Motivation
数据稀疏问题、缺乏衡量单词对语义关系的指标。
distributed word representations处理数据稀疏问题有优势,深度学习模型在文本语义匹配上取得进展。
-
使用 word embeddings 作为输入
-
Gate relevance network捕捉单词对之间的语义交互。
-
使用 Pooling layer选择 信息量最大的交互
模型架构
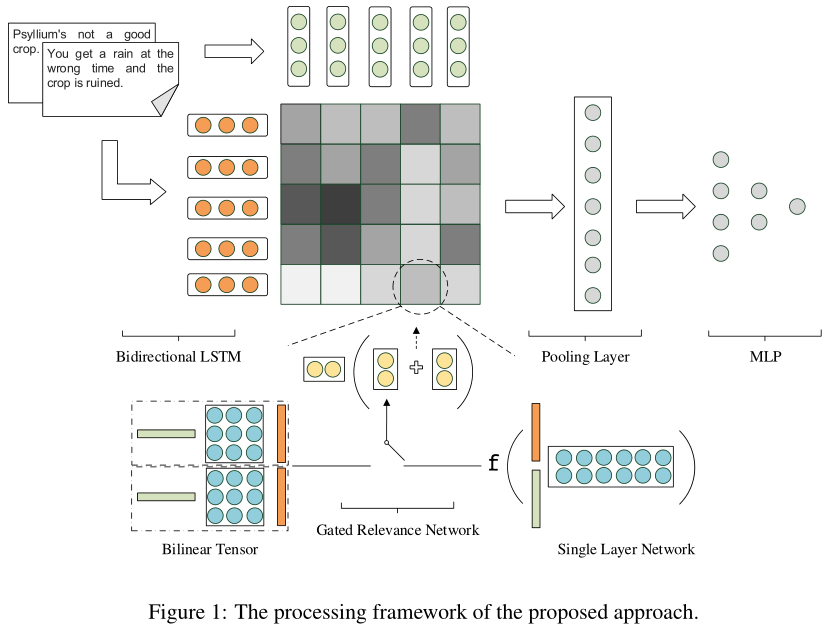
主要内容:
-
输入为word embedding,通过RNN(BiLSTM)将文本段,编码为其 位置表示
-
使用Gated relevance Network捕捉 位置表示 之间的语义交互
-
最后,生成的所有交互被传入max pooling layer得到最强的交互。然后通过多层感知机(MLP)聚合它们来预测篇章关系。
模型细节:
Embedding Layer:
-
输入:单词的one-hot representation
-
输出:OOV word embedding
-
映射单词为word embedding,padding所有text segments使之拥有相同的长度。
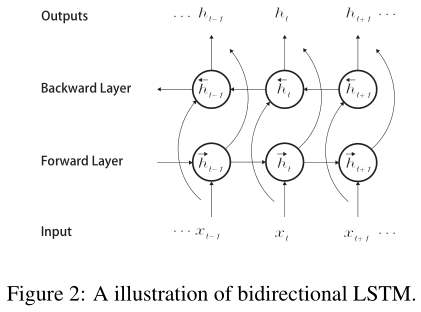
Sentence Modeling with LSTM:
-
输入:variable-length S=(x0,..xT)(wt)
-
输出:ht=[->,<-],即单词在位置t和他的上下文信息
-
操作:使用双向LSTM,将单词 w_t 转换成 h_t。
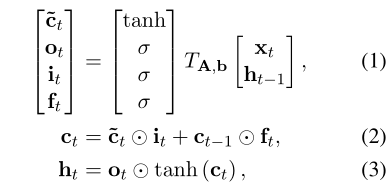
Gated Relevance Network:
-
输入:由上面计算出的位置表示.
-
输出(两个text segment):Interaction score matrix。
-
操作:
-
给定两个text segments (X = x_1, ..., x_n) 和 (Y = y_1, ..., y_m),通过Bi-LSTM编码,得到他们的位置表示 (X_h = x_{h_1}, ..., x_{h_n}) 和 (Y_h = y_{h_1}, ..., y_{h_m}).
-
计算 维度为 (d_h)的每个中间表示对 (x_{h_i}) 和 (y_{h_j})之间的 relevance socre(相关性得分)。用GRN合并计算Relevance score的两个模型。
-


Max-Pooling Layer and MLP:
-
输入: Interaction score matrix
-
操作: max-pooling strategy来划分评分矩阵成一组不重叠的子区域,每个子区域输出最大值。Pooling scores组成的向量;并输出到MLP(多层感知机)
-
输出: 分类任务输出,不同类的概率
Model Trainning:

实验
实验设置
- PDTB的不平衡样本分布
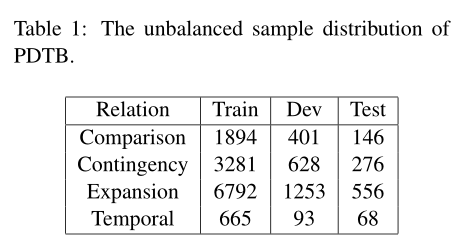
-
四个二分类识别top level relations(EntRel融入Expansion中)
-
Training data:正例样本数等于负例样本数。
Baseline
-
LSTM + MSP
-
BiLSTM + MSP
-
Word + NTN
-
LSTM + NTN
-
BiLSTM + NTN
-
Word + GRN
-
LSTM + GRN
超参数设置

实验结果
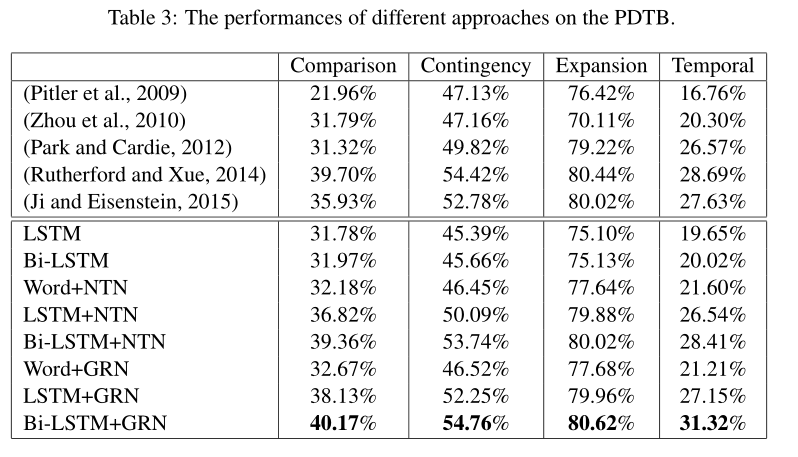
Parameter Sensitivity
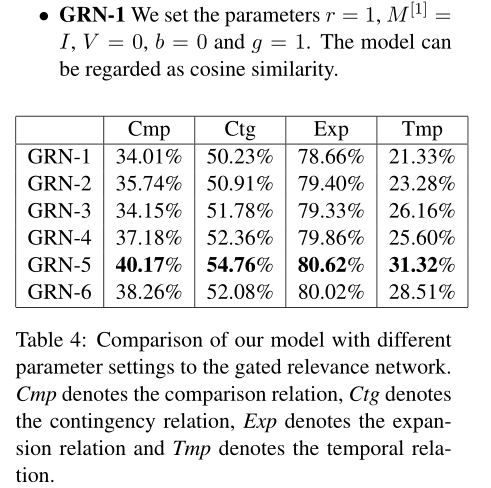

一方面,我们可以看到双线性张量的每个切片负责一种类型的关系,具有2个切片的双线性张量比原始双线性模型更适合于训练二进制分类器。另一方面,增加切片数量会增加模型的复杂度,从而使训练更加困难。
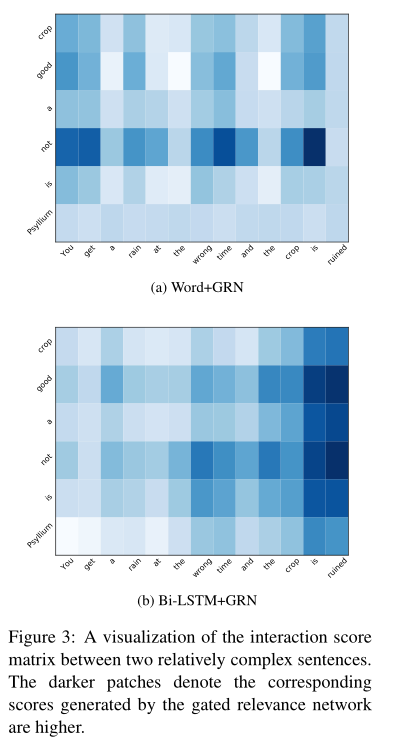
Case Study