1.简介
按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath。xpath 的定位方法, 非常强大。 使用这种方法几乎可以定位到页面上的任意元素。
2.什么是xpath?
xpath 是XML Path的简称, 由于HTML文档本身就是一个标准的XML页面,所以我们可以使用Xpath 的用法来定位页面元素。
XPath 是XML 和Path的缩写,主要用于xml文档中选择文档中节点。基于XML树状文档结构,XPath语言可以用在整棵树中寻找指定的节点。XPath 定位和CSS定位相比有更大的灵活性。XPath 在文档树中某个节点既可以向前搜索,也可以向后搜索,CSS定位只能在文档树中向前搜索,但XPath的定位速度比CSS 慢一些。
3.xpath定位的缺点
xpath 这种定位方式, webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素, 这是个非常费时的操作, 如果脚本中大量使用xpath做元素定位的话, 脚本的执行速度可能会稍慢。
4.常用定位方法(8种)
(1)id
(2)name
(3)class name
(4)tag name
(5)link text
(6)partial link text
(7)xpath(今天讲解)
(8)css selector
5.自动测试实战
以百度首页为例,将xpath的各种定位方法一一讲解和分享一下。
5.1大致步骤
1.访问度娘首页。
2.通过xpath定位到元素,点击一下。
5.2使用索引号定位
索引号定位,以‘//’开头,具体格式为
xxx.By.xpath("//标签[x]")
具体例子:
//form/div[1]:表示 form 下的第一个 div //form/div[last()]:表示 form 下的最后一个 div //form/div[last()-1]:表示 form 下的倒数第二个 div
具体步骤:
在被测试百度网页中,按照宏哥在上卷中5.2中的方法 (1)查找输入框并输入“北京宏哥”,如下图所示:(2)查找“百度一下”按钮,如下图所示:(3)点击“百度一下”按钮。
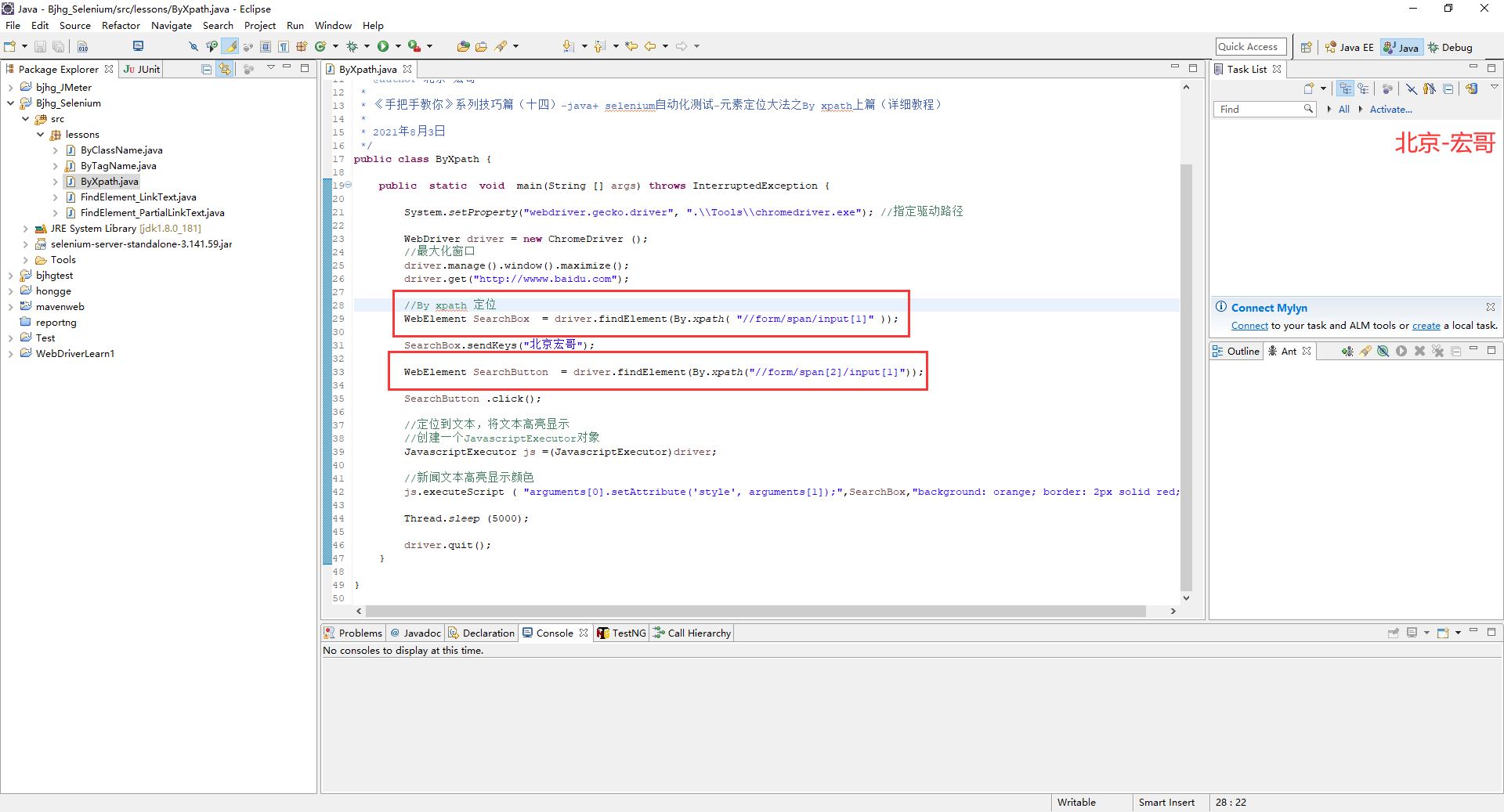
XPath表达式:
(1)//form/span/input[1]
(2)//form/span[2]/input[1]
java定位语句:
(1)WebElement SearchBox = driver.findElement(By.xpath( "//form/span/input[1]" ));
(2)WebElement SearchButton = driver.findElement(By.xpath("//form/span[2]/input[1]"));
5.2.1代码设计
5.2.2参考代码
package lessons; import org.openqa.selenium.By; import org.openqa.selenium.JavascriptExecutor; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; /** * @author 北京-宏哥 * * 《手把手教你》系列技巧篇(十四)-java+ selenium自动化测试-元素定位大法之By xpath上篇(详细教程) * * 2021年8月4日 */ public class ByXpath { public static void main(String [] args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", ".\Tools\chromedriver.exe"); //指定驱动路径 WebDriver driver = new ChromeDriver (); //最大化窗口 driver.manage().window().maximize(); driver.get("http://wwww.baidu.com"); //By xpath 定位 WebElement SearchBox = driver.findElement(By.xpath( "//form/span/input[1]" )); SearchBox.sendKeys("北京宏哥"); WebElement SearchButton = driver.findElement(By.xpath("//form/span[2]/input[1]")); SearchButton .click(); //定位到文本,将文本高亮显示 //创建一个JavascriptExecutor对象 JavascriptExecutor js =(JavascriptExecutor)driver; //新闻文本高亮显示颜色 js.executeScript ( "arguments[0].setAttribute('style', arguments[1]);",SearchBox,"background: orange; border: 2px solid red;"); Thread.sleep (5000); driver.quit(); } }
5.2.3运行代码
1.运行代码,右键Run AS->java Application,控制台输出,如下图所示:
2.运行代码后电脑端的浏览器的动作,如下小视频所示:
根据元素类型在页面中出现的先后顺序,可以使用序号来查找指定的页面元素。本实例的XPath表达式表示查找页面中第二个出现的span中的input元素,即被测试页面上的按钮元素。 如果使用span/input[1],会发现固定位出输入框和按钮元素,这是因为页面中含有两个span节点,每个span节点都包含input元素,XPath在查找的时候,把每个span节点都当作相同的其实层级开始查找,所以input[1]能查出两个元素。
因此在使用序号进行页面定位元素的时候,需要注意网页HTML代码中是否包含多个层级完全相同的代码结构。如果使用XPath表达式同时定位多个页面元素,将定位到多个元素存储到List对象中。
在实际使用中,如果元素经常有新增或减少的情况,不建议使用索引号定位的方式,因为页面的变化会导致使用索引号的XPath表达式定位失败。
5.3使用页面属性定位
标签属性定位,相对比较简单,也要求属性能够定位到唯一一个元素,如果存在多个相同条件的标签,默认只是第一个,具体格式:
xxx.By.xpath("//标签[@属性='属性值']")
属性判断条件:最常见为id,name,class等等,目前属性的类别没有特殊限制,只要能够唯一标识一个元素都是可以的
具体例子:
xxx.By.xpath("//a[@href='/industryMall/hall/industryIndex.html']")
xxx.By.xpath("//input[@value='确定']")
xxx.By.xpath("//div[@class = 'submit']/input")
(1)当某个属性不足以唯一区别某一个元素时,也可以采取多个条件组合的方式,具体例子
xxx..By.xpath("//input[@type='name' and @name='kw1']")
(2)当标签属性很少,不足以唯一区别元素时,但是标签中间中间存在唯一的文本值,也可以定位,其具体格式
xxx.By.xpath("//标签[contains(text(),'文本值')]")
具体例子:
xxx.By.xpath("//iunpt[contains(text(),'型号:')]")
注意:尽量在html中复制此段文本,避免因为肉眼无法分辨的字符导致定位失败
(3) 其他的属性值如果太长,也可以采取模糊方法定位,直接上示例
xxx.By.xpath(“//a[contains(@href, ‘logout')]”)
(4)XPath 关于网页中的动态属性的定位,例如,ASP.NET应用程序中动态生成id属性值,可以有以下四种方法:
- starts-with例子: //input[starts-with(@id,'ctrl')] 解析:匹配以ctrl开始的属性值 - ends-with 例子://input[ends-with(@id,'userName')] 解析:匹配以userName结尾的属性值 - contains() 例子://input[contains(@id,'userName')] 解析:匹配含有userName属性值
当然,如果上面的单一方法不能完成定位,也可以采取组合式定位 类似
("//input[@id='kw1']//input[start-with(@id,'nice']/div[1]/form[3])
(5) .//和//的区别
//是指从全文上下文中搜索//后面的节点,而.//则是指从前面的节点的子节点中进行查找
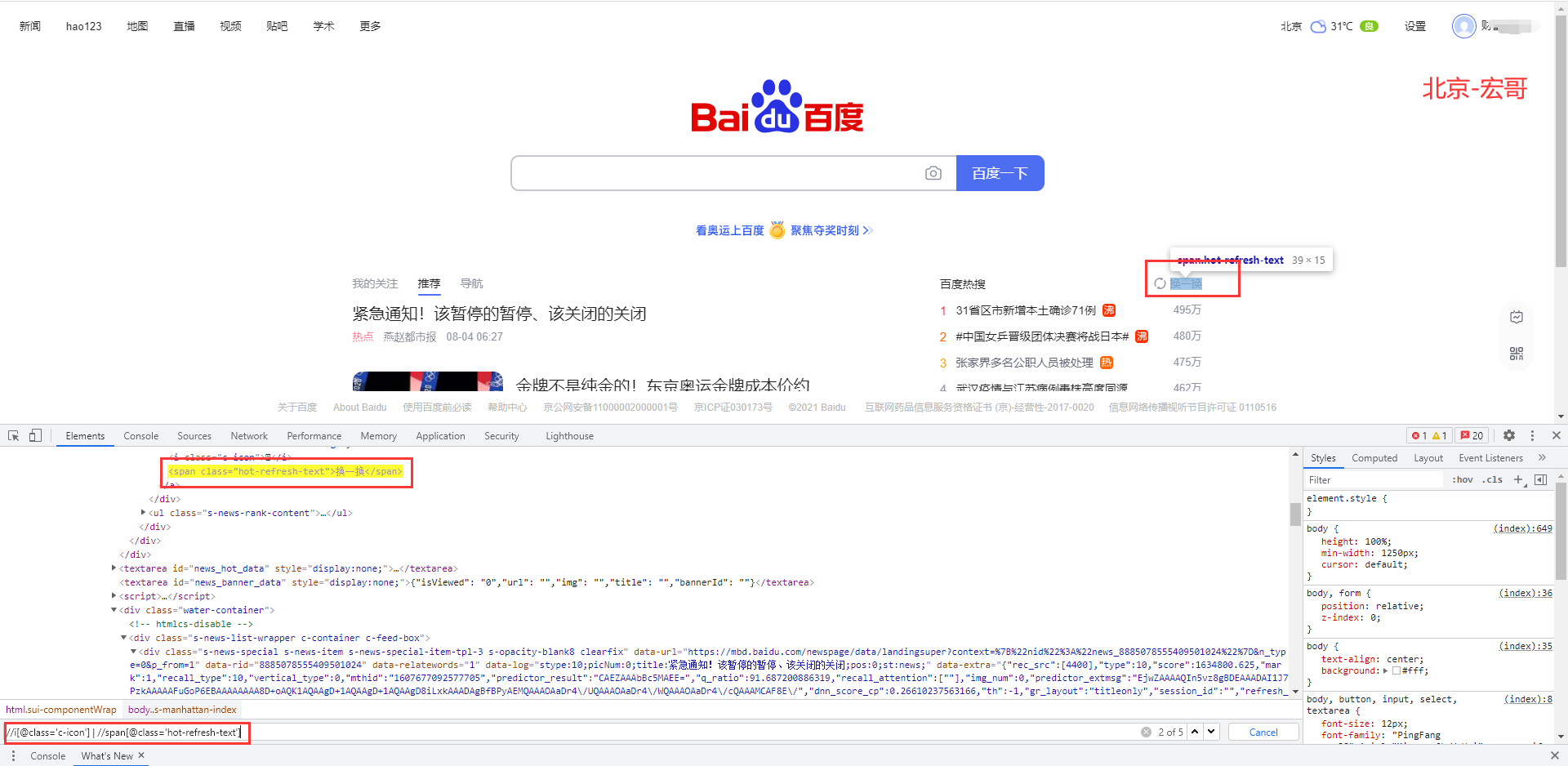
(6) 选取若干路径|
这个符号用于在一个xpath中写多个表达式用,用|分开,每个表达式互不干扰,意思是一个xpath可以匹配多个不同条件的元素,例如:如下图所示,xpath可以匹配到满足条件的i标签元素和满足条件的span标签元素。
//i[@class='c-icon'] | //span[@class='hot-refresh-text']
具体步骤:
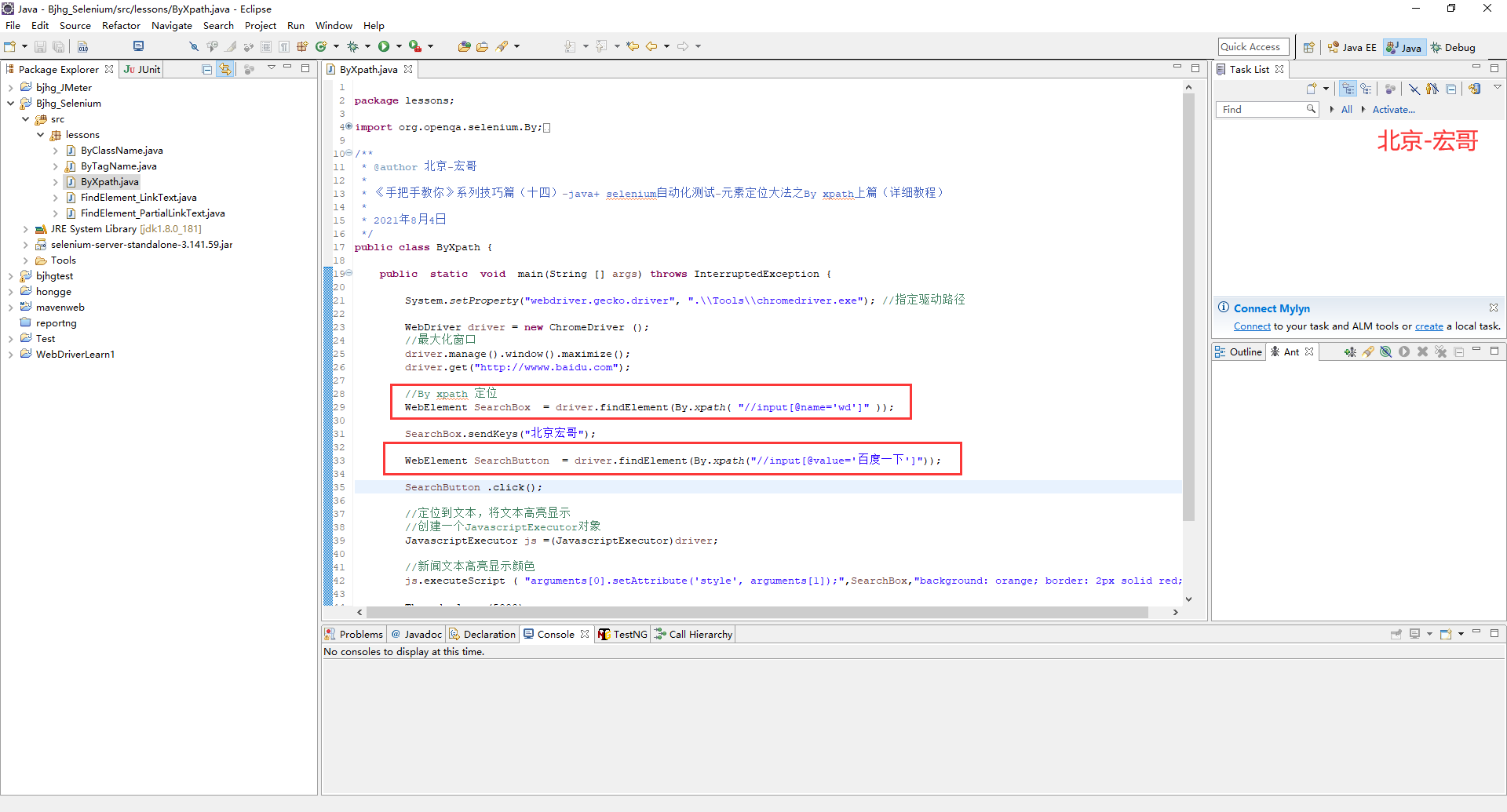
在被测试百度网页中,按照宏哥在上卷中5.2中的方法 (1)查找输入框并输入“北京宏哥”,(2)查找“百度一下”按钮,(3)点击“百度一下”按钮。因为上卷中的相对路径宏哥已经用了id,在这里宏哥就是用一下其他的属性。
XPath表达式:
(1)//input[@name='wd'] (2)//input[@value='百度一下']
java定位语句:
(1)WebElement searchBox = driver.findElement(By.xpath( "//input[@name='wd']" ));
(2)WebElement SearchButton = driver.findElement(By.xpath("//input[@value='百度一下']"));
5.3.1代码设计
5.3.2参考代码
package lessons; import org.openqa.selenium.By; import org.openqa.selenium.JavascriptExecutor; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; /** * @author 北京-宏哥 * * 《手把手教你》系列技巧篇(十四)-java+ selenium自动化测试-元素定位大法之By xpath上篇(详细教程) * * 2021年8月4日 */ public class ByXpath { public static void main(String [] args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", ".\Tools\chromedriver.exe"); //指定驱动路径 WebDriver driver = new ChromeDriver (); //最大化窗口 driver.manage().window().maximize(); driver.get("http://wwww.baidu.com"); //By xpath 定位 WebElement SearchBox = driver.findElement(By.xpath( "//input[@name='wd']" )); SearchBox.sendKeys("北京宏哥"); WebElement SearchButton = driver.findElement(By.xpath("//input[@value='百度一下']")); SearchButton .click(); //定位到文本,将文本高亮显示 //创建一个JavascriptExecutor对象 JavascriptExecutor js =(JavascriptExecutor)driver; //新闻文本高亮显示颜色 js.executeScript ( "arguments[0].setAttribute('style', arguments[1]);",SearchBox,"background: orange; border: 2px solid red;"); Thread.sleep (5000); driver.quit(); } }
5.3.3运行代码
1.运行代码,右键Run AS->java Application,控制台输出,如下图所示:
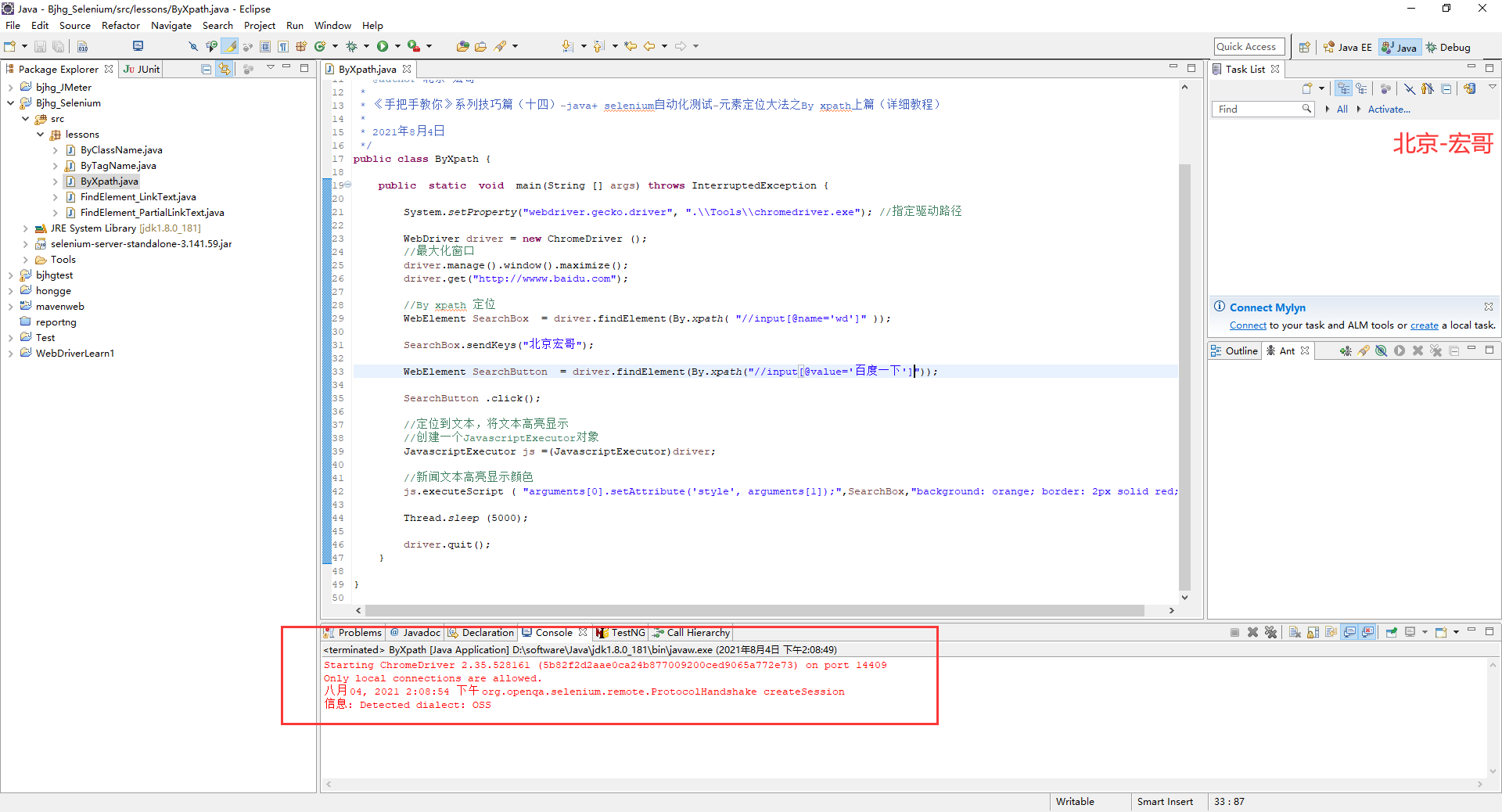
2.运行代码后电脑端的浏览器的动作,如下小视频所示:
在定位页面元素的时候,会遇到各种结构复杂的网页,并且经常出现无法使用ID,name等方式进行定位。有不想使用感觉对路径的定位方式,也没法搞清使用什么序号来定位元素,那么则推荐使用属性值定位元素的方法。
被测试网页的元素一般都包含各种各样的属性值,并且很多属性值具有唯一性。因此非常建议使用相对路径结合属性值定位的方式来编写XPath定位表达式,基于此定位方法可以解决大部分的页面元素定位问题。
5.4使用XPath的轴(Axis)进行元素定位
使用Aixs方法可依据在文档书中的元素相对位置关系进行定位。先找到一个相对好定位的元素,再根据这个元素和要定位的相对位置进行定位,可以解决一些元素难以定位的问题。
5.4.1轴示意图
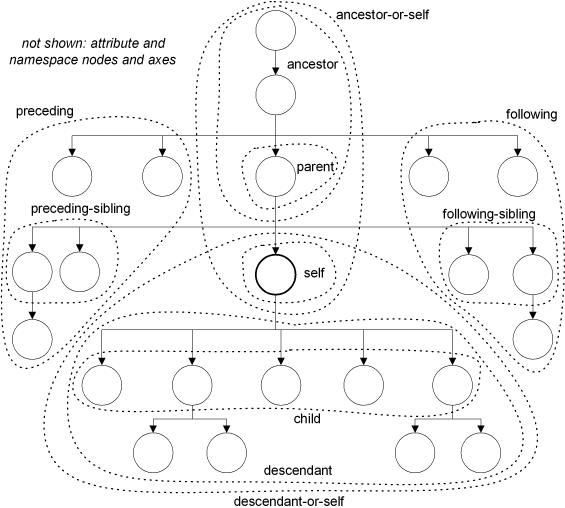
5.4.2XPath常用的关键字
XPath常用的关键字如下所示:
|
XPath轴关键字 |
轴含义 |
实例 |
表达式解释 |
|
ancestor |
选取当前节点的所有先辈(父、祖父等) |
//img[@alt=’div2-img2’]/ancestor::div |
查找alt属性值为div2-img的图片,并基于图片位置找到它的上级div页面元素。 |
|
ancestor-or-self |
选取当前节点的所有先辈(父、祖父等)以及当前节点本身 |
//img[@alt=’div2-img2’]/ ancestor-or-self::* |
查找alt属性值为div2-img的图片,并基于图片位置找到它全部上级元素,包括它本身。 |
|
attribute |
选取当前节点的所有属性 |
//img[@alt=’div2-img2’]/ attribute::* |
查找alt属性值为div2-img的图片并返回该节点下的所有属性节点 |
|
child |
选取当前节点的所有子元素。 |
//div[@id=’div1’]/child::img |
查找ID属性为div1的div页面元素,并基于div的位置找到它下层节点中的img页面元素 |
|
descendant |
选取当前节点的所有后代元素(子、孙等)。 |
//div[@name=’div2’]/ descendant::img |
查找name属性值为div2的元素,并基于div位置找到它下级的所有节点中的img页面元素。 |
|
descendant-or-self |
选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
//div[@name=’div2’]/ descendant::div |
查找name属性值为div2的元素,并基于div位置找到它下级的(包括自己)所有节点中的div页面元素。其实就是它本身。 |
|
following |
选取文档中当前节点的结束标签之后的所有节点。 |
//div[@id=’div1’]/ following::img |
查找到ID属性值为div1的div页面,并基于div找到它后面节点中的img页面元素 |
|
parent |
选取当前节点的父节点。 |
//img[@alt=’div2-img2’]/ parent::div |
查找到alt属性值为div2-img的图片并基于图片位置找到它上一级的div页面元素。 |
|
preceding |
选择当前节点前面的所有节点 |
//img[@alt=’div2-img2’]/preceding::div |
查找alt属性值为div2-img2的照片页面元素,并基于图片的位置找到它前面节点中的div页面元素。 |
|
preceding-sibling |
选取当前节点之前的所有同级节点。 |
//img[@alt=’div2-img2’]/ preceding-sibling::a[1] |
查找alt属性值为div2-img2的照片页面元素,并基于图片的位置找到它前面同级节点中的第二个链接页面元素 |
|
self |
选取当前节点。 |
5.4.3使用方法
轴名称::节点测试[谓语]
例如:
//form/div[last()-1]/ancestor::div[@class='modal-content']
5.4.4实践
1.descendant表示取当前节点的所有后代元素,宏哥演示定位百度首页的“百度一下”按钮,如下图所示: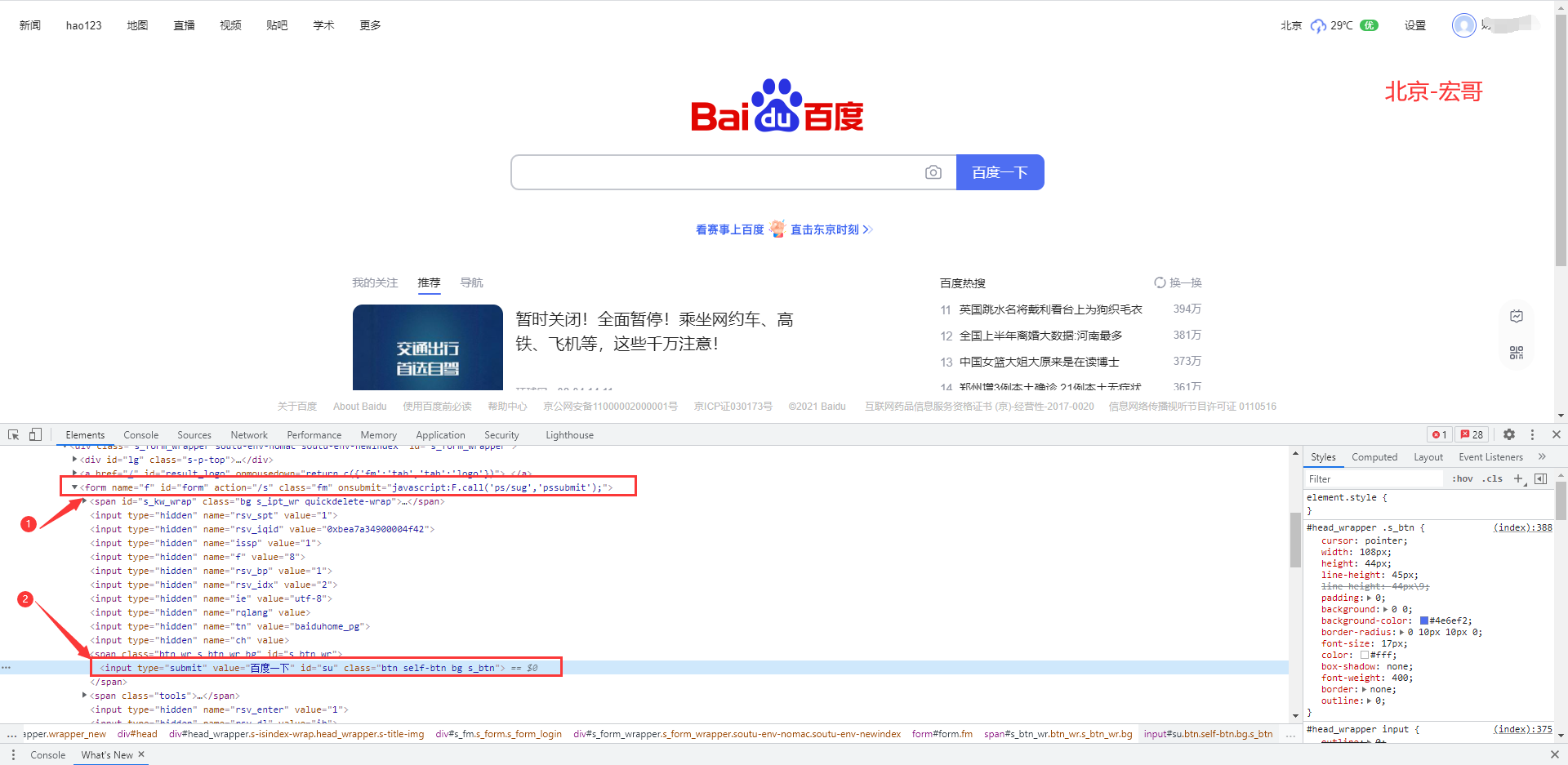
可以看到,input标签的父元素是span标签,而span标签的父元素是form标签,所以可以通过先定位form标签,然后利用descendant定位input标签
xpath路径如下:
//定位思路: //(1)form[@id='form']表示找到id属性为'form'的<form>标签, //(2)descendant::input表示找到<form>标签的所有后代<input>标签, //(3)然后通过[@id='su']精准定位到id属性为'su'的<input>标签 xpath= "//form[@id='form']/descendant::input[@id='su']"
把路径放到浏览器控制台,按下Ctrl+F,然后输入xpath路径,查看一下,确实定位到了标签(在执行程序之前,可以通过这种方式来验证一下写的xpath路径是否正确)

2.following表示选取当前节点结束标签之后的所有节点
注意这里说的是“结束标签之后”,所以在用这个轴进行定位时要看清目标标签的与辅助定位标签的层级关系,所以上例中就不能通过标签结合following来定位,因为标签在标签里面;

分析一下:input标签的上级是一个span标签,这个span标签上面也有一个span标签,可以通过它(span)来定位
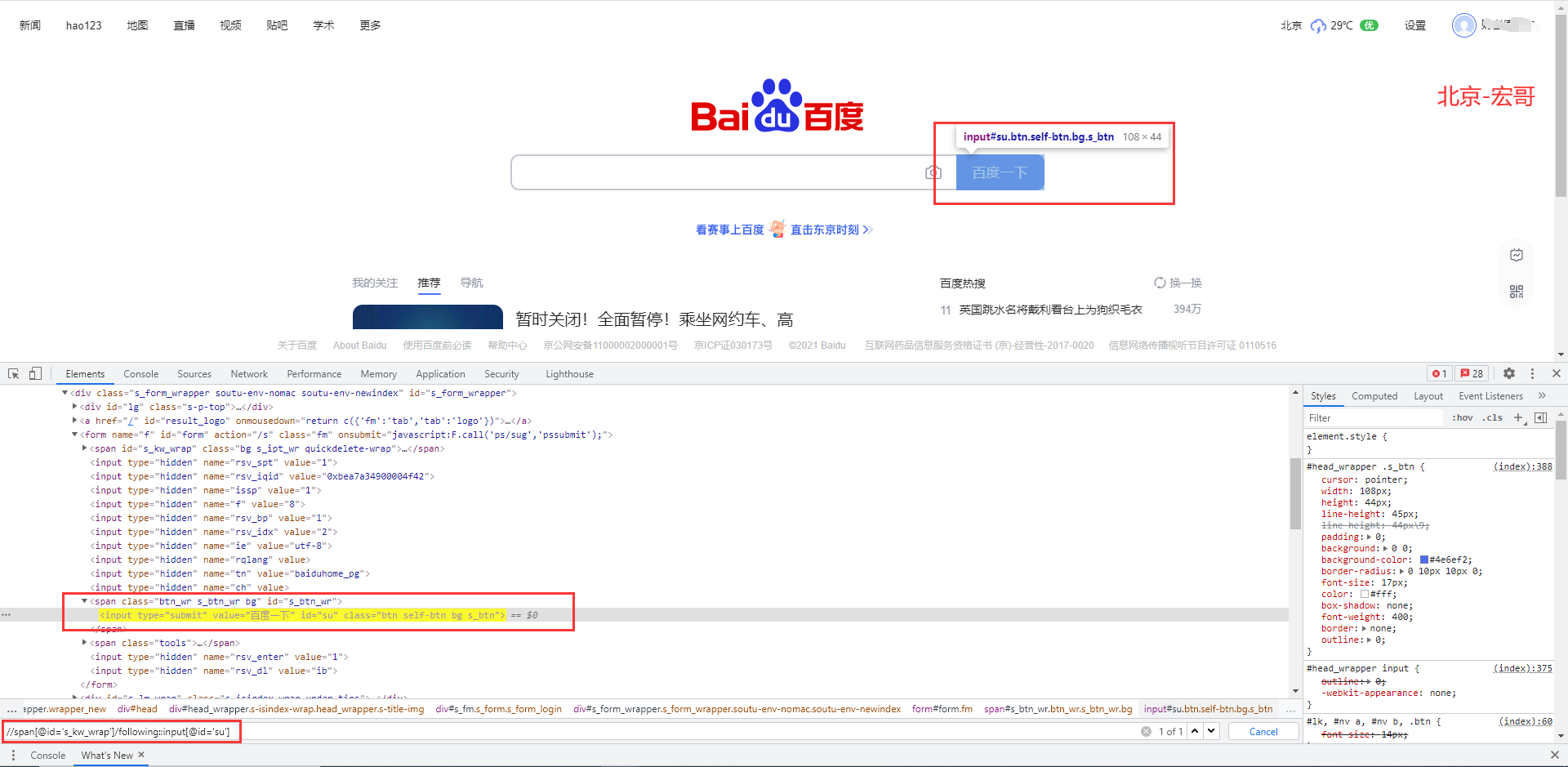
//定位思路: //(1)span[@id='s_kw_wrap']表示定位到id属性为s_kw_wrap的<span>标签, //(2)following::input[@id='su']表示找到<span>结束标签(即</span>)后的所有input标签, //(3)然后通过[@id='su']精准定位到id属性为'su'的<input>标签 xpath= "//span[@id='s_kw_wrap']/following::input[@id='su']"
按上边的方法,宏哥再次验证一下,成功定位到“百度一下”按钮,如下图所示:
3.parent可指定要查找的当前节点的直接父节点
例如,父节点是个div,即可写成parent::div,如果要找的元素不是直接父元素,则不可使用parent,可使用ancestor,代表父辈、祖父辈等节点,child::表示直接子节点元素,following-sibling只会标识出当前节点结束标签之后的兄弟节点,而不包含其他子节点;
以https://www.guru99.com/这个网站为例,如下图所示:

定位网页中的python:
//定位思路: //(1)先定位Java,然后找到Java的父节点li, //(2)然后再找li的兄弟节点,即包含Python的那个li标签, //(3)然后再找li的孩子节点,也就是a标签 xpath="//a[text()='Java']/parent::li/following-sibling::li/child::a[text()='Python']" //或者 xpath="//a[text()='Java']/parent::li/following-sibling::li[2]/a"
宏哥这里就不做验证了,有兴趣或者不信的小伙伴或者童鞋们,可以按照宏哥的方法自己验证一下。
6.小结
好了,今天分享的前边两种xpath的定位方法比较简单,第三种比较难一点,不过慢慢积累经验时间久了也就那么回事。今天到此宏哥就分享完了。后边还有一些,敬请期待。
7.拓展
① Xpath 定位扩展
使用通过子节点定位父节点
..代表父节点;../..爷爷节点
//span[contains(text(),'1.jpg')]/..
② Xpath 还支持布尔定位
Xpath = //input[@id='kw1' and @name='wd']
可以 and ,当然也可以 or :
Xpath = //input[@id='kw1' or @name='wd']

