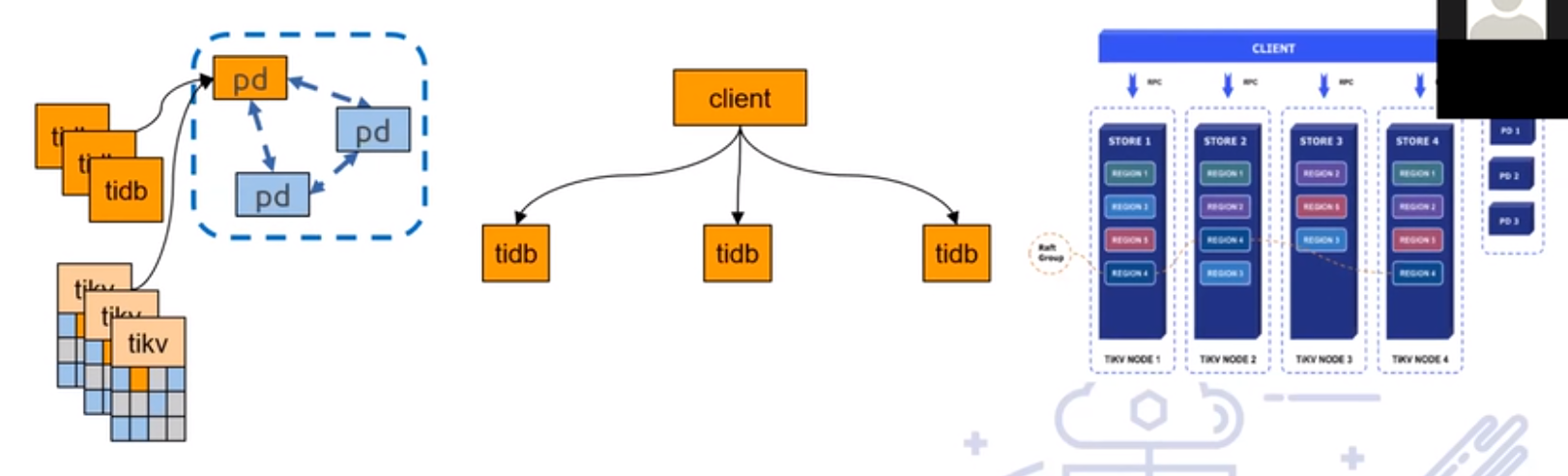
数据库中间件的优缺点
优点:
缺点:
- 只适用于简单业务,同时对业务有侵入性,需要改造业务
- 很难支撑跨分片的高性能复杂查询
- 分布式事务性能损失,一般是在单机的事务之上增加一层分布式事务(如事务管理器,TCC)
- 水平扩展能力差,只能按照选定的分配规则横向扩展
- 大型集群运维困难
- 表结构变更(DDL)操作困难,容易出现失误
- 只能按照分片进行维护(备份、恢复等操作)
NoSQL Not Only SQL
- 放弃高级SQL能力,追求强水平扩展能力(反过来意味着业务兼容的成本高)
- 放弃复杂SQL查询
- 放弃分布式事务(ACID)
- 通常的数据访问模型:
- 键值对
- 文档型
- 代表系统:
- mongoDB
- CouchBase
- Cassandra
- HBase
典型系统分析:MongoDB
- 文档型数据库
- 仍然是通过选择Sharing key的方式进行分片
- Range或hash分片
- 优点:
- Scheme-less,对文档型数据比较友好
- 缺点:
-
- 跨分片聚合能力差
- rebalance过程中会占用大量带宽
- 无跨分片事务
典型系统分析:HBase
- Google BigTable的开源实现
- 扩展能力构建在分布式文件系统(HDFS)之上
- 分布式表格系统
- 优点:
- 依赖HDFS的横向扩展能力,基本可以做到无限的水平扩展
- Region Server用于管理数据分片
- 支持动态水平切分
- 初步做到热点转移
- 缺点:
- 无事务支持
- 依赖HDFS提供存储能力,多一层抽象,性能损失
- Hadoop体系运维复杂度高
典型系统分析:Cassandra
- Amazon Dynamo论文实现
- 分布式KV数据库
- 优点:
- 提供在单KV操作上的多种一致性模型
- 强一致 or 最终一致性 可配置
- 并不是ACID事务
- 扩展性强
- 缺点
- KV模型过于简单,对业务侵入性大
- 运维比较复杂
- 国内社区和支持缺乏
NoSQL系统的通用优缺点
优点:
- 水平扩展能力强
- 针对特殊类型数据效果好,可以作为关系型数据库的很好补充
- 对于一致性要求不强的场景,可能会有更好的性能
缺点:
- 由于不支持SQL业务需要进行较大的改造
- 普遍无法支持事务,强一致性场景比较难实现
- 复杂查询受限
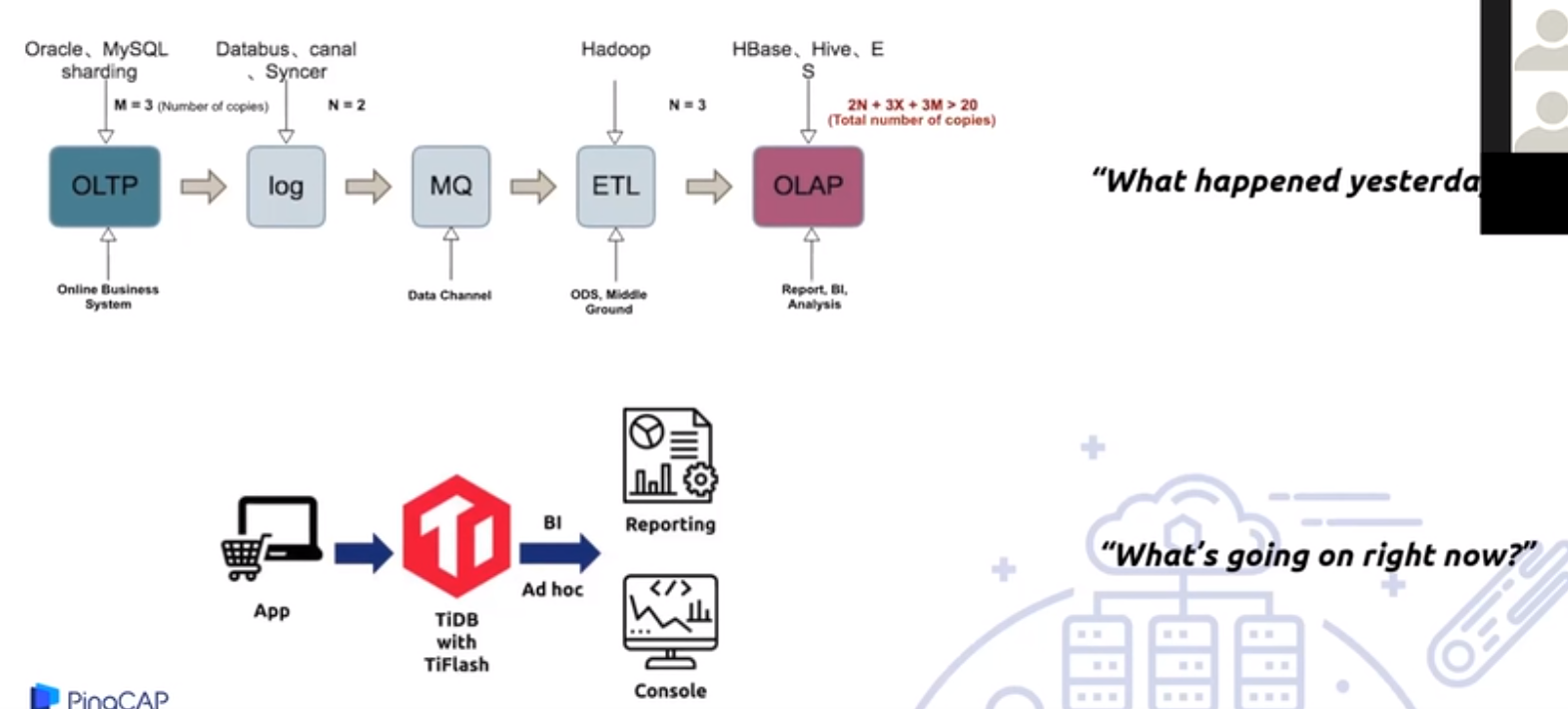
第三代分布式数据库NewSQL
两种流派:
- 以Google Spanner为代表的Shared Nothing架构
- 以AWS Aurora为代表的Shared Everything架构
Shared Nothing流派
特点:
- 无限的弹性水平扩展
- 强SQL支持(几乎不需要妥协,无需指定分片策略,系统自动扩展)
- 和单机数据库一样的事务支持
- 跨数据中心故障自恢复级别的高可用能力
代表作品:
- Google Spanner
- TiDB 3.0及之前版本
- CockroachDB
优点:
- 无限水平扩展,没有容量上限,对海量数据场景友好
- 对金融级别的一致性ACID事务支持,业务改动代价小
- 故障自恢复的高可用能力,运维省事
- SQL能力强,和单机数据库的体验一直
- 例如:TiDB支持MySQL的绝大多少语法和网络协议(覆盖度92%)
- 无限扩展的吞吐能力(和业务负载有关)
缺点:
- 并非100%兼容传统数据库的语法
- 对于一些极端场景(秒杀),延时不如单机数据库(跨机,跨地域的分布式事务必然带来更高延迟)
- 例子:小事务平均latency:2ms(单机) Vs 5ms(分布式)
Shared Everything流派
代表作品:AWS Aurora、阿里云PolarDB
Cloud-Native
- 通常由公有云提供
存储计算分离
- 无状态SQL计算节点
- 计算节点通常直接复用MySQL,但是不存储数据
- 远程存储(数据文件层)
Aurora可理解单机型数据库,数据存储时没有分片,最大容量由单台服务器决定,存储上限64T(一台服务器最大可插的硬盘),数据被全量拷贝到多台服务器上。
之前做法:binlog的主从复制
AWS做法:复制redo log而不是binlog,更少的IO路径,更小的网络包
优点:
- 易用,100%兼容MySQL,业务兼容性好
- 对一致性要求不高的场景,读可以水平扩展(但是有上限)
缺点:
- 本质上还是单机数据库,如果要支持大数据量,仍然需要分库分表
- 内存和容量不匹配,在单表数据量大后,性能抖动严重
- 跨机的事务一致性问题
- 分析能力受限于单点,几乎没有分布式OLAP能力
下一代系统:分布式HTAP数据库
HTAP的定义:Hybrid transactional/analytical processing,混合事务分析处理
- 分布式HTAP的标准:
- 业务透明的无限水平扩展能力
- 分布式事务的支持
- 多数据中心故障自恢复的高可用能力
- 提供高性能的分析能力
- 提供列式存储能力
- 在混合负载下,实时OLAP分析不影响OLAP事务
- 目前业界仅有TiDB 4.0能达到上述的要求
- TiDB + TiFlash(TiDB的列存扩展)
-
分布式HTAP数据库:TiDB + TiFlash
- 为什么能实现OLAP和OLTP的彻底隔离,互不影响?
- 存储和计算彻底分离
- 列式存储(适用于OLAP)以副本扩展的形式存在
- 通过Multi raft架构进行日志级别的复制同步,业务层完全无感知
- 扩展性依托TiDB的分布式架构,能做到水平扩展
- 数据同步不会成为瓶颈
- 面向实时分析设计,不需要额外的技术栈从数据库同步到实时数仓
- 数据同步不会成为瓶颈
未来的数据库的趋势?
- 功能上以HTAP为基础
- 面向云特性设计
- 智能化
- 平台化
为什么是 HTAP?
在互联网浪潮出现之前,企业的数据量普遍不大,特别是核心的业务数据,通常一个单机的数据库就可以保存。那时候的存储并不需要复杂的架构,所有的线上请求 (OLTP, Online Transactional Processing) 和后台分析 (OLAP, Online Analytical Processing) 都跑在同一个数据库实例上。
随着互联网的发展,企业的业务数据量不断增多,单机数据库的容量限制制约了其在海量数据场景下的使用。因此在实际应用中,为了面对各种需求,OLTP、OLAP 在技术上分道扬镳,在很多企业架构中,这两类任务处理由不同团队完成。当物联网大数据应用不断深入,具有海量的传感器数据要求实时更新和查询,对数据库的性能要求也越来越高,此时,新的问题随之出现:
- OLAP 和 OLTP 系统间通常会有几分钟甚至几小时的时延,OLAP 数据库和 OLTP 数据库之间的一致性无法保证,难以满足对分析的实时性要求很高的业务场景。
- 企业需要维护不同的数据库以便支持两类不同的任务,管理和维护成本高。
因此,能够统一支持事务处理和工作负载分析的数据库成为众多企业的需求。在此背景下,由 Gartner 提出的 HTAP(混合事务 / 分析处理,Hybrid Transactional/Analytical Processing)成为希望。基于创新的计算存储框架,HTAP 数据库能够在一份数据上同时支撑业务系统运行和 OLAP 场景,避免在传统架构中,在线与离线数据库之间大量的数据交互。此外,HTAP 基于分布式架构,支持弹性扩容,可按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
目前,实现 HTAP 的数据库不多,主要有 PingCAP 的 TiDB、阿里云的 HybridDB for MySQL、百度的 BaikalDB 等。其中,TiDB 是国内首家开源的 HTAP 分布式数据库,接下来,本文将以此例进行深入分析。
TiDB典型应用场景
- 海量数据高并发OLTP系统
- 不再分库分表,不再使用妥协的数据库中间件,业务不再受限制于基础架构
- 海量数据高性能实时分析
- 兼容MySQL,大数据量下比MySQL快1~2个数量级的融合OLTP和OLAP的HTAP数据库
- 多源高吞吐汇总与实时计算
- 多源(数十至数百异构数据源)高吞吐(数十万QPS)汇聚写入AD-Hoc准实时查询
- 实时数仓
- 通过TiSpark无缝连接Spark,无需ETL,提供实时的大规模复杂OLAP分析查询能力。
- 金融级别多数据中心多活
- 故障自动恢复,无需人工介入的真正意义上的高可用
- 云数据库
- 同kubernetes、Docker等容器技术完美整合,自动调度有状态的服务
OLTP场景
场景特点:
- 高频SQL
- 数据量中等
- 相应延时低
- 读多写少
关注点:
- 高可用
- 故障自动修复
- 在线变更schema
- 多点写入
金融OLTP场景
场景特点:
- 数据一致性
- 事务一致性
- 业务连续性
关注点:
- 传统OLTP所有点
- 强一致性
- 高并发、高性能
- 故障容错性
- 跨地域多活、容灾故障自动修复
OLTP场景的TiDB方案
- TiDB场景优势
- 数据一致性保证
- 在线DDL
- 支持多点写入
- 自动故障检测、选主、转移
- 计算存储分离,快速扩容读优点
- TiDB场景劣势
- 网络交互多,导致延时增大
- 有机器硬件要求(万兆网+SSD)
HTAP场景TiDB
TiDB的TP起步阶段
中台业务场景
业务需求:
- 微服务下的数据孤岛问题
- 分片多维度查询问题
- 需要静态数据Join动态数据
- 需要完整SQL语义、支持复杂SQL
- 需要便于增量更新、索引维护
- 需要便于从binlog实时同步
TiDB非常适合中台场景
- 协议兼容,轻松同步MySQL
- 透明无障碍的跨分片查询
- 数据实时落地
- 海量存储允许多数据源汇聚
- 备库-中台分析二合一
TiDB工作方式:
1、朴素工作方式(无Coprocessor)场景

2、Coprocessor场景
例如:聚合count、top、limit等都可以将计算任务从计算层下推TiKV(存储层),经过2次计算。

TiDB集群HTAP能力的短板
- TiDB之间无法直接交换数据,汇总计算只能在当前会话的机器单台上进行(与MPP的架构区别)
- TiKV之间也无法在计算过程中交换数据
- 海量存储(TiKV),半单机计算(TiDB)
- 只能通过TiDB服务器Scale-Up改善
- Coprocessor无法处理需要数据交换的算子
- join
分布式计算架构-TiSpark
- 借助TiSpark
- Spark是成熟的计算平台
- 继承Apache Spark生态
- 向下衔接大数据生态圈
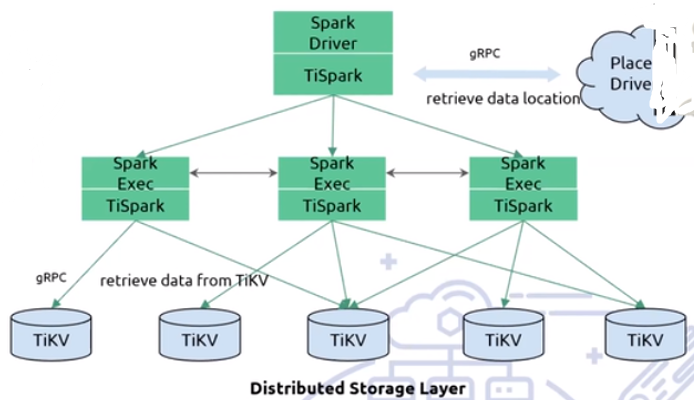
TiSpark能力差距
- 行存对于分析场景不友好
- 数据的获取效率、数据压缩存放等场景
- 无法做到Workload隔离
- TiSpark对于TiKV的CPU和IO资源的占用
双格式数据
行存 列存
TiFlash

新鲜数据的实时分析反哺业务
TiDB容灾部署实战
- 支持广域网链接
- 两地三中心五副本方式部署
- 同城两中心提供读写服务
- 支持单中心失效
- 切换和恢复无需人员介入操作
- 节点扩展和性能
- 存储节点按副本数量扩展
- 支持性能的水平扩展

TiDB组件容灾