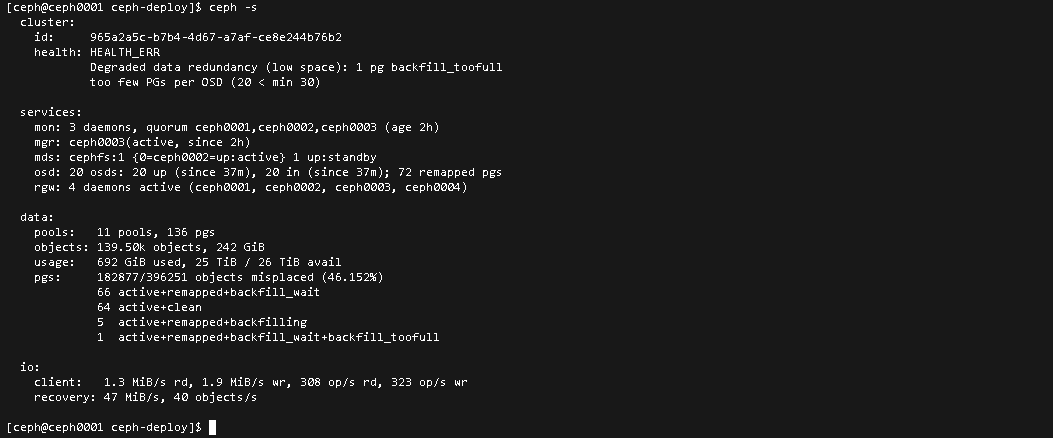
[ceph@ceph0001 ceph-deploy]$ ceph -s
cluster:
id: 965a2a5c-b7b4-4d67-a7af-ce8e244b76b2
health: HEALTH_ERR
Degraded data redundancy (low space): 1 pg backfill_toofull
too few PGs per OSD (20 < min 30)
services:
mon: 3 daemons, quorum ceph0001,ceph0002,ceph0003 (age 2h)
mgr: ceph0003(active, since 2h)
mds: cephfs:1 {0=ceph0002=up:active} 1 up:standby
osd: 20 osds: 20 up (since 37m), 20 in (since 37m); 72 remapped pgs
rgw: 4 daemons active (ceph0001, ceph0002, ceph0003, ceph0004)
data:
pools: 11 pools, 136 pgs
objects: 139.50k objects, 242 GiB
usage: 692 GiB used, 25 TiB / 26 TiB avail
pgs: 182877/396251 objects misplaced (46.152%)
66 active+remapped+backfill_wait
64 active+clean
5 active+remapped+backfilling
1 active+remapped+backfill_wait+backfill_toofull
io:
client: 1.3 MiB/s rd, 1.9 MiB/s wr, 308 op/s rd, 323 op/s wr
recovery: 47 MiB/s, 40 objects/s
[ceph@ceph0001 ceph-deploy]$ ceph health detail
HEALTH_ERR Degraded data redundancy (low space): 1 pg backfill_toofull; too few PGs per OSD (20 < min 30)
PG_DEGRADED_FULL Degraded data redundancy (low space): 1 pg backfill_toofull
pg 2.18 is active+remapped+backfill_wait+backfill_toofull, acting [3,1,2]
TOO_FEW_PGS too few PGs per OSD (20 < min 30)
慢慢等回填完,逐渐降下去

