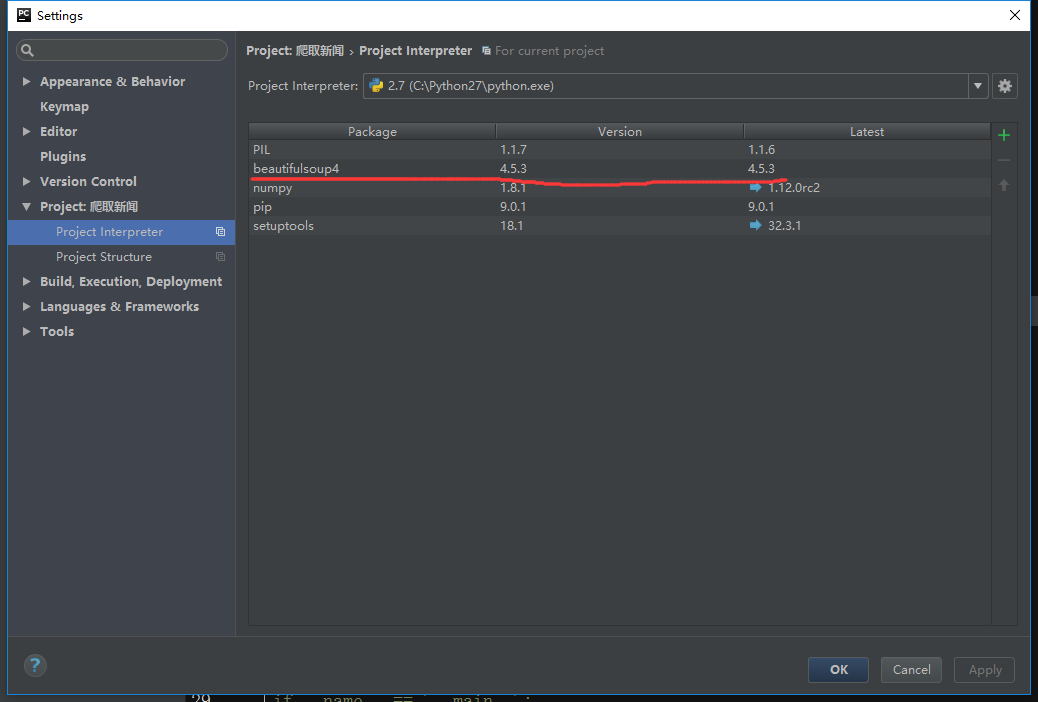
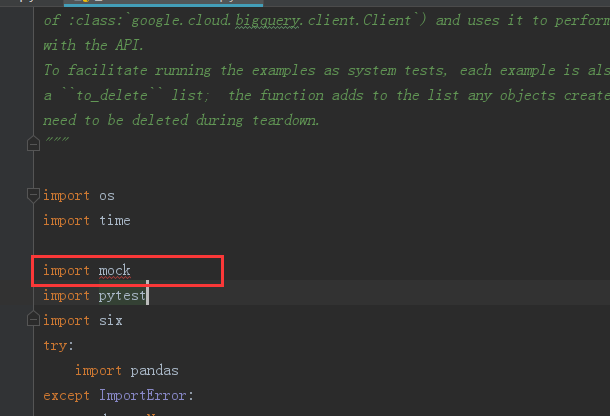
在看我的IDE里的import mock这行报错了,要安装mock库,pip install mock
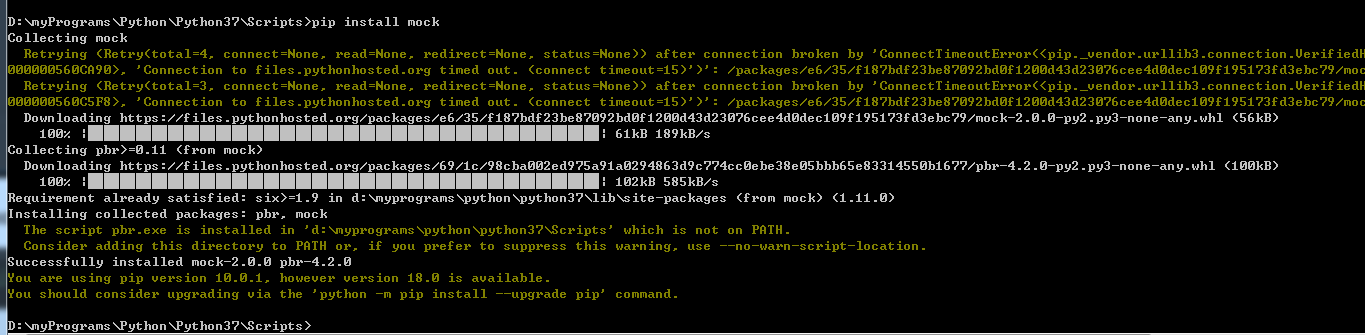
再回到IDE中,错误消失。
