https://blog.cloudflare.com/zh-cn/when-tcp-sockets-refuse-to-die-zh-cn/
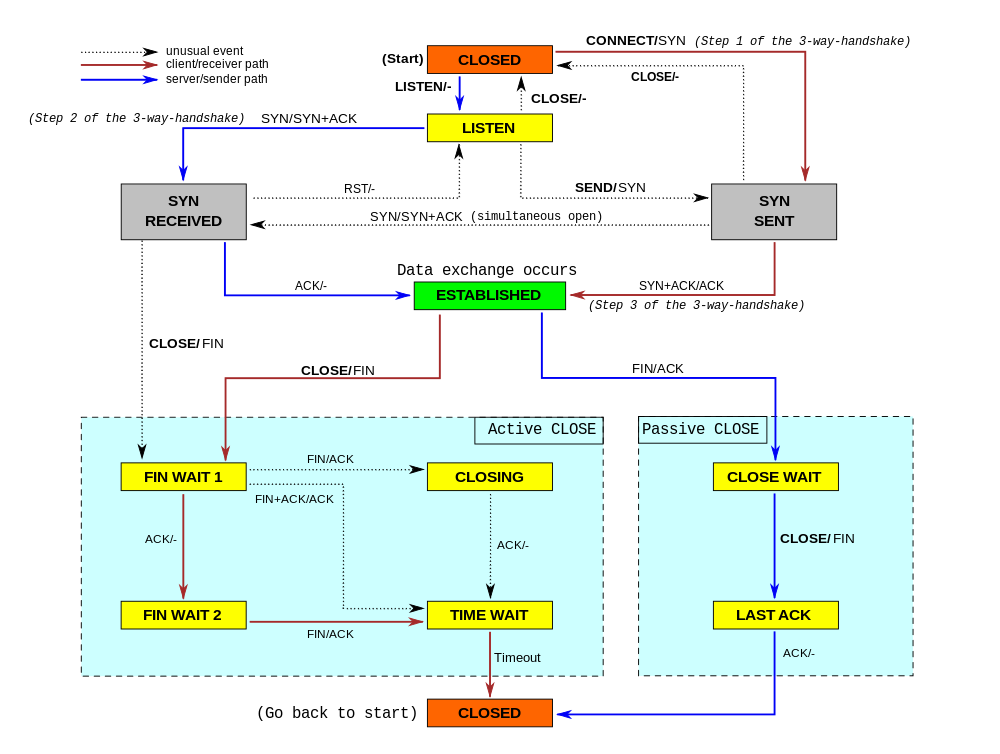
在我们的Spectrum服务器上工作时,我们注意到了一些奇怪的现象:我们认为应该关闭了的TCP套接字一直在徘徊。我们意识到我们并不真正了解TCP套接字何时应该超时!
 图像 来自 Sergiodc2 CC BY SA 3.0
图像 来自 Sergiodc2 CC BY SA 3.0
在我们的代码中,我们想确保我们不保持与死主机的连接。在我们早期的代码中,我们天真地认为启用TCP keepalives就足够了……但事实并非如此。事实证明,相当现代的TCP_USER_TIMEOUT套接字选项同样重要。此外,它以微妙的方式与TCP Keepalive交互。许多人对此感到困惑。
在这篇博客文章中,我们将尝试展示这些选项是如何工作的。我们将展示一个TCP套接字如何在其生命周期的不同阶段超时,以及TCP keepalives和用户超时如何影响它。为了更好地说明TCP连接的内部机制,我们将混合使用tcpdump和ss -o命令的输出。这很好地显示了传输的数据包和TCP连接的变化参数。
同步发送
让我们从最简单的情况开始——当一个人试图与服务器建立连接并丢弃入站SYN数据包时会发生什么?
这里使用的脚本可以在我们的Github上找到。
$ sudo ./test-syn-sent.py
# all packets dropped
00:00.000 IP host.2 > host.1: Flags [S] # initial SYN
State Recv-Q Send-Q Local:Port Peer:Port
SYN-SENT 0 1 host:2 host:1 timer:(on,940ms,0)
00:01.028 IP host.2 > host.1: Flags [S] # first retry
00:03.044 IP host.2 > host.1: Flags [S] # second retry
00:07.236 IP host.2 > host.1: Flags [S] # third retry
00:15.427 IP host.2 > host.1: Flags [S] # fourth retry
00:31.560 IP host.2 > host.1: Flags [S] # fifth retry
01:04.324 IP host.2 > host.1: Flags [S] # sixth retry
02:10.000 connect ETIMEDOUT好吧,这很简单。在connect()系统调用之后,操作系统会发送一个SYN包。由于它没有得到任何响应,操作系统将默认重试发送6次。(重发次数)可以通过sysctl进行调整:
$ sysctl net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6可以用TCP_SYNCNT setsockopt覆盖每个套接字的这一设置:
setsockopt(SD,IPPROTO_TCP,TCP_SYNCNT,6);重试在1s、3s、7s、15s、31s、63s标记处错列进行(中间重试时间从2s开始,然后每次加倍)。默认情况下,整个过程需要130秒,直到内核放弃而返回errno值——ETIMEDOUT。在连接的生命周期中,SO_KEEPALIVE设置将被忽略,而TCP_USER_TIMEOUT却没有。例如,将其设置为5000ms,将导致以下交互:
import io import os import select import socket import time import utils utils.new_ns() port = 1 tcpdump = utils.tcpdump_start(port) c = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) t0 = time.time() utils.drop_start(dport=port) if True: #c.setsockopt(socket.IPPROTO_TCP, socket.SO_RCVTIMEO, 5*1000) c.setsockopt(socket.IPPROTO_TCP, socket.TCP_USER_TIMEOUT, 5*1000) # speedup # os.system('sysctl net.ipv4.tcp_syn_retries=4') if False: c.setblocking(False) try: c.connect(('127.0.0.1', port)) except io.BlockingIOError: pass c.setblocking(True) utils.ss(port) time.sleep(1) utils.ss(port) time.sleep(3) utils.ss(port) poll = select.poll() poll.register(c, select.POLLOUT) poll.poll() utils.ss(port) else: try: c.connect(('127.0.0.1', port)) except Exception as e: print(e) e = c.getsockopt(socket.SOL_SOCKET, socket.SO_ERROR) print("[ ] SO_ERROR = %s" % (e,)) t1 = time.time() print("[ ] connect took %fs" % (t1-t0,))
root@ubuntu:~/cloudflare-blog/2019-09-tcp-keepalives# python3 test-syn-sent.py tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes 00:00:00.000000 IP 127.0.0.1.45994 > 127.0.0.1.1: Flags [S], seq 1272597214, win 65495, options [mss 65495,sackOK,TS val 4238569449 ecr 0,nop,wscale 7], length 0 00:00:01.015081 IP 127.0.0.1.45994 > 127.0.0.1.1: Flags [S], seq 1272597214, win 65495, options [mss 65495,sackOK,TS val 4238570465 ecr 0,nop,wscale 7], length 0 00:00:03.031088 IP 127.0.0.1.45994 > 127.0.0.1.1: Flags [S], seq 1272597214, win 65495, options [mss 65495,sackOK,TS val 4238572481 ecr 0,nop,wscale 7], length 0 00:00:05.015044 IP 127.0.0.1.45994 > 127.0.0.1.1: Flags [S], seq 1272597214, win 65495, options [mss 65495,sackOK,TS val 4238574465 ecr 0,nop,wscale 7], length 0 00:00:05.023012 IP 127.0.0.1.45994 > 127.0.0.1.1: Flags [S], seq 1272597214, win 65495, options [mss 65495,sackOK,TS val 4238574473 ecr 0,nop,wscale 7], length 0 00:00:05.031011 IP 127.0.0.1.45994 > 127.0.0.1.1: Flags [S], seq 1272597214, win 65495, options [mss 65495,sackOK,TS val 4238574481 ecr 0,nop,wscale 7], length 0 00:00:05.039011 IP 127.0.0.1.45994 > 127.0.0.1.1: Flags [S], seq 1272597214, win 65495, options [mss 65495,sackOK,TS val 4238574489 ecr 0,nop,wscale 7], length 0 [Errno 110] Connection timed out [ ] SO_ERROR = 0 [ ] connect took 5.053116s 7 packets captured 14 packets received by filter 0 packets dropped by kernel
即使我们将用户超时设置为5s,我们仍然可以看到6次SYN重试。这种行为可能是一个bug(已在5.2内核上进行了测试):我们预计只会发送两次重试——在1s和3s标记处,套接字将在5s标记处终止。相反,我们看到了这一点,但我们还看到了另外4个重传的SYN数据包对齐到了5s标记处——这是没有意义的。无论如何,我们学到了一件事——TCP_USER_TIMEOUT确实会影响connect()的行为。
同步接收
SYN-RECV(同步接收)套接字通常对应用程序是隐藏的。它们以微型套接字的形式存在于SYN队列中。我们曾写过有关SYN和Accept队列的内容。有时,当SYN cookie被启用,套接字可能完全跳过synrecv状态。
在SYN-RECV状态下,套接字将重试发送SYN + ACK 5次,具体取决于:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5这就是它在wire中看起来的样子:
$ sudo ./test-syn-recv.py
00:00.000 IP host.2 > host.1: Flags [S]
# all subsequent packets dropped
00:00.000 IP host.1 > host.2: Flags [S.] # initial SYN+ACK
State Recv-Q Send-Q Local:Port Peer:Port
SYN-RECV 0 0 host:1 host:2 timer:(on,996ms,0)
00:01.033 IP host.1 > host.2: Flags [S.] # first retry
00:03.045 IP host.1 > host.2: Flags [S.] # second retry
00:07.301 IP host.1 > host.2: Flags [S.] # third retry
00:15.493 IP host.1 > host.2: Flags [S.] # fourth retry
00:31.621 IP host.1 > host.2: Flags [S.] # fifth retry
01:04:610 SYN-RECV disappears使用默认设置,SYN+ACK在1s、3s、7s、15s、31s标记处重新传输,而SYN-RECV套接字在64s标记处消失。
SO_KEEPALIVE和TCP_USER_TIMEOUT都不影响SYN-RECV套接字的生命周期。
最终握手ACK
在接收到TCP握手中的第二个数据包(SYN+ACK)后,客户端套接字转移到ESTABLISHED(已建立)的状态。服务器套接字保持在SYN-RECV中,直到收到最终的ACK数据包为止。
丢失此ACK包不会改变任何内容——只是服务器套接字从SYN-RECV移动到ESTAB所需的时间要更长一点而已。它看起来是这样的:
00:00.000 IP host.2 > host.1: Flags [S]
00:00.000 IP host.1 > host.2: Flags [S.]
00:00.000 IP host.2 > host.1: Flags [.] # initial ACK, dropped
State Recv-Q Send-Q Local:Port Peer:Port
SYN-RECV 0 0 host:1 host:2 timer:(on,1sec,0)
ESTAB 0 0 host:2 host:1
00:01.014 IP host.1 > host.2: Flags [S.]
00:01.014 IP host.2 > host.1: Flags [.] # retried ACK, dropped
State Recv-Q Send-Q Local:Port Peer:Port
SYN-RECV 0 0 host:1 host:2 timer:(on,1.012ms,1)
ESTAB 0 0 host:2 host:1如你所见,SYN-RECV具有“on”计时器,与前面的示例一样。我们可能会争辩道,最后的ACK包并不重要。这种想法导致了TCP_DEFER_ACCEPT开发的一个特性——这致使第三个ACK包被静默地丢弃。设置此标志后,套接字将保持在SYN-RECV状态,直到接收到包含实际数据的第一个包:
$ sudo ./test-syn-ack.py
00:00.000 IP host.2 > host.1: Flags [S]
00:00.000 IP host.1 > host.2: Flags [S.]
00:00.000 IP host.2 > host.1: Flags [.] # delivered, but the socket stays as SYN-RECV
State Recv-Q Send-Q Local:Port Peer:Port
SYN-RECV 0 0 host:1 host:2 timer:(on,7.192ms,0)
ESTAB 0 0 host:2 host:1
00:08.020 IP host.2 > host.1: Flags [P.], length 11 # payload moves the socket to ESTAB
State Recv-Q Send-Q Local:Port Peer:Port
ESTAB 11 0 host:1 host:2
ESTAB 0 0 host:2 host:1即使在收到最后的TCP握手ACK后,服务器套接字仍然处于SYN-RECV状态。它有一个有趣的“on”计时器,其中的重试计数卡在0次。在客户端发送数据包或TCP_DEFER_ACCEPT计时器过期后,它被转换为ESTAB——并从SYN移动到accept队列。基本上,使用DEFER ACCEPT时,SYN-RECV微型套接字会丢弃无数据的入站ACK。
空闲ESTAB永久存在
让我们继续讨论连接到不健康(死亡)对等点的完全建立的套接字。握手完成后,两边的套接字移动到建立状态,像这样:
State Recv-Q Send-Q Local:Port Peer:Port
ESTAB 0 0 host:2 host:1
ESTAB 0 0 host:1 host:2这些套接字在缺省情况下没有运行计时器——即使通信中断,它们也将永远保持这种状态。只有当一方试图发送某些内容时,TCP堆栈才会注意到问题所在。这就提出了一个问题——如果您不打算通过连接发送任何数据该怎么办?如何确保空闲连接正常,而不通过它发送任何数据?
这就是TCP keepalives的作用所在。让我们看一下它的作用——在此示例中,我们使用了以下切换:
- SO_KEEPALIVE = 1——启用keepalives。
- TCP_KEEPIDLE = 5——闲置5秒后发送第一个keepalive探测。
- TCP_KEEPINTVL = 3——3秒后发送后续的keepalive探测。
- TCP_KEEPCNT = 3——三个失败的探测后超时。
$ sudo ./test-idle.py
00:00.000 IP host.2 > host.1: Flags [S]
00:00.000 IP host.1 > host.2: Flags [S.]
00:00.000 IP host.2 > host.1: Flags [.]
State Recv-Q Send-Q Local:Port Peer:Port
ESTAB 0 0 host:1 host:2
ESTAB 0 0 host:2 host:1 timer:(keepalive,2.992ms,0)
# all subsequent packets dropped
00:05.083 IP host.2 > host.1: Flags [.], ack 1 # first keepalive probe
00:08.155 IP host.2 > host.1: Flags [.], ack 1 # second keepalive probe
00:11.231 IP host.2 > host.1: Flags [.], ack 1 # third keepalive probe
00:14.299 IP host.2 > host.1: Flags [R.], seq 1, ack 1确实!我们可以清楚地看到在5s标记处发送的第一个探测,还有两个剩余的探测相距3秒——这完全符合我们的指定。在总共发送了3个探测,并且再延迟3秒之后,连接就会显示ETIMEDOUT而终止,最后发送了RST。
要使keepalives正常工作,发送缓冲区必须为空。您可以在“timer:(keepalive)”行中注意到keepalive计时器处于活动状态。
使用TCP_USER_TIMEOUT的Keepalives令人困惑
我们之前提到过TCP_USER_TIMEOUT选项。它设置了在内核强行关闭连接之前,传输的数据可能保持未确认状态的最长时间。就其本身而言,在空闲连接的情况下,它并没有什么作用。即使断开连接,套接字也将保持建立状态。但是,这个套接字选项确实改变了TCP keepalives的语义。tcp(7)帮助页有些令人困惑:
此外,当与TCP keepalive (SO_KEEPALIVE)选项一起使用时,TCP_USER_TIMEOUT将覆盖keepalive,从而确定何时由于keepalive失败而关闭连接。
原始的提交消息有更多的细节:
要理解语义,我们需要查看linux / net / ipv4 / tcp_timer.c:693中的内核代码:
if ((icsk->icsk_user_timeout != 0 &&
elapsed >= msecs_to_jiffies(icsk->icsk_user_timeout) &&
icsk->icsk_probes_out > 0) ||为了使用户超时生效,icsk_probes_out必须不为零。只有在第一个探测发出之后,才会检查用户超时。让我们来看一看。我们的连接设置如下:
- TCP_USER_TIMEOUT = 5*1000——5秒
- SO_KEEPALIVE = 1——启用keepalives
- TCP_KEEPIDLE = 1——快速发送第一个探测——1秒空闲
- TCP_KEEPINTVL = 11——每11秒进行一次后续探测
- TCP_KEEPCNT = 3——在超时之前发送三个探测
00:00.000 IP host.2 > host.1: Flags [S]
00:00.000 IP host.1 > host.2: Flags [S.]
00:00.000 IP host.2 > host.1: Flags [.]
# all subsequent packets dropped
00:01.001 IP host.2 > host.1: Flags [.], ack 1 # first probe
00:12.233 IP host.2 > host.1: Flags [R.] # timer for second probe fired, socket aborted due to TCP_USER_TIMEOUT所以发生了什么事?该连接在1s标记处发送了第一个keepalive探测。看到没有响应,TCP堆栈11秒后唤醒,发送第二个探测。但这一次,它执行了USER_TIMEOUT代码路径,该路径决定立即终止连接。
如果将TCP_USER_TIMEOUT设置为更大的值,比如在第二个和第三个探测之间,会发生什么情况?然后,连接将在第三个探测计时器上关闭。TCP_USER_TIMEOUT设置为12.5s的情况如下:
00:01.022 IP host.2 > host.1: Flags [.] # first probe
00:12.094 IP host.2 > host.1: Flags [.] # second probe
00:23.102 IP host.2 > host.1: Flags [R.] # timer for third probe fired, socket aborted due to TCP_USER_TIMEOUT我们已经展示了TCP_USER_TIMEOUT如何与中小值的keepalive交互。最后一种情况是TCP_USER_TIMEOUT非常大。假设我们将其设置为30秒:
00:01.027 IP host.2 > host.1: Flags [.], ack 1 # first probe
00:12.195 IP host.2 > host.1: Flags [.], ack 1 # second probe
00:23.207 IP host.2 > host.1: Flags [.], ack 1 # third probe
00:34.211 IP host.2 > host.1: Flags [.], ack 1 # fourth probe! But TCP_KEEPCNT was only 3!
00:45.219 IP host.2 > host.1: Flags [.], ack 1 # fifth probe!
00:56.227 IP host.2 > host.1: Flags [.], ack 1 # sixth probe!
01:07.235 IP host.2 > host.1: Flags [R.], seq 1 # TCP_USER_TIMEOUT aborts conn on 7th probe timer我们在wire上看到了六个keepalive探测!设置TCP_USER_TIMEOUT后, TCP_KEEPCNT将被完全忽略。如果您想使TCP_KEEPCNT有意义,那么唯一明智的USER_TIMEOUT值应小于:
TCP_KEEPIDLE + TCP_KEEPINTVL * TCP_KEEPCNT忙碌ESTAB套接字不会永久存在
到目前为止,我们已经讨论了连接空闲的情况。当连接在发送缓冲区中有未确认的数据时,将应用不同的规则。
让我们准备另一个实验——在三次握手之后,让我们建立一个防火墙来删除所有的包。然后,在一端进行发送操作从而获得被丢弃的数据包。实验显示发送套接字在约16分钟后消失:
00:00.000 IP host.2 > host.1: Flags [S]
00:00.000 IP host.1 > host.2: Flags [S.]
00:00.000 IP host.2 > host.1: Flags [.]
# All subsequent packets dropped
00:00.206 IP host.2 > host.1: Flags [P.], length 11 # first data packet
00:00.412 IP host.2 > host.1: Flags [P.], length 11 # early retransmit, doesn't count
00:00.620 IP host.2 > host.1: Flags [P.], length 11 # 1st retry
00:01.048 IP host.2 > host.1: Flags [P.], length 11 # 2nd retry
00:01.880 IP host.2 > host.1: Flags [P.], length 11 # 3rd retry
State Recv-Q Send-Q Local:Port Peer:Port
ESTAB 0 0 host:1 host:2
ESTAB 0 11 host:2 host:1 timer:(on,1.304ms,3)
00:03.543 IP host.2 > host.1: Flags [P.], length 11 # 4th
00:07.000 IP host.2 > host.1: Flags [P.], length 11 # 5th
00:13.656 IP host.2 > host.1: Flags [P.], length 11 # 6th
00:26.968 IP host.2 > host.1: Flags [P.], length 11 # 7th
00:54.616 IP host.2 > host.1: Flags [P.], length 11 # 8th
01:47.868 IP host.2 > host.1: Flags [P.], length 11 # 9th
03:34.360 IP host.2 > host.1: Flags [P.], length 11 # 10th
05:35.192 IP host.2 > host.1: Flags [P.], length 11 # 11th
07:36.024 IP host.2 > host.1: Flags [P.], length 11 # 12th
09:36.855 IP host.2 > host.1: Flags [P.], length 11 # 13th
11:37.692 IP host.2 > host.1: Flags [P.], length 11 # 14th
13:38.524 IP host.2 > host.1: Flags [P.], length 11 # 15th
15:39.500 connection ETIMEDOUT数据包被重传15此,具体控制如下:
$ sysctl net.ipv4.tcp_retries2
net.ipv4.tcp_retries2 = 15根据ip-sysctl.txt文档中的描述:
默认值15表示假设时限时间为924.6秒,这也是有效时限的下限。TCP将在第一个超过假设时限的RTO(重传时限)处有效地超时。
连接确实在约940秒时终止。注意,套接字中 “on”计时器正在运行。设置SO_KEEPALIVE完全不会造成影响——当“on”计时器正在运行时,keepalives不会被占用。
TCP_USER_TIMEOUT仍可以正常工作。自上次接受到的数据包起,连接将在用户超时指定时间之后被终止。设置用户超时时间后,tcp_retries2值将被忽略。
零窗口ESTAB是......永远存在的吗?
还有最后一个值得一提的例子。如果发送方有大量数据,而接收方速度较慢,那么TCP流控制就开始起作用了。在某些时候,接收方会要求发送方停止传输新数据。这与上面描述的情况略有不同。
在这种情况下,如果启用了流控制,不会有任何进行中或未确认的数据。相反,接收方用“零窗口”通知来限制发送方。然后,发送方定期检查“窗口探测”条件是否仍然有效。在这个实验中,为了简单起见,我们减小了接收缓冲区的大小。这是它在wire上的样子:
00:00.000 IP host.2 > host.1: Flags [S]
00:00.000 IP host.1 > host.2: Flags [S.], win 1152
00:00.000 IP host.2 > host.1: Flags [.]
00:00.202 IP host.2 > host.1: Flags [.], length 576 # first data packet
00:00.202 IP host.1 > host.2: Flags [.], ack 577, win 576
00:00.202 IP host.2 > host.1: Flags [P.], length 576 # second data packet
00:00.244 IP host.1 > host.2: Flags [.], ack 1153, win 0 # throttle it! zero-window
00:00.456 IP host.2 > host.1: Flags [.], ack 1 # zero-window probe
00:00.456 IP host.1 > host.2: Flags [.], ack 1153, win 0 # nope, still zero-window
State Recv-Q Send-Q Local:Port Peer:Port
ESTAB 1152 0 host:1 host:2
ESTAB 0 129920 host:2 host:1 timer:(persist,048ms,0)数据包捕获显示了几件事。首先,我们可以看到两个包含数据的数据包,每个数据包长576个字节。他们都立即得到了承认。第二个ACK有“win 0”通知:通知发送方停止发送数据。
但是发送者渴望发送更多!最后两个包显示第一个“窗口探测”:发送方将定期发送无有效负载的“ack”包来检查窗口大小是否改变。只要接收者继续应答,发送者就会一直发送这样的探测。
套接字信息显示了三个重要的事情:
- 读取器的读取缓冲区已满——因此需要“零窗口”调节。
- 发送者的写缓冲区已满——我们还有更多数据要发送。
- 发送方运行一个“persist”(持续)计时器,计算到下次“窗口探测”的时间。
在这篇文章中,我们感兴趣的是超时——如果窗口探测丢失了会发生什么?发送者会注意到吗?
默认情况下,窗口探针将重试15次——遵循通常的tcp_retries2设置。
tcp计时器处于persist状态,因此TCP keepalive将不会运行。进行窗口探测时,SO_KEEPALIVE设置不改变任何事情。
正如预期的那样,TCP_USER_TIMEOUT切换将继续工作。与keepalives上的用户超时类似,只有在重新传输计时器触发时,它才会被占用。在这样的事件中,如果自上次传递正确的数据包以来的时间超过了用户超时秒数,则连接将被中止。
关于使用应用程序超时设定的注意事项
过去,我们分享了一个有趣的“战斗”故事:
在应用程序管理的超时触发后,我们的HTTP服务器将放弃连接。这是一个bug——慢速连接可能正确地缓慢耗尽了发送缓冲区,但是应用程序服务器没有注意到这一点。
我们突然放弃了缓慢的下载,即使这不是我们的意图。我们只想确保客户端连接仍然健康。使用TCP_USER_TIMEOUT比依靠应用程序管理的超时更好。
但这还不够。我们还希望防止出现这样的情况:客户端流有效,但被阻塞,且不耗尽连接。实现此目的的唯一方法是定期检查发送缓冲区中未发送的数据量,并查看其是否以所需的速度缩减。
对于典型的向互联网发送数据的应用程序,我建议:
- 启用TCP keepalives。这是空闲连接情况下保持数据流动的需要。
- 将TCP_USER_TIMEOUT设置为TCP_KEEPIDLE + TCP_KEEPINTVL * TCP_KEEPCNT.
- 使用应用程序管理的超时时要小心。如需检测TCP故障,请使用TCP keepalives和用户超时。如果您想要节省资源,并确保套接字不会存活太长时间,请考虑定期检查套接字是否以所需的速度耗尽。你可以使用ioctl(TIOCOUTQ)来检查,但它会同时计算套接字上缓冲的(未发送的)数据和正在运行的(未确认的)字节。最好的方法是使用TCP_INFO tcpi_notsent_bytes参数,该参数只报告前一个计数器。
一个检查耗尽速度的示例:
while True:
notsent1 = get_tcp_info(c).tcpi_notsent_bytes
notsent1_ts = time.time()
...
poll.poll(POLL_PERIOD)
...
notsent2 = get_tcp_info(c).tcpi_notsent_bytes
notsent2_ts = time.time()
pace_in_bytes_per_second = (notsent1 - notsent2) / (notsent2_ts - notsent1_ts)
if pace_in_bytes_per_second > 12000:
# pace is above effective rate of 96Kbps, ok!
else:
# socket is too slow...有很多方法可以进一步改进这个逻辑。我们可以使用TCP_NOTSENT_LOWAT,尽管它通常只在发送缓冲区相对为空的情况下有用。然后,我们可以使用SO_TIMESTAMPING接口来通知何时交付数据。最后,如果我们完成了向套接字发送数据的工作,那么只需调用close()并将套接字的处理推延到操作系统即可。这样的套接字将被卡在FIN-WAIT-1或LAST-ACK状态,直至正确释放。
总结
在本文中,我们讨论了TCP连接可能会注意到另一方离线的五种情况:
- SYN-SENT:这个状态的持续时间可以通过TCP_SYNCNT或tcp_syn_retry来控制。
- SYN-RECV:通常对应用程序隐藏。它由tcp_synack_retries调整。
- 闲置已建立连接,TCP将永远不会发现任何问题。一种解决方案是使用TCP keepalive。
- 连接繁忙,保持tcp_retries2设置,忽略TCP keepalives。
- 零窗口已建立连接,保持tcp_retries2设置,忽略TCP keepalives。
特别是后两个已建立的用例可以使用TCP_USER_TIMEOUT进行自定义,但是这个设置也会影响其他情况。一般来说,它可以被看作是向内核发出的一个提示,即在上一个好数据包发送后过多少秒终止连接。但是,这是一个危险的设置,如果与TCP keepalives一起使用,则应该将其设置为略低于TCP_KEEPIDLE + TCP_KEEPINTVL * TCP_KEEPCNT的值。否则,它将影响并可能取消TCP_KEEPCNT值。
在这篇文章中,我们提供了一些脚本展示了在各种网络条件下超时相关套接字选项的效果。将tcpdump包捕获与ss -o输出交叉并联是理解网络堆栈的一种好方法。我们能够创建可重复的测试用例,显示“on”、“keepalive”和“persist”计时器的作用。对于进一步的实验来说,这是一个非常有用的框架。
最后,要调优TCP连接以确信远程主机实际上已经启动,这是非常困难的。在调试过程中,我们发现查看发送缓冲区大小和当前活动的TCP计时器对于了解套接字是否健康非常有帮助。我们Spectrum应用中的bug被证明是由一个错误的TCP_USER_TIMEOUT设置造成的——如果没有这个设置,带有大型发送缓冲区的套接字的停留时间会比我们预期的长得多。
您可以在我们的Github上找到本文中使用的脚本。