《Redis性能问题排查解决手册》
《Redis的基本操作以及info命令》
《redis object命令》
《清理 redis 死键》
1.redis登录
redis-cli -h 127.0.0.1 -p 6377
2. Redis 配置文件位置查询
在redis内部执行命令: CONFIG GET *
一般情况下配置文件叫:redis.conf
3. 查询Redis进程
ps -ef | grep redis-server 可以查看 redis进程,以及可以查看到安装路径等信息
4. redis key值获取
keys * 获取当前数据下所有KEY值
get key
select 2 切换到第二个数据库
5. info命令
转自:http://www.runoob.com/redis/server-info.html
info server : 一般 Redis 服务器信息,包含以下域:
- redis_version : Redis 服务器版本
- redis_git_sha1 : Git SHA1
- redis_git_dirty : Git dirty flag
- os : Redis 服务器的宿主操作系统 arch_bits : 架构(32 或 64 位)
- multiplexing_api : Redis 所使用的事件处理机制
- gcc_version : 编译 Redis 时所使用的 GCC 版本
- process_id : 服务器进程的 PID
- run_id : Redis 服务器的随机标识符(用于 Sentinel 和集群)
- tcp_port : TCP/IP 监听端口 uptime_in_seconds : 自 Redis 服务器启动以来,经过的秒数
- uptime_in_days : 自 Redis 服务器启动以来,经过的天数
- lru_clock : 以分钟为单位进行自增的时钟,用于 LRU 管理
info clients 表示已连接客户端信息 包含以下内容:
- connected_clients 已连接客户端的数量(不包括通过从属服务器连接的客户端)
- client_longest_output_list 当前连接的客户端当中,最长的输出列表
- client_longest_input_buf 当前连接的客户端当中,最大输入缓存
- blocked_clients 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
info cpu CPU 计算量统计信息
info mem 内存信息,包含以下:
- used_memory : 由 Redis 分配器分配的内存总量,以字节(byte)为单位
- used_memory_human : 以人类可读的格式返回 Redis 分配的内存总量
- used_memory_rss : 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。
- used_memory_peak : Redis 的内存消耗峰值(以字节为单位)
- used_memory_peak_human : 以人类可读的格式返回 Redis 的内存消耗峰值
- used_memory_lua : Lua 引擎所使用的内存大小(以字节为单位)
- mem_fragmentation_ratio : used_memory_rss 和 used_memory 之间的比率 内存碎片率
- mem_allocator : 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc 。
在理想情况下, used_memory_rss 的值应该只比 used_memory 稍微高一点儿。
当 rss > used ,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。
内存碎片的比率可以通过 mem_fragmentation_ratio 的值看出。
当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。--指标
当 Redis 释放内存时,分配器可能会,也可能不会,将内存返还给操作系统。
如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的 Redis 内存占用并不一致。
查看 used_memory_peak 的值可以验证这种情况是否发生
info persistence RDB 和 AOF 的相关信息
info stats : 一般统计信息
info replication : 主/从复制信息
info commandstats Redis 命令统计信息
info cluster Redis 集群信息
info keyspace redis 数据库相关的统计信息
6. redis慢查询语句
slow log get 10 慢查询语句, 在上一个节中有讲过
http://www.cnblogs.com/huamei2008/p/8850047.html
7.redis查询延时
Redis-cli --latency
8. Redis自身性能压测
命令:
redis-benchmark -p 6379 -c 20000 -n 50000
-h 表示IP
-p 表示端口
-c 表示连接数
-n表示请求数
-t 后面跟请求方式, 如get
9.scan命令
有时,我们需要针对符合条件的一部分命令进行操作,比如删除以test_开头的key。那么怎么获取到这些key呢?在Redis2.8版本之前,我们可以使用keys命令按照正则匹配得到我们需要的key。但是这个命令有两个缺点:
- 没有limit,我们只能一次性获取所有符合条件的key,如果结果有上百万条,那么等待你的就是“无穷无尽”的字符串输出。
- keys命令是遍历算法,时间复杂度是O(N)。如我们刚才所说,这个命令非常容易导致Redis服务卡顿。因此,我们要尽量避免在生产环境使用该命令。
在满足需求和存在造成Redis卡顿之间究竟要如何选择呢?面对这个两难的抉择,Redis在2.8版本给我们提供了解决办法——scan命令。
相比于keys命令,scan命令有两个比较明显的优势:
- scan命令的时间复杂度虽然也是O(N),但它是分次进行的,不会阻塞线程。
- scan命令提供了limit参数,可以控制每次返回结果的最大条数。
这两个优势就帮助我们解决了上面的难题,不过scan命令也并不是完美的,它返回的结果有可能重复,因此需要客户端去重。至于为什么会重复,相信你看完本文之后就会有答案了。
关于scan命令的基本用法,可以参看Redis命令详解:Keys一文中关于SCAN命令的介绍。
今天我们主要从底层的结构和源码的角度来讨论scan是如何工作的。
Redis的结构
Redis使用了Hash表作为底层实现,原因不外乎高效且实现简单。说到Hash表,很多Java程序员第一反应就是HashMap。没错,Redis底层key的存储结构就是类似于HashMap那样数组+链表的结构。其中第一维的数组大小为2n(n>=0)。每次扩容数组长度扩大一倍。
scan命令就是对这个一维数组进行遍历。每次返回的游标值也都是这个数组的索引。limit参数表示遍历多少个数组的元素,将这些元素下挂接的符合条件的结果都返回。因为每个元素下挂接的链表大小不同,所以每次返回的结果数量也就不同。
SCAN的遍历顺序
关于scan命令的遍历顺序,我们可以用一个小栗子来具体看一下。
127.0.0.1:6379> keys *
1) "db_number"
2) "key1"
3) "myKey"
127.0.0.1:6379> scan 0 MATCH * COUNT 1
1) "2"
2) 1) "db_number"
127.0.0.1:6379> scan 2 MATCH * COUNT 1
1) "1"
2) 1) "myKey"
127.0.0.1:6379> scan 1 MATCH * COUNT 1
1) "3"
2) 1) "key1"
127.0.0.1:6379> scan 3 MATCH * COUNT 1
1) "0"
2) (empty list or set)我们的Redis中有3个key,我们每次只遍历一个一维数组中的元素。如上所示,SCAN命令的遍历顺序是
0->2->1->3
这个顺序看起来有些奇怪。我们把它转换成二进制就好理解一些了。
00->10->01->11
我们发现每次这个序列是高位加1的。普通二进制的加法,是从右往左相加、进位。而这个序列是从左往右相加、进位的。这一点我们在redis的源码中也得到印证。
在dict.c文件的dictScan函数中对游标进行了如下处理
v = rev(v);
v++;
v = rev(v);意思是,将游标倒置,加一后,再倒置,也就是我们所说的“高位加1”的操作。
这里大家可能会有疑问了,为什么要使用这样的顺序进行遍历,而不是用正常的0、1、2……这样的顺序呢,这是因为需要考虑遍历时发生字典扩容与缩容的情况(不得不佩服开发者考虑问题的全面性)。
我们来看一下在SCAN遍历过程中,发生扩容时,遍历会如何进行。加入我们原始的数组有4个元素,也就是索引有两位,这时需要把它扩充成3位,并进行rehash。
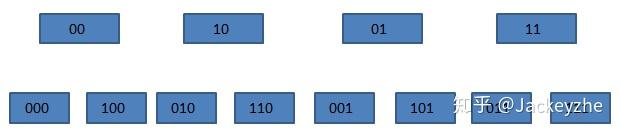
原来挂接在xx下的所有元素被分配到0xx和1xx下。在上图中,当我们即将遍历10时,dict进行了rehash,这时,scan命令会从010开始遍历,而000和100(原00下挂接的元素)不会再被重复遍历。
再来看看缩容的情况。假设dict从3位缩容到2位,当即将遍历110时,dict发生了缩容,这时scan会遍历10。这时010下挂接的元素会被重复遍历,但010之前的元素都不会被重复遍历了。所以,缩容时还是可能会有些重复元素出现的。