runxinzhi.com
首页
百度搜索
python爬虫笔记(四)网络爬虫之提取—Beautiful Soup库(2)基于bs4库的HTML内容遍历方法
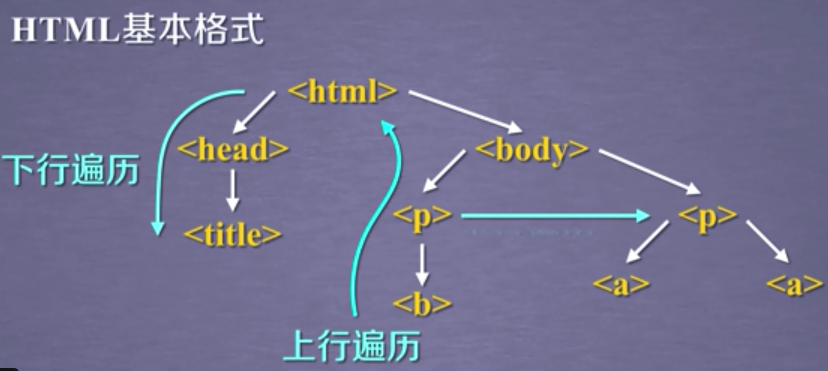
1. 基于bs4库的HTML内容遍历方法
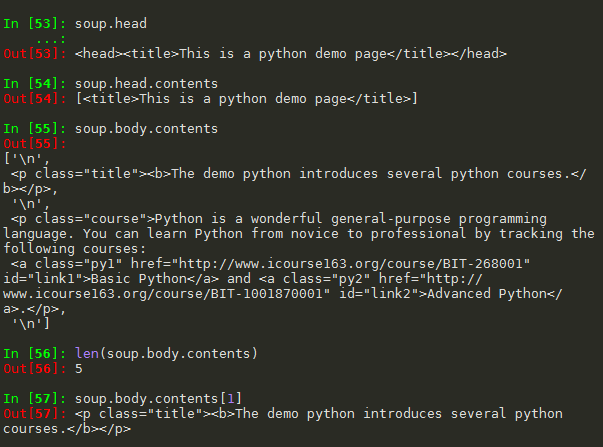
1.1 .contents 举例
1.2 结点的父亲标签
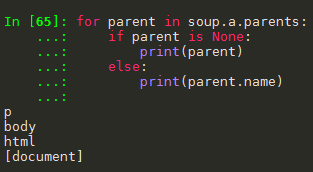
1.3 标签树的上行遍历(parents)
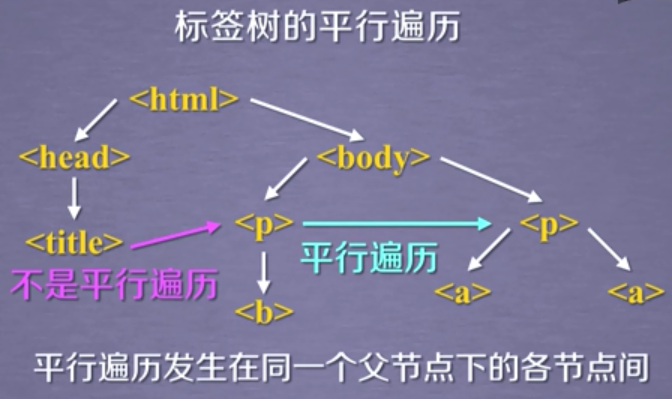
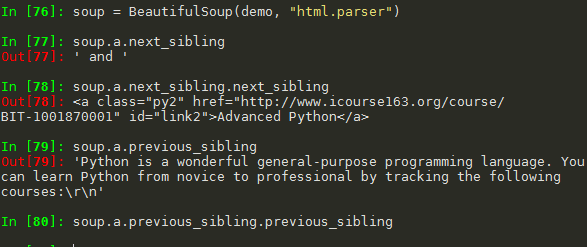
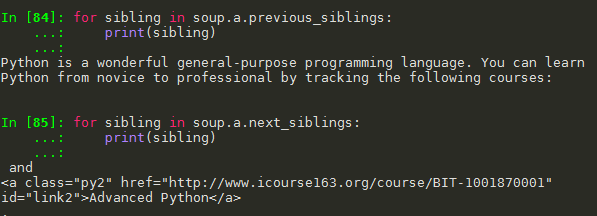
1.4 标签树的平行遍历
注意:标签的儿子结点可能是 NavigableString
相关阅读:
JavaScript之延迟加载
Android之adb命令
Android之所有API汇总
Android常用系统广播
CSS之自适应布局webkit-box
在Go中没有引用传值
go指针-1
go如何实现优雅的错误处理,
Golang中切片复制成本,一个大切片会比小切片占用更多内存吗?
Go中的Slice有何不同,传递类型,详解切片类型
原文地址:https://www.cnblogs.com/douzujun/p/12229160.html
最新文章
sql笔记
springboot中redis引入报红
JVM梳理
报错"Parameter 0 of method stringRedisTemplate in org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration required a bean of type 'org.springframework.data.redis.connection.RedisConnec"
mysql远程连接虚拟机数据库报错2003(docker虚拟机防火墙没关)
StringUtils中isEmpty的用法
导包坑
element-UI之表单校验—关闭弹窗后,重新打开弹窗,清除提示消息
element-UI之表单校验—上传图片后,清楚提示
Appium 已支持中文输入
热门文章
Node.js的安装
MySQL之学生名次问题
不同服务器数据库之间的数据操作
jQuery之DOM操作
纪念我大学最后的时光
JavaScript之聊天室设计摸拟
JavaScript之canvas
SVG之初识
CSS之拖拽1
Android之聊天室设计与开发
Copyright © 2020-2023
润新知