一、Kafka相关术语解释
1)Broker Kafka集群包含一个或多个服务器,这种服务器被称为broker。broker端不维护数据的消费状态,提升 了性能。直接使用磁盘进行存储,线性读写,速度快:避免了数据在JVM内存和系统内存之间的复制, 减少耗性能的创建对象和垃圾回收。 2)Producer 负责发布消息到Kafka broker 3)Consumer 消息消费者,向Kafka broker读取消息的客户端,consumer从broker拉取(pull)数据并进行处理。 4)Topic 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存 储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消 费数据而不必关心数据存于何处) 5)Partition Parition是物理上的概念,每个Topic包含一个或多个Partition. 6)Consumer Group 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定 group name则属于默认的group)
7)Topic & Partition Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把 这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个 Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文 件。若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个 文件夹(本文所用集群共8个节点,此处topic1和topic2 replication-factor均为1)。
二、Kafka集群环境安装
1、kafka下载地址:http://kafka.apache.org/downloads.html
2、本文演示版本:https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
3、选择一个目录:/usr/local/kafka
4、进入目录:/usr/local/kafka下载https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
5、/usr/local/kafka目录中执行:tar -zxvf kafka_2.11-2.0.0.tgz。解压后如下目录

6、cd /usr/local/kafka/kafka_2.11-2.0.0
7、cd /usr/local/kafka/kafka_2.11-2.0.0/config
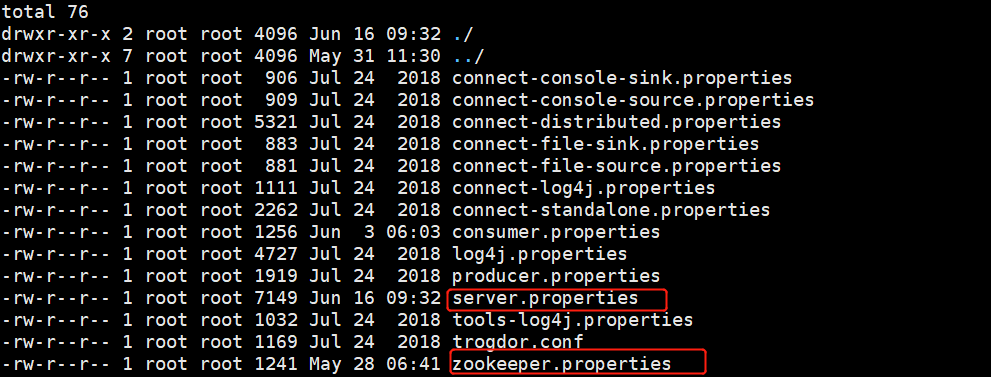
编辑以上两个文件
server.properties


#更多参数配置参考以下两位作者 #https://zhuanlan.zhihu.com/p/137720038 #https://www.cnblogs.com/weixiuli/p/6413109.html ############################# 服务基本配置 ############################# #指定kafka在集群中的broker_id broker.id=1 #broker.id.generation.enable=true ############################# 服务Socket配置 ############################# #以下两个参数参考作者:https://juejin.cn/post/6893410969611927566 listeners=PLAINTEXT://192.168.10.33:9092 #外部通信地址,例如zk需要此地址,没有就用listeners advertised.listeners=PLAINTEXT://192.168.10.33:9092 #该参数指定了fetch线程的数量(从源broker中复制消息的fetch线程),默认值: 1。其实可以适当的调整大一些,可以增强副本之前的同步效率。 #num.replica.fetchers=1 #broker处理请求的 IO 线程数,需要考虑到磁盘的IO状况。默认值为:8 #num.io.threads=8 #指定broker用来接收来自网络的请求和发送网络的响应的线程数,默认值为: 3 num.network.threads=3 #后台任务处理线程数(例如过期消息删除等)。默认值为:10 #background.threads=10 #socket发送缓冲区大小,避免磁盘IO socket.send.buffer.bytes=102400 #socket接受缓冲区大小,避免磁盘IO socket.receive.buffer.bytes=102400 #socket请求最大的字节数,决定了单次发送消息体(Requet PayLoad)的大小 socket.request.max.bytes=104857600 ############################# 日志配置 ############################# #kafka日志数据目录,也可以配置多个目录地址。可以如下配置多个。 #log.dirs=/exoprt/kafka1,/export/kafka2,/export/kafka3 log.dirs=/tmp/kafka-logs #指定topic的分区数量,一般设置3个足够负载 #默认是2 num.partitions=3 #适用于自动创建的主题的默认复制因子,推荐至少设置为2,默认为1 #配置此参数必须明确kafka broker的数量,否则创建topic会失败。 #default.replication.factor=1 #服务在正常启动、崩溃重启、正常关闭的时候处理每个日志目录的线程数量 #例如:打开日志片段、检查截取分区日志、关闭日志片段。 #所以这个可是适当结合服务器参数尽量调大一些,因为这些线程分配是在服务的加载和退出会被分配,运行中不会占用资源。这个会加快服务的重启,退出的执行速度。 #设置此参数时需要注意,所配置的数字对应的是 log.dirs 指定的单个日志目录。也就是说,如果 num.recovery.threads.per.data.dir 被设为 8,并且 log.dir 指定了 3 个路径,那么总共需要 24 个线程。 #默认是1 num.recovery.threads.per.data.dir=6 ############################# Topic配置参数 ############################# #系统主题:__consumer_offsets和__transaction_state用于创建的分区和副本相关的参数 #指定__consumer_offsets主题的副本数量。配置此参数前,请了解kafka集群节点数。 offsets.topic.replication.factor=1 #指定__transaction_state主题的副本数量。配置此参数前,请了解kafka集群节点数。 transaction.state.log.replication.factor=1 #指定__transaction_state主题的isr数量,用于producer ack的程度,以及leader选举的目标对象。 transaction.state.log.min.isr=1 #关闭自动创建topic,表示无法通过客户端比如:java代码程序创建Topic,必须通过命令在kafka服务器创建Topic。 #推荐是设置成false,不允许客户端直接创建topic,否则topic会无法管理。默认值为true。 #创建主题的3个机制 ##当一个生产者开始往主题写入消息时 ##当一个消费者开始从主题读取消息时 ##当任意一个客户端向主题发送元数据请求时 auto.create.topics.enable=false #设置删除topic同时会移除kafka日志文件以及zookeeper目录结构。 #是否允许删除topic,默认为: true。 #如果为false,通过管理工具删除topic仅为标记删除,此时使用describe命令可以查看到topic的详情信息,但是无法写入,可以通过删除zk中的节点来删除。 #生产环境建议设置为false,由集群管理员定期统一的进行删除和管理。 delete.topic.enable=true #该值表示kafka允许的最大的batch大小(不是单个message的大小),默认值为1000012,即1Mb. #Topic级别参数 #message.max.bytes ############################# 日志刷盘策略 ############################# #分区上的消息数量超过多少数量,就触发刷盘。默认:9223372036854775807 #log.flush.interval.messages=10000 #每隔多少ms出发强制刷盘。 #主题中的消息在刷新到磁盘之前保存在内存中的最大时间,默认为null。 #log.flush.interval.ms=1000 #日志刷新器检查是否需要将日志刷新到磁盘的频率,默认9223372036854775807 #log.flush.scheduler.interval.ms=9223372036854775807 ############################# 日志失效设置 ############################# #设置topic消息的有效时间,查过这个时间的消息将会被移除失效。 #默认168小时=1周 单位:hours或者ms 小时或者毫秒 #log.retention.minutes 分钟 #log.retention.hours 小时 #毫秒 log.retention.ms=30000 #每个分区保留消息的大小,如果有一个包含 8 个分区的主题,并且 log.retention.bytes 被设为 1GB,那么这个主题最多可以保留 8GB 的数据。 #log.retention.bytes=1073741824 #指定每个日志段的大小,通常在消息到达broker时,会被追加到分区的当前日志段上(segment), #当日志段大小超过该参数指定的值(默认1GB),当前日志段就会被关闭,一个新的日志段被打开。 log.segment.bytes=1073741824 #日志清理器检查日志是否符合删除条件的频率,默认为300000。 log.retention.check.interval.ms=300000 ############################# Zookeeper配置 ############################# #zookeeper服务器配置 zookeeper.connect=192.168.10.33:2181,192.168.10.34:2181 #zookeeper连接超时时间ms zookeeper.connection.timeout.ms=6000 ############################# 消费组配置 ############################# #注册消费者允许的最小会话超时,默认:6000ms。消费组重平衡的延迟时间。 group.initial.rebalance.delay.ms=0 #消费组中最大消费者数量 #group.max.size=6 ############################# Partition重平衡策略 ############################# auto.leader.rebalance.enable=true # 对应影响的其他两个参数 # leader.imbalance.per.broker.percentage : 每个broker允许leader不平衡比例(如果每个broker上超过了这个值,controller将会>执行分区再平衡),默认值10. # leader.imbalance.check.interval.seconds: 主分区再平衡的频率,默认值为300s #指定ISR副本的数量,配合生产者ack参数(-1:需要保证isr中全部写入成功,0:不需要保证isr中写入成功,1:需要保证isr中任意一个写入成功)一起使用,可以加强整个消息的持久性。 #当使用required.acks=-1(all)提交到生产请求所需的ISR中的最小副本数,默认为1,建议在数据一致性要求较高的topic中设置至少为2。 #min.insync.replicas=1 #是否启用不在ISR集中的副本以选作领导者,默认值是false。即使这样做可能会导致数据丢失。该参数可以提高整体Topic的可用性,但是可能会造成数据的整体不一致性(部分数据的丢失)。 #为false,就只从ISR中获取leader保证了数据的可靠性,但是partition就失效了,true则从replica中获取,则可用性增强,但是数>据可能存在丢失情况 #false强制从isr中选取新的leader。 #true不会强制从isr中选取新的leader,如果isr中没有就从非isr中的副本选取leader。 #unclean.leader.election.enable=false
zookeeper.properties
#数据目录 注意当前目录如果不存在在启动前必须要手动创建好
dataDir=/tmp/kafka/zookeeper
#日志目录 dataLogDir=/tmp/kafka/log/zookeeper clientPort=2181 maxClientCnxns=100 tickTime=2000 initLimit=10 syncLimit=5
#以下配置zk集群的所有节点server.1=server.{myid}。myid是手动创建的在上面dataDir目录下创建的myid文件里面写着各自的zk节点ID。这个ID就是server后面的整数值。 server.1=192.168.10.33:2888:3888 server.2=192.168.10.34:2888:3888
8、进入 /tmp/kafka/zookeeper创建myid文件,记住有多少个zk集群每个服务器都需要同样的操作,只是myid内容不一样。


9、以上1-8过程需要在集群中的每个服务节点操作一遍。
10、启动kafka和zk集群环境,进入解压后的kafka目录->/usr/local/kafka/kafka_2.11-2.0.0/bin。
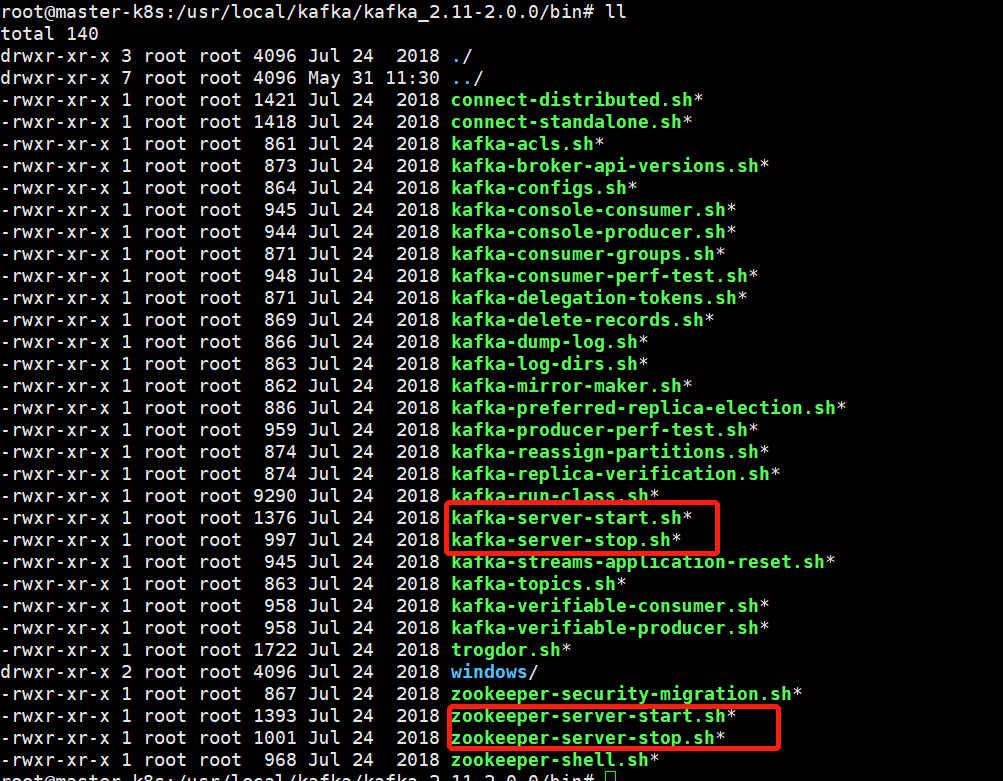
11、先启动每台机器上的zookeeper然后启动每台机器上的kafka。
#启动zookeeper 后台启动 nohup /usr/local/kafka/kafka_2.11-2.0.0/bin/zookeeper-server-start.sh config/zookeeper.properties >zk.log &
#停止zookeeper /usr/local/kafka/kafka_2.11-2.0.0/bin/zookeeper-server-stop.sh
#启动kafka 后台启动 nohup /usr/local/kafka/kafka_2.11-2.0.0/bin/kafka-server-start.sh config/server.properties >kafka.log &
#第二种方式
./bin/kafka-server-start.sh –daemon config/server.properties >kafka.log &
#停止kafka /usr/local/kafka/kafka_2.11-2.0.0/bin/kafka-server-stop.sh
三、kafka常用操作命令
1、创建topic指定分区副本数
sh kafka-topics.sh --create --zookeeper 192.168.10.33:2181,192.168.10.34:2181 --topic test-topic --partitions 2 --replication-factor 2
2、发送消息
sh kafka-console-producer.sh --broker-list 192.168.10.33:9092,192.168.10.34:9092 --topic test-topic-partition-1
3、消费消息
sh kafka-console-consumer.sh --bootstrap-server 192.168.10.33:9092 --topic test-topic --from-beginning
--from-beginning表示从头开始消费
4、消费消息(指定消费组Group)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.10.33:9092,192.168.10.34:9092 --topic test-topic-89 --from-beginning --group your-group-name
5、查看消费组列表
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.10.33:9092,192.168.10.34:9092 --list

6、查看消费组分区各个分区消费情况
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.10.33:9092,192.168.10.34:9092 --describe --group 666666

7、查看topic属性
./bin/kafka-topics.sh --describe --zookeeper 192.168.10.33:2181,192.168.10.34:2181 --topic topicName

Topic:主题名称。 Leader:当前分区的leader broker id在配置kafka集群的时候有设置。 Replicas:所有副本在broker分布情况。1,2表示分辨分布在1和2的broker上面。 Isr: 所有副本中跟分区leader数据同步最接近的几个副本。便于leader的重新选举,优先考虑Isr列表中的副本。当然也可以设置不从这里面选举leader。
8、查看所有topic列表
sh /usr/local/kafka/kafka_2.11-2.0.0/bin/kafka-topics.sh --list --zookeeper 192.168.10.33:2181,192.168.10.34:2181

9、删除topic
sh /usr/local/kafka/kafka_2.11-2.0.0/bin/kafka-topics.sh --delete --zookeeper 192.168.10.33:2181,192.168.10.34:2181 --topic test-topic
注意:
彻底删除topic: 1、删除kafka存储目录(server.properties文件log.dirs配置,默认为"/tmp/kafka-logs")相关topic目录 2、如果配置了delete.topic.enable=true直接通过命令删除,如果命令删除不掉,直接通过zookeeper-client 删除掉broker下的topic即可。
10、查询topic所有分区消息列表
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.10.33:9092,192.168.10.34:9092 --topic test-topic-89 --time -1

11、查询__consumer_offsets主题具体分区消息
执行一下命令前,需要设置kafka的config中consumer.properties中exclude.internal.topics=false,无需重启kafka会自动生效。
bin/kafka-console-consumer.sh --topic __consumer_offsets --partition 11 --bootstrap-server 192.168.10.33:9092,192.168.10.34:9092 --formatter "kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning

以上是监听了消费组TestMsgConsumer-666666-6在_consumer_offset提交offset的记录。为什么在没有任何消息消费的情况下消费端不断的向_consumer_offset的partition_49写消息呢。
那是因为消费端设置的了自动提交:spring.kafka.consumer.enable-auto-commit=true。从而这也说明了一个自动提交的问题,那就是相比手动提交自动提交会占用性能。而且会浪费kafka磁盘空间。
当然kafka也会有自己的策略去移除这些重复的消息,那就是kafka的压缩清理机制。会对相同的key做压缩。
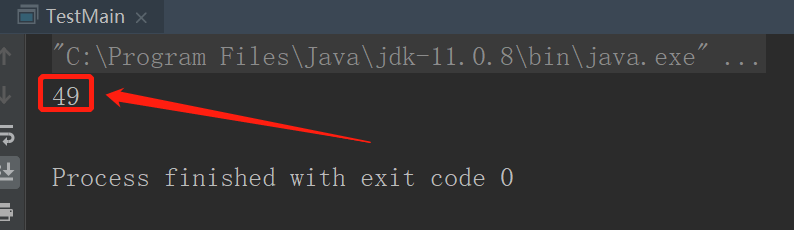
怎么知道TestMsgConsumer-666666-6消费组上传的_consumer_offset主题的分区就是49,其实很简单看下面的算法。_consumer_offset主题默认分区0-49共50个分区。以下黄色区域

/** * @Auther: ShouZhi@Duan * @Description: */ public class TestMain { public static void main(String[] args) { //消费者offset分区保存算法 System.out.println(Math.abs("TestMsgConsumer-666666-6".hashCode())%50); } }
12、修改已创建topic的分区数量
sh kafka-topics.sh --zookeeper 192.168.10.33:2181,192.168.10.34:2181 --topic test-topic-fix --partitions 2 --alter
#修改分区数量(一般不建议修改,在创建topic的时候就指定好) 发送消息 sh kafka-console-producer.sh --broker-list 192.168.10.33:9092,192.168.10.34:9092 --topic test-topic-fix 查看: sh kafka-topics.sh --describe --zookeeper 192.168.10.33:2181,192.168.10.34:2181 --topic test-topic-fix Topic:test-topic-fix PartitionCount:1 ReplicationFactor:1 Configs: Topic: test-topic-fix Partition: 0 Leader: 2 Replicas: 2 Isr: 2 修改:(分区只能调整增加,不能修改减少分区相对原来的分区数) sh kafka-topics.sh --zookeeper 192.168.10.33:2181,192.168.10.34:2181 --topic test-topic-fix --partitions 2 --alter
如何对新增后的分区,重新分配负载历史已有的消息?(需要手动操作)
#kafka扩容后的分区重新负载分配(或者调整副本数量,这里可以增加或者减少副本数量),手动操作。 参考博主:https://blog.csdn.net/CREATE_17/article/details/110212789
13、查看已安装kafka版本
进入kafka安装目录libs
find ./libs/ -name *kafka_* | head -1 | grep -o 'kafka[^ ]*'

kafka_2.11-2.0.0.jar.asc
红色表示scala版本
绿色表示kafka版本
四、kafka可视化工具
1、下载地址:https://www.kafkatool.com/download.html(https://www.kafkatool.com/download2/offsetexplorer_64bit.exe)
下载:offsetexplorer_64bit.exe
链接:https://pan.baidu.com/s/1G_ZaHBpRiPNSAB9wjDM1iA
提取码:1vos
提取码若失效,联系微信号(duanshouzhi516518)

双击安装就好了
2、简单实用教程



以上就大概的用法,具体大家安装好后大家多点点就清楚了。