————————————————————时光点燃了少年的梦想.......
1.
abcdef 的前缀: a, ab, abc, abcd, abcde (abcdef 可不是前缀哦!)
abcdef 的后缀: f, ef, def, cdef, bcdef, (abcdef可不是后缀哦!)
abcdef 的前缀后缀最长公共元素长度为 0 (因为其前缀与后缀没有相同的!)
ababa的前缀: a, ab, aba, abab,
ababa的后缀: a, ba, aba, baba,
ababa的相同前缀后缀的最大长度为: 3
ascesubluffy 的 prefix:
a, as, asc, asce, asces, ascesu, ascesub, ascesubl, ascesublu, ascesubluf, ascesubluff,
asecesubluffy 的postfix:
y, fy, ffy, uffy, luffy, bluffy, ubluffy, subluffy, esubluffy, cesubluffy, scesubluffy,
长度为 len 的字符串的前缀与后缀的个数为 2*(len - 1);
ascesubluffy 的相同前缀后缀的最大长度(公共长度)为 0.
abab
prefix : a, ab, aba,
postfix: b, ab, bab,
"abab" 's 相同前缀后缀的最大长度(公共最大长)为:2 ;
"abab" 的最长相同公共前缀后缀 为: ab .
如果给定的模式串为"abab",那么它的各个子串的 前缀后缀的公共元素的最大长度 为:
a : 0
ab : 0
aba : 1 (prefix:a,ab; postfix:a,ba;)
abab : 2 (prefix:a,ab,aba; postfix: b,ab,bab;)

1.5
寻找最长前缀后缀:
如果给定的模式串 P 是:"ABCDABD";从左至右遍历整个模式串,其各个子串的前缀后缀分别如下表格所示:
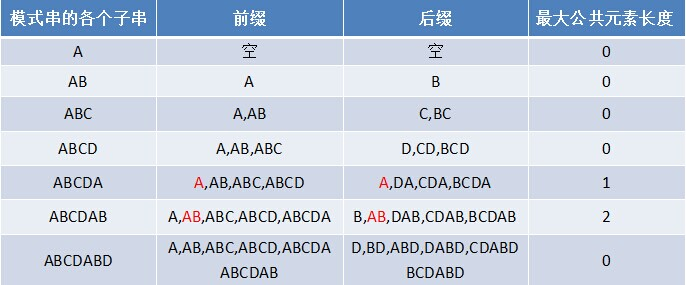
也就是说,原模式串子串对应的各个前缀后缀的公共元素的最大长度表为(下简称《最大长度表》):

2.
next 数组考虑的是 除当前字符外的从首字符到当前字符前一位置的相同前缀后缀的最大长度。
所以通过 1.的这步操作求得各个子串的前缀后缀的公共元素的最大长度后,只要稍作变形即可: 将第1.步骤中求得的值整体右移(就是减小的意思)一位
(这是要去减1的意思啦嘞!),
然后初值赋为-1。

next[0] == -1; next[1] == 0; next[2] == 0; next[3] == 1.
3.
模式串P=="ABCDABD".
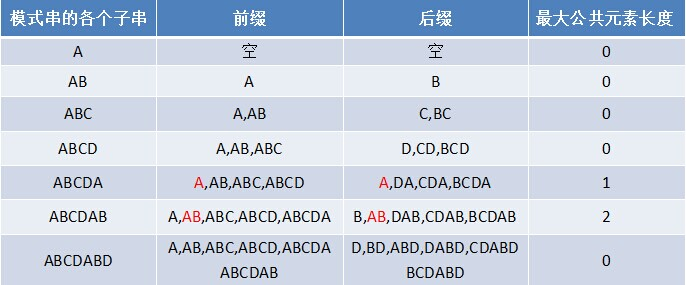

如果给定文本串S=“BBC ABCDAB ABCDABCDABDE”,和模式串P=“ABCDABD”,现在要拿模式串去跟文本串匹配。

(1). 因为模式串中的字符A跟文本串中的字符B、B、C、空格一开始就不匹配,所以不必考虑结论,
直接将模式串不断的右移一位即可,直到模式串中的字符A跟文本串的第5个字符A匹配成功;

(2). 继续往后匹配(continue to match!),当模式串(P="ABCDABD")最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。
但向右移动多少位呢?
因为
(2).1:此时已经匹配的字符数为6个(ABCDAB),
(2).2:然后根据《最大长度表》可得失配字符D的上一位字符B对应的( 还并不是next数组哦!是到B这儿的相同前缀后缀的最大长度!)长度值为2,
(2).3:需要向右移动6 - 2 = 4 位。

(3). 模式串向右移动4位后,发现C处再度失配,
(3).1:此时已经匹配了2个字符(AB),
(3).2:上一位字符B对应的最大长度值为0,
(3).3:向右移动:2-0=2位.
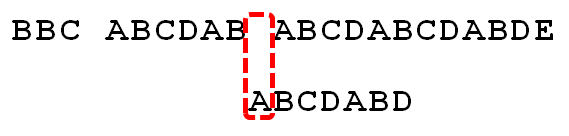
(4) A与空格失配,向右移动1 位。

(5)继续比较,发现D与C 失配,
(5).1:已匹配的字符数6
(5).2:上一位字符B对应的最大长度2,
(5).3:故向右移动的位数为:已匹配的字符数6减去上一位字符B对应的最大长度2,即向右移动6 - 2 = 4 位。

(6): 经历第5步后,发现匹配成功,过程结束。
通过上述匹配过程可以看出,问题的关键就是寻找模式串中最大长度的相同前缀和后缀。
找到了模式串中每个字符之前的前缀和后缀公共部分的最大长度后,便可基于此匹配。
模式串P的next 数组要表达的含义就是模式串中每个字符之前的前缀和后缀公共部分的最大长度。
我们已经知道,字符串“ABCDABD”各个子串的前缀后缀的最大公共元素长度分别为:

根据这个表可以得出下述结论:
失配时,模式串P向右移动(+=)的位数为 == 已匹配字符数- 失配字符的上一位字符所对应的最大长度值
我们发现,当匹配到一个字符失配时,其实没必要考虑当前失配的字符,更何况我们每次失配时,都是看的失配字符的上一位字符对应的最大长度值。
如此,便引出了next 数组。
给定字符串 “ABCDABD” ,可求得它的next 数组如下:

把next 数组跟之前求得的最大长度表对比后,不难发现,next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1。
对于给定的模式串:ABCDABD,它的最大长度表及next 数组分别如下:

给出这样一个公式:
失配时,模式串向右移动的位数 == 失配字符所在位置 - 失配字符对应的next值。
而后,你会发现,无论是基于《最大长度表》的匹配,还是基于next 数组的匹配,两者得出来的向右移动的位数是一样的。为什么呢?
因为:
(1)根据《最大长度表》,失配时,模式串向右移动的位数 = 已经匹配的字符数 - 失配字符的上一位字符的最大长度值
(2)根据《next 数组》,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值
(3)其中,从0开始计数时,失配字符的位置 = 已经匹配的字符数(失配字符不计数),而失配字符对应的next 值 = 失配字符的上一位字符的最大长度值,两相比较,结果必然完全一致。
所以,你可以把《最大长度表》看做是next 数组的雏形,甚至就把它当做next 数组也是可以的,区别不过是怎么用的问题。