实验原理
求平均数是MapReduce比较常见的算法,求平均数的算法也比较简单,一种思路是Map端读取数据,在数据输入到Reduce之前先经过shuffle,将map函数输出的key值相同的所有的value值形成一个集合value-list,然后将输入到Reduce端,Reduce端汇总并且统计记录数,然后作商即可。
实验步骤
1.在Linux中开启Hadoop
start-all.sh
2.在Linux本地新建/data/mapreduce4目录。
mkdir -p /data/mapreduce4
3.下载hadoop2lib,解压到mapreduce文件夹下
unzip hadoop2lib.zip
4.在HDFS上新建/mymapreduce4/in目录,然后将Linux本地/data/mapreduce4目录下的goods_click文件导入到HDFS的/mymapreduce4/in目录中。
hadoop fs -mkdir -p /mymapreduce4/in
hadoop fs -put /data/mapreduce4/goods_click /mymapreduce4/in
注意:goods_click文件需要注意文件格式,数据后有隐藏的空格会导致API中读取失败,行末尾的空格应该取消掉,中间使用逗号分隔开
5.在IDEA中编写代码
package mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class MyAverage{ public static class Map extends Mapper<Object , Text , Text , IntWritable>{ private static Text newKey=new Text(); public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ String line=value.toString(); System.out.println(line); String arr[]=line.split(","); newKey.set(arr[0]); int click=Integer.parseInt(arr[1]); context.write(newKey, new IntWritable(click)); } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{ public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{ int num=0; int count=0; for(IntWritable val:values){ num+=val.get(); count++; } int avg=num/count; context.write(key,new IntWritable(avg)); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{ Configuration conf=new Configuration(); System.out.println("start"); Job job =new Job(conf,"MyAverage"); job.setJarByClass(MyAverage.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path in=new Path("hdfs://192.168.149.10:9000/mymapreduce4/in/goods_click"); Path out=new Path("hdfs://192.168.149.10:9000/mymapreduce4/out"); FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
6.创建resources文件夹,其中创建log4j.properties文件
hadoop.root.logger=DEBUG, console log4j.rootLogger = DEBUG, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.out log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
7.导入hadoop2lib的包
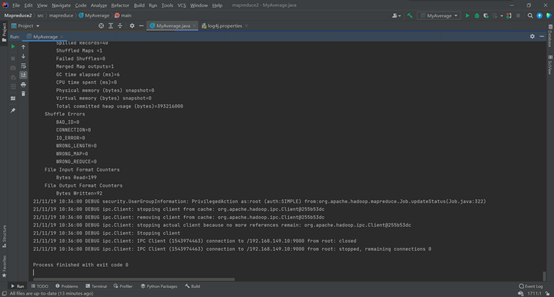
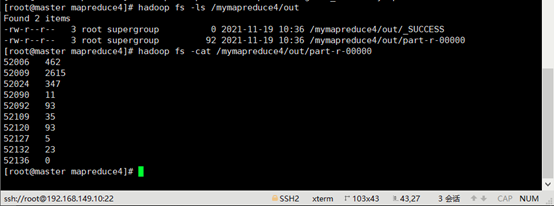
8.运行结果
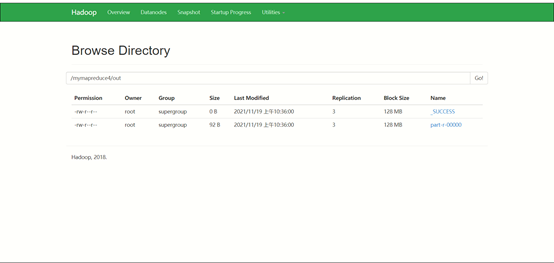
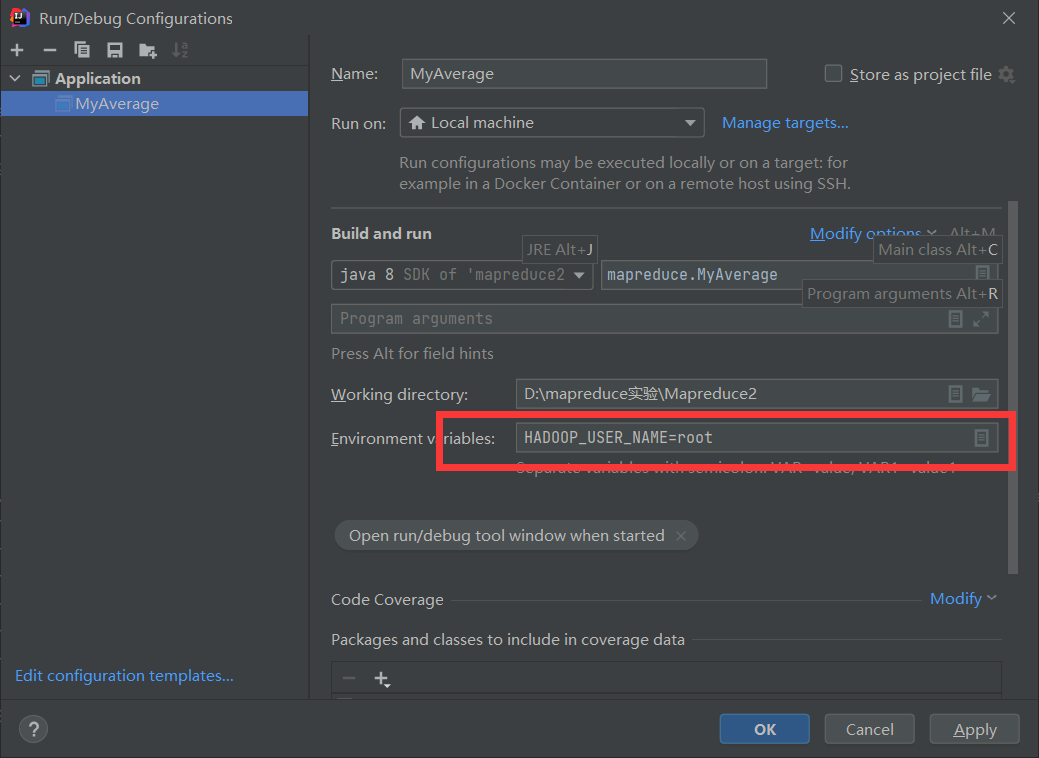
运行如果报权限错误,记得修改以下, root更换成你Linux中的用户名