Scrapy单机架构
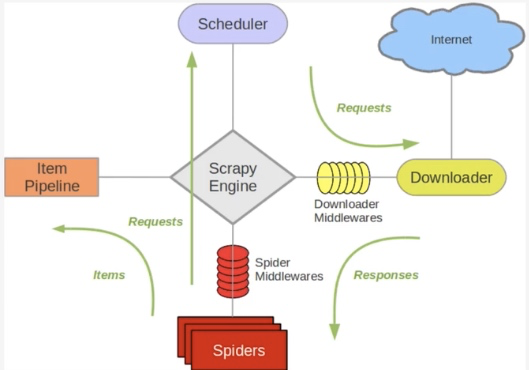
上图的架构师一种单机架构, 只在本机维护一个爬取队列, Scheduler进行调度, 而要实现多态服务器共同爬去数据关键就是共享爬取队列.
Scrapy不可以自己实现分布式 :
1. 多台机器上部署的scrapy灰鸽子拥有各自的调度器, 这样就使得多态机器无法分配start_urls列表中的url(多台机器无法共享同一个调度器)
2. 多台机器爬取到的数据无法通过同一个管道对数据进行同一的数据持久化存储(多态机器无法共享同一个管道)
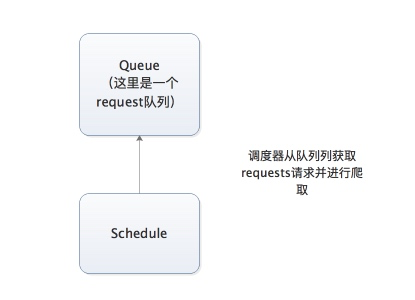
分布式架构
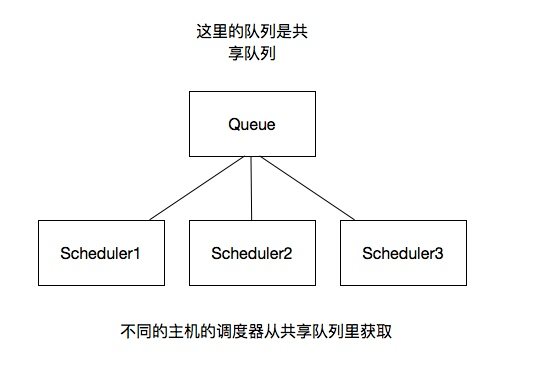
分布式架构重要的是队列通过什么维护 :
一般来说队列是通过Redis维护
redis是内存中的数据存储系统,处理速度快, 提供队列集合等多种存储结构, 方便队列维护
如何去重 :
借助redis的集合, redis提供的集合数据结构, 在redis集合中存储每个人request的指纹
在想request队列中加入Request前先验证这个Request的指纹是否已经加入集合中. 如果已经存在则不添加到request队列中, 如果不存在, 则将request加入到队列并将指纹加入集合.
如何防止中断?如何slave因为特殊原因宕机, 怎么解决 :
在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空, 如果不为空, 则从队列中获取下一个erequest执行爬取. 如果为空则重新开始爬取
如何实现分布式架构 :
scrapy-redis改写了Scrapy的调度器, 队列等组件, 利用他可以方便的实现Scrapy分布式架构.
搭建分布式爬虫
前提: 安装scrapy_redis模块(pip install scrapy_redis)
修改settings中的配置信息 :
替换scrapy调度器: SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class: DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
共享的爬取队列, 需要redis的连接信息 :
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
设置为True则不会清空redis里的dupefilter和request队列 :
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_PERSIST = True
设置重启爬虫时是否清空爬取队列 :
这样每次重启爬虫都会清空指纹和请求队列, 一般设置为False
SCHEDULER_FLUSH_ON_START=True
# 使用scrapy-redis组件的去重队列 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 是否允许暂停 SCHEDULER_PERSIST = True REDIS_HOST = 'redis服务的ip地址' REDIS_PORT = 6379 REDIS_ENCODING = ‘utf-8’ REDIS_PARAMS = {‘password’:’123456’}
开启redis服务器:redis-server 配置文件
开启redis客户端:redis-cli
运行爬虫文件:scrapy runspider SpiderFile
向调度器队列中扔入一个起始url(在redis客户端中操作):lpush redis_key属性值 起始url