不知大家有没有思考过,当我们使用IDE写了一个Demo类,并执行main函数打印 hello world时都经历了哪些流程么?
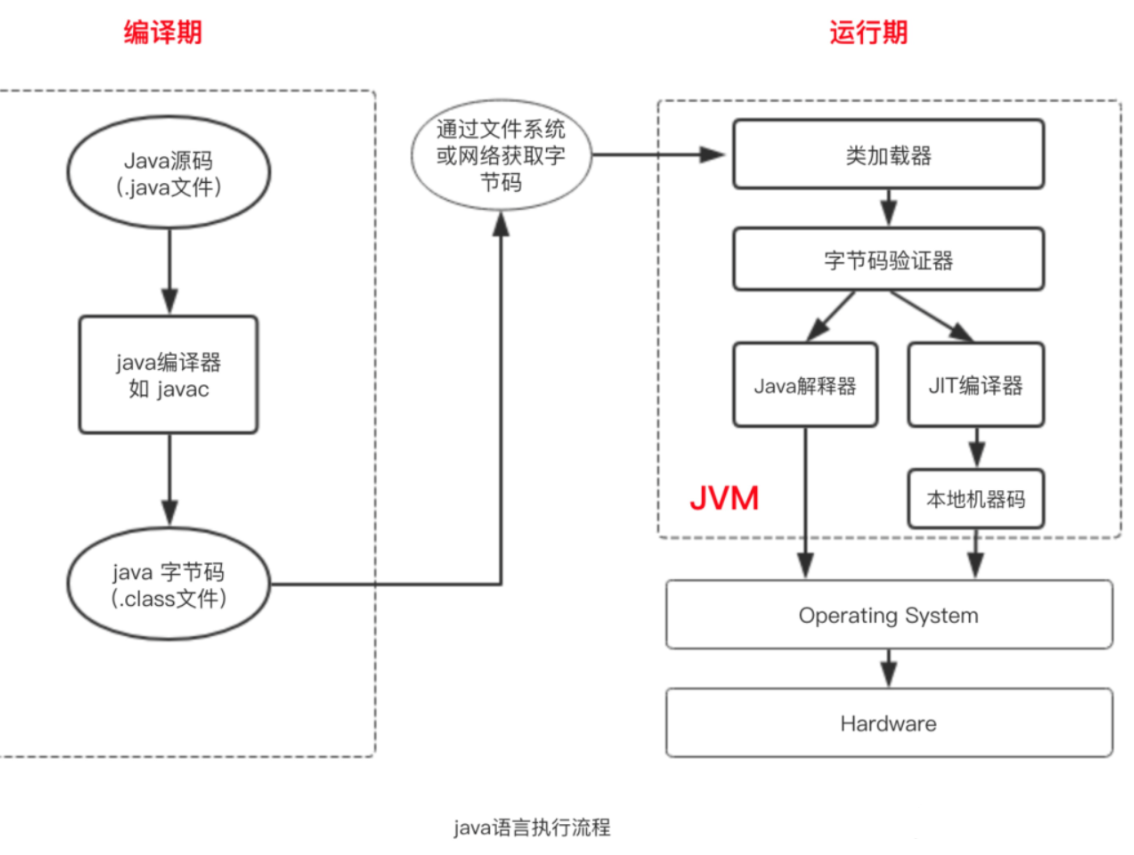
1. 基本流程如下:
编译期:检查是否有语法错误,如果没有就将其翻译成字节码文件。即.class文件。
运行期:java虚拟机分配内存,解释执行字节码文件。
例如下面的的代码
public class MyApp { public static void main(String[] args) { System.out.println("hello world"); } }
假如我们写了一个MyApp.java,并要打印‘hello world’ 那它需要经过哪些步骤?
第一步:compile
通过编译器进行编译,从Java源码 ---> Java 字节码
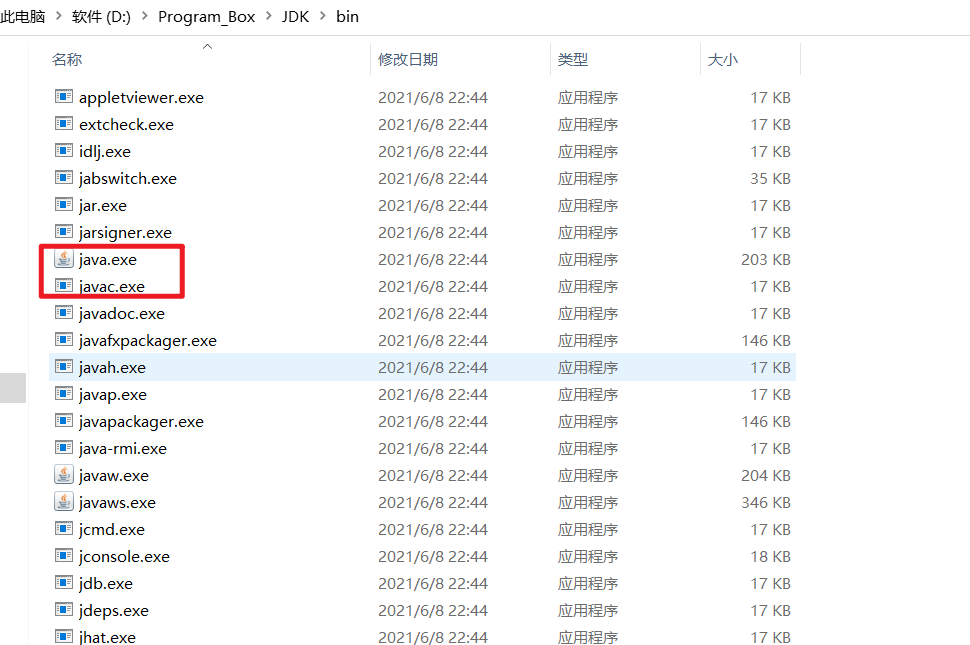
这个编译器则是jdk 里的javac 编译器,我们只需 javac MyApp.java 即可以编译该源码,javac 编译器位于jdk --> bin -->javac
第二步:load and execute
可以通过jdk 里的java命令运行java字节码,我们只需 java MyApp.class 即可加载并执行该字节码,当运行java命令时,JRE将与您指定的类一起加载。然后,执行该类的主要方法。
java命令位于jdk --> bin -->java。如上图的方框内.
===============================================分割线===============================================
2. 编译期间都做了什么?
编译期都做了什么?从我们使用者角度看无非就是把源代码编译成了可被虚拟机执行的字节码,但是从平台(编译器)角度看,它所经历的流程还不少。
毕竟总不能给你什么以.java为后缀的文件都进行编译吧,需要有各种校验解析步骤
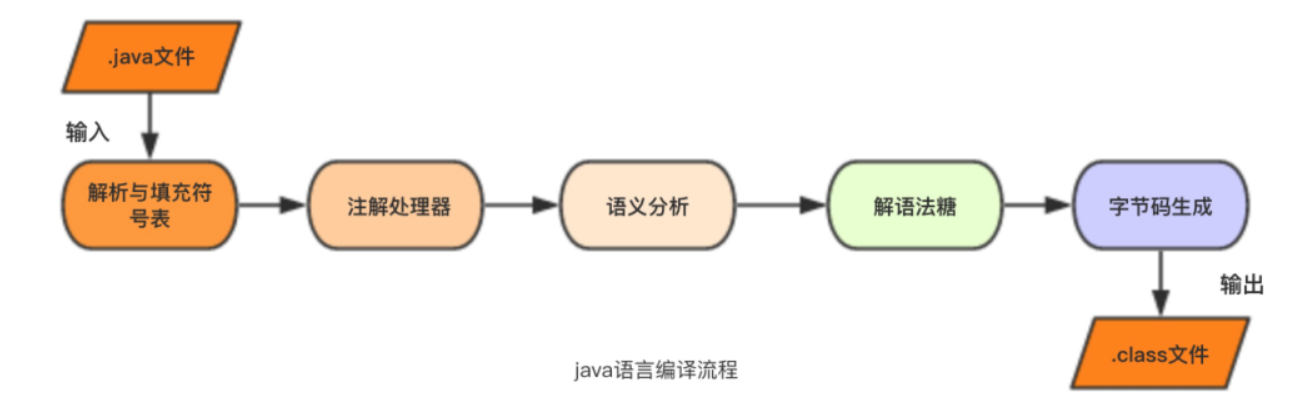
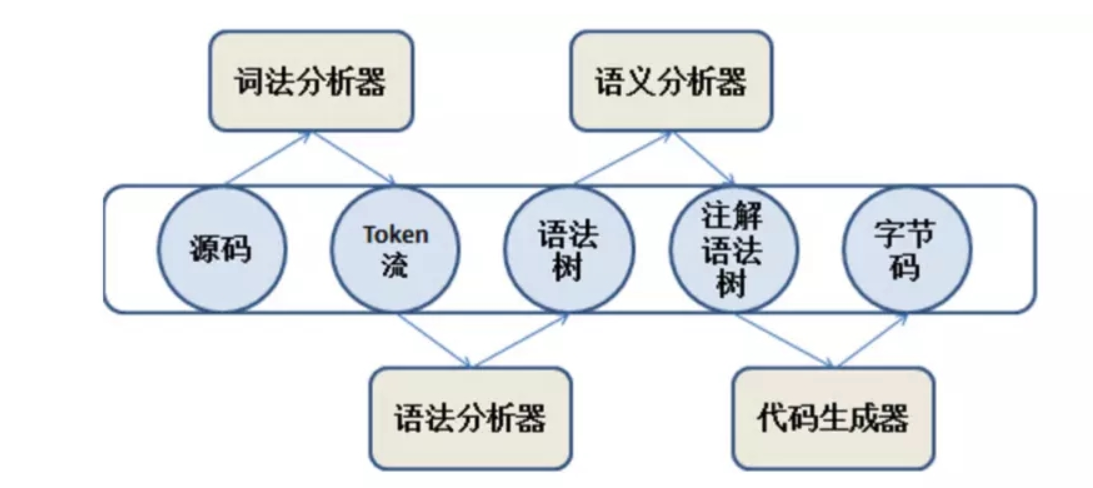
2.1 解析与填充符号表
词法语法分析
词法分析是指把源代码的字符流转为标记(Token)集合,标记(Token)是编译阶段的最小单元,字符则是编程阶段源码的最小单元。
比如,int i = 0由4个标记构成分别是「int,i,=,0」编译器只认识这些标记,词法分析过程就是识别一个个标记的过程。
然而,语法分析则是把生成的标记集合 构成一个语法树,每个节点代表程序代码中的语法结构,如包,类型,修饰符,运算符等等。
填充符号表
通过了上面的词义语义分析之后我们需要把数据存起来,以供后续流程使用,编译器会以key-value的形式存储数据,以符号地址为key符号信息为value,具体形式没做限制可以是树状符号表或者有序符号表等。
在语义分析中,根据符号表所登记的内容 语义检查和产生中间代码,在目标代码生成阶段,当对符号表进行地址分配时,该符号表是检查的依据。
注: 说白了就是编译器做的一些优化操作,比如


再比如:
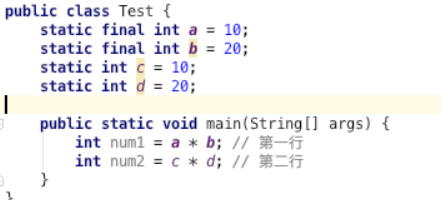
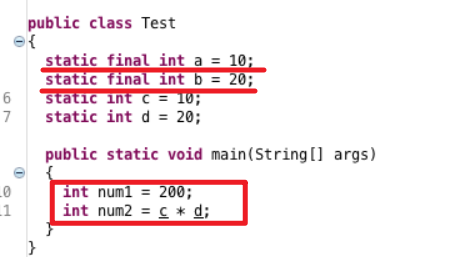
可以思考下,第一行跟第二行在编译时期有什么区别?
java编译时会做一些优化操作。第一行,因为是两个常量做运算,那么他们的结果就是确定的,即num1的值是确定的。所以在编译时,编译器就会直接算出num1的值。第二行则不会,java在运行时期才为变量分配内存空间。
所以Eclipse编译得到.class文件,打开class反编译后可以得到如下代码:
2.2 注解处理器
注解与普通的Java代码一样,是在运行期间发挥作用的。我们可以把它看做是一组编译器的插件,在这些插件里面,可以读取、修改、添加抽象语法树中的任意元素。
如果这些插件在处理注解期间对语法树进行了修改,编译器将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止。
换句话说当我们处理注解时如果修改了语法树的话会重新执行分析以及符号填充过程,把注解也填充进来,直到处理完所有注解。
2.3 语义分析 ( 语法不等于语义, 语法就是写代码的规范,而语义就是代码中的一个个Java关键字或者保留字等构成的结点, 最终形成一个语法树, 可以参考数据结构中的二叉树等知识)
语法分析以及处理注解之后,编译器获得了程序代码的抽象语法树,语法树能表示一个结构正确的源程序的抽象,但无法保证源程序是符合逻辑的。
说白了,语法树上的内容单个来说是合法的, 但是结合到上下文语义则未必是合法的。
比如定义了两个变量
int a = 1; //定义int类型就要使用int, 不能使用String来定义, 这才符合Java语义, 语义分析也就是这个意思 <可以参考编译原理这本书> boolean b = false; int c = a + b
以上 都能构成结构正确的语法树,但是根据语义分析之后编译是通不过,Java语言中是不合乎逻辑的。
2.4 解语法糖
Java 中最常用的语法糖主要有泛型、变长参数、条件编译、自动拆装箱、内部类等。虚拟机并不支持这些语法,它们在编译阶段就被还原回了简单的基础语法结构,这个过程成为解语法糖。
换句话说,不论你是否使用Java的语法糖,最终到jvm哪里的时候都是一样的,jvm不支持语法糖,所以需要编译阶段解语法糖,语法糖的初衷是用来提升开发效率,而不是代码性能。
另附:
1、方法重载是在编译时执行的。因为在编译的时候,如果调用了一个重载的方法,那么编译时必须确定他调用的方法是哪个。如:当调用evaluate("hello")时候,我们在编译时就可以确定他调用的method evaluate
2、方法重写是在运行时进行的。这个也常被称为运行时多态的体现。编译器是没有办法知道它调用的到底是那个方法,相反的,只有在jvm执行过程中,才知晓到底是父子类中的哪个方法被调用了。如下:

3、泛型(类型检测)
这也正是泛型的好处之一,可以提前暴露问题,而不是等到运行时出现ClassCastException。编译器会在编译时对泛型类型进行检测,并把它重写成实际的对象类型(非泛型代码),这样就可以被JVM执行了。这个过程被称为"类型擦除"。
类型擦除的关键在于从泛型类型中清除类型参数的相关信息,并且再必要的时候添加类型检查和类型转换的方法。
类型擦除可以简单的理解为将泛型java代码转换为普通java代码,只不过编译器更直接点,将泛型java代码直接转换成普通java字节码。类型擦除的主要过程如下:
1). 将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。
2). 移除所有的类型参数。
4. 注解。注解即有可能是运行时也有可能是编译时
如java中的@Override注解就是典型的编译时注解,他会在编译时会检查一些简单的如拼写的错误(与父类方法不相同)等
同样的@Test注解是junit框架的注解,他是一个运行时注解,他可以在运行时动态的配置相关信息如timeout等。
5. 异常。异常即有可能是运行时异常,也有可能是编译时异常
RuntimeException是一个用于指示编译器不需要检查的异常。RuntimeException 是在jvm运行过程中抛出异常的父类。对于运行时异常是不需要再方法中显示的捕获或者处理的,如NullPointerException,ArrayIndexOutOfBoundsException
已检查的异常是被编译器在编译时候已经检查过的异常,这些异常需要在try/catch块中处理的异常。
6. AOP. Aspects能够在编译时,预编译时以及运行时使用
1). 编译时:当你拥有源码的时候,AOP编译器(AspectJ编译器)能够编译源码并生成编织后的class。这些编织进入的额外功能是在编译时放进去的。
2). 预编译时:织入过程有时候也叫二进制织入,它是用来织入到哪些已经存在的class文件或者jar中的。
3). 运行时:当被织入的对象已经被加载如jvm中后,可以动态的织入到这些类中一些信息。
7、继承:继承是编译时执行的,它是静态的。这个过程编译后就已经确定
8、代理(delegate):也称动态代理,是在运行时执行
实际上在java中只支持编译时继承。Java语言原生是不支持运行时时继承的。一般情况下所谓编译时继承如下:
如上有两个类,其中Child为Parent的子类。当我们创建一个Parent实例的时候(无论实际对象为Parent还是Child),编译器在编译期间会将其替换成实际类型。所以继承实际上在编译时就已经确定了。
而在java中,可以设计通过组合模式来尝试,模拟下所谓的运行时继承。

在Child类中,其中有一个Parent实例。通过这种方式,我们动态的child类中代理了parent的相关功能。
2.5 字节码生成
字节码生成是Javac编译过程的最后一个阶段,在Javac源码里面由com.sun.tools.javac. jvm.Gen类来完成。
字节码生成阶段前面各个步骤所生成的信息(语法树、符号表)转化成字节码写到磁盘中,主要工作就是把语法树和符号表加工成字节码文件。
因此, 编译时期进行的操作也可以总结为
===============================================分割线===============================================
3. 运行期间都做了什么?
java的运行期主要是处理编译器产生的字节码,包括加载与执行。
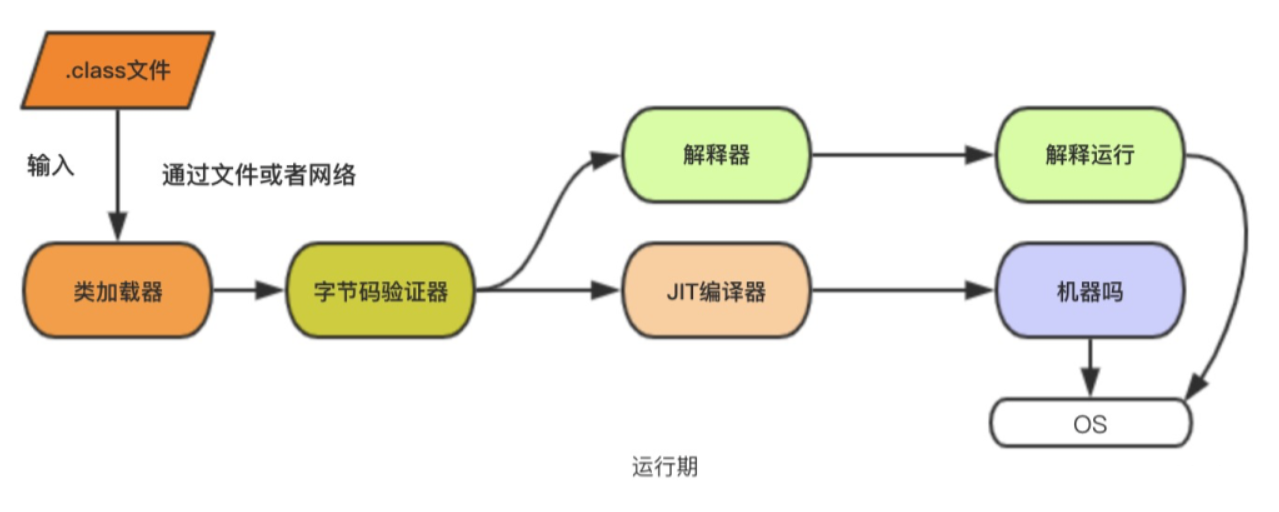
从jvm加载字节码文件,到使用到最后的卸载过程,都是属于运行期的范畴。

1. 加载
( 当字节码还没被类加载器加载之前它目前还处于虚拟机外部存储空间里,要想执行它需要通过类加载器来加载到虚拟机的运行时内存空间里。加载器的任务就是把字节码资源载入到虚拟机运行时环境里)
将类的.class文件中的二进制数据读到内存中,将其放在运时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。
加载.class文件的方式:
- 从本地系统上直接加载。
- 通过网络下载.class文件。
- 从zip,jar等归档文件中加载.class文件。
- 将java源文件动态编译为.class文件
2. 验证
(当类加载器将新加载的字节码呈现给虚拟机时,首先由验证器来检查验证这些字节码。验证程序检查指令是否无法执行明显有害的操作。除系统类之外的所有类都需要经过验证。也可以使用命令-noverify选项来停用验证。)
- 类文件的结构检查 确保类文件总符合ava类文件的固定格式
- 语义检查 确保类本身符合java语言的语法规定
- 字节码验证 确保字节码流可以被java虚拟机安全的执行。(静态方法,实例对象)
- 二进制兼容性的验证 引用类之间协调一致。
3. 准备
java虚拟机对类的静态变量分配内存,并设置初始值。如static int此时为0.
4. 初始化
java虚拟机执行类的初始化语句,为类的静态变量赋予初始值。
两种初始化方法:
- 在静态变量的声明处进行初始化。
- 在静态代码块中进行初始化。
5. 使用
程序运行过程。
6. 卸载
垃圾回收机制相关。对无引用的对象进行回收。