字符串
字符串支持像列表似得用下标进行取值操作,和进行切片
字符串格式化:

#内容相当于字符串,也可以用双引号包裹 str=''' 111 2222 33333 ---------东小东------- ''' print(str)
字符串拼接:
方法1:
每次拼接时会重新开辟内存空间,效率较低
print("我"+"是"+"东小东") #输出:我是东小东
方法2:
%s为字符串,%d为整数,%f为浮点数等等
print("我是%s%s"%("东小东","-加油")) #输出:我是东小东-加油
方法3:
如果使用format_map,传递的值为字典
print("我是{namex}{textx}".format(namex="东小东",textx="-加油")) #输出:我是东小东-加油
方法4:
print("我是{0}{1}".format("东小东","-加油")) #输出:我是东小东-加油
相关函数:
1 #字符串 2 strx="abadefg1" 3 4 print(strx.capitalize()) #首字母大写 5 print("Dong xiAo".swapcase()) #大小写对应转换,输出:dONG XIaO 6 print(len(strx)) #字符串长度为8 7 print(strx.count("a")) #统计字符串a的个数 8 9 print(strx.center(50,"*")) #一共打印50个字符,将strx放在中间,其他使用*号补全 10 print(strx.ljust(50,"*")) #一共打印50个字符,将strx放在左边,其他使用*号补全,对应有 rjust() 11 12 print(strx.endswith("fg")) #字符串是否与"fg"结尾,返回bool 13 14 print(strx.find("=2=")) #查找字符串所在位置,失败返回-1,成功返回索引值 15 16 print("rfid id id".rfind("i")) #从左到右,查找到最右边一个的下标,输出:8 17 18 19 print(strx.isalnum()) #是否是只有数字和字母组成,返回bool 20 21 print(strx.isalpha()) #是否只有字母,返回bool 22 23 print("10".isdigit()) #是否是整数,返回bool ,输出:True 24 25 print("+jj".isidentifier()) #是否是合法变量名,返回bool ,输出:False 26 27 print("ABcd东".lower())#将大写字母转换为小写,对应有upper() 28 29 print("abbc".islower()) #是否全为小写,大写为:isupper() 30 31 print("dong xiao dong1".title()) #各单词首字母大写,输出:Dong Xiao Dong1 32 33 print("Dong Xiao Dong".istitle()) #判断每个单词首字母是否均为大写,输出:True 34 35 print("==".join(["111","222","333"])) #集合转换为字符串,并且使用特点字符分隔,输出:111==222==333 36 37 print(" jj ".strip()) #去掉两边空格或回车等,对应还有:lstrip(),rstrip() 38 39 p=str.maketrans("dongxiao","123GX678") #一一对应关系 40 print("dongxiaodong".translate(p)) #内容替换,输出:183GX678183G 41 42 print("ABCAB".replace("A","aa")) #替换,输出:aaBCaaB 43 44 print("dong+xiao+dong".split("+")) #将字符串以"+"分割并保存到列表中,默认分隔符为空格
字符串的排序:
#排序 #转换成列表输出 listx="bbe59210" print(sorted(listx)) #输出:['0', '1', '2', '5', '9', 'b', 'b', 'e']
判断某个字符串是否是另一个字符串的子字符串,可以使用find(),也可使用:
if "dong" in "dongxiaodong": print("存在") #输出 if "dong" not in "xiaoxiao": print("不存在") #输出
字符串查找(index)
如果查找的字符串存在则返回位置,不存在则报错
try: print("东小东dong".index("donge")) except ValueError as e: print("****异常***",e)
编码和Byte(二进制)
中文编码演变:ASCLL->GB3212->GBK(已支持基本的中文,常用)->GB18030(收录各民族文字),各编码均向下兼容
世界标准:ASCLL(一个字符占一个字节)->Unicode(万国码,一个字符占两个字节)->utf-8(英文一个字符占一个字节,汉字一个字符占三个字节)
其中Python3的默认编码为utf-8
视频及图片的保存是使用二进制格式,Python3的网络编程,传输的信息是需要编码为二进制的
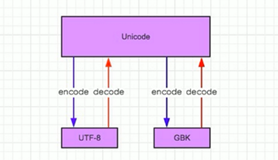
编码和解码:
1 #编码,字符串编码为二进制格式 2 #参数表示是以什么编码集进行编码 3 bstr="字符串".encode("gbk") #utf-8 4 5 #解码,二进制转换为字符串格式 6 #参数表示是以什么编码集进行解码 7 str=bstr.decode("gbk") 8 9 print(str) #输出:字符串