原文地址:http://www.cnblogs.com/zhangyinhua/p/8037599.html
一、Jsoup概述
1.1、简介
1.2、Jsoup的主要功能
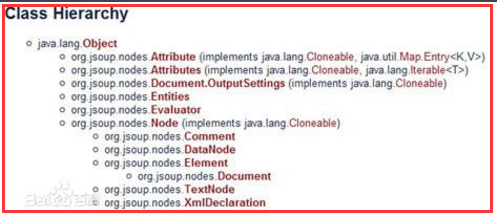
1.3、jsoup 的主要类层次结构
二、入门
2.1、解析和遍历一个HTML文档
String html = "<html><head><title>First parse</title></head>" + "<body><p>Parsed HTML into a doc.</p></body></html>"; Document doc = Jsoup.parse(html);
<p>Lorem <p>Ipsum parses to <p>Lorem</p> <p>Ipsum</p>
它可以自动将 <td>Table data</td>包装成<table><tr><td>?
html标签包含head 和 body,在head只出现恰当的元素
2.2、一个文档的对象模型
三、输入
3.1、解析一个HTML字符串
String html = "<html><head><title>First parse</title></head>" + "<body><p>Parsed HTML into a doc.</p></body></html>"; Document doc = Jsoup.parse(html);
3.2、解析一个body片断
String html = "<div><p>Lorem ipsum.</p>"; Document doc = Jsoup.parseBodyFragment(html); Element body = doc.body();
3.3、从一个URL加载一个Document
Document doc = Jsoup.connect("http://example.com/").get();
String title = doc.title();
Document doc = Jsoup.connect("http://example.com";)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.post();
3.4、从一个文件加载文档
File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/";);
四、数据抽取
4.1、使用DOM方法来遍历一个文档

File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
3)说明
Elements这个对象提供了一系列类似于DOM的方法来查找元素,抽取并处理其中的数据。具体如下:
A:查看元素
getElementById(String id) getElementsByTag(String tag) getElementsByClass(String className) getElementsByAttribute(String key) (and related methods) Element siblings: siblingElements(), firstElementSibling(), lastElementSibling(); nextElementSibling(), previousElementSibling() Graph: parent(), children(), child(int index)
B:元素数据
attr(String key)获取属性attr(String key, String value)设置属性 attributes()获取所有属性 id(), className() and classNames() text()获取文本内容text(String value) 设置文本内容 html()获取元素内HTMLhtml(String value)设置元素内的HTML内容 outerHtml()获取元素外HTML内容 data()获取数据内容(例如:script和style标签) tag() and tagName()
C:操作HTML和文本
append(String html), prepend(String html) appendText(String text), prependText(String text) appendElement(String tagName), prependElement(String tagName) html(String value)
4.2、使用选择器语法来查找元素
1)存在问题
你想使用类似于CSS或jQuery的语法来查找和操作元素。
2)方法
可以使用Element.select(String selector) 和 Elements.select(String selector) 方法实现:
File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
Elements links = doc.select("a[href]"); //带有href属性的a元素
Elements pngs = doc.select("img[src$=.png]");
//扩展名为.png的图片
Element masthead = doc.select("div.masthead").first();
//class等于masthead的div标签
Elements resultLinks = doc.select("h3.r > a"); //在h3元素之后的a元素
3)说明
jsoup elements对象支持类似于CSS (或jquery)的选择器语法,来实现非常强大和灵活的查找功能。.
这个select 方法在Document, Element,或Elements对象中都可以使用。且是上下文相关的,因此可实现指定元素的过滤,或者链式选择访问。
Select方法将返回一个Elements集合,并提供一组方法来抽取和处理结果。
A:Selector选择器概述
tagname: 通过标签查找元素,比如:a
ns|tag: 通过标签在命名空间查找元素,比如:可以用 fb|name 语法来查找 <fb:name> 元素
#id: 通过ID查找元素,比如:#logo
.class: 通过class名称查找元素,比如:.masthead
[attribute]: 利用属性查找元素,比如:[href]
[^attr]: 利用属性名前缀来查找元素,比如:可以用[^data-] 来查找带有HTML5 Dataset属性的元素
[attr=value]: 利用属性值来查找元素,比如:[width=500]
[attr^=value], [attr$=value], [attr*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href*=/path/]
[attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如: img[src~=(?i).(png|jpe?g)]
*: 这个符号将匹配所有元素
B:Selector选择器组合使用
el#id: 元素+ID,比如: div#logo
el.class: 元素+class,比如: div.masthead
el[attr]: 元素+class,比如: a[href]
任意组合,比如:a[href].highlight
ancestor child: 查找某个元素下子元素,比如:可以用.body p 查找在"body"元素下的所有 p元素
parent > child: 查找某个父元素下的直接子元素,比如:可以用div.content > p 查找 p 元素,也可以用body > * 查找body标签下所有直接子元素
siblingA + siblingB: 查找在A元素之前第一个同级元素B,比如:div.head + div
siblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ p
el, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo
C:伪选择器selectors
:lt(n): 查找哪些元素的同级索引值(它的位置在DOM树中是相对于它的父节点)小于n,比如:td:lt(3) 表示小于三列的元素
:gt(n):查找哪些元素的同级索引值大于n,比如: div p:gt(2)表示哪些div中有包含2个以上的p元素
:eq(n): 查找哪些元素的同级索引值与n相等,比如:form input:eq(1)表示包含一个input标签的Form元素
:has(seletor): 查找匹配选择器包含元素的元素,比如:div:has(p)表示哪些div包含了p元素
:not(selector): 查找与选择器不匹配的元素,比如: div:not(.logo) 表示不包含 class="logo" 元素的所有 div 列表
:contains(text): 查找包含给定文本的元素,搜索不区分大不写,比如: p:contains(jsoup)
:containsOwn(text): 查找直接包含给定文本的元素
:matches(regex): 查找哪些元素的文本匹配指定的正则表达式,比如:div:matches((?i)login)
:matchesOwn(regex): 查找自身包含文本匹配指定正则表达式的元素
注意:上述伪选择器索引是从0开始的,也就是
4.3、从元素抽取属性,本文和HTML
1)存在问题
在解析获得一个Document实例对象,并查找到一些元素之后,你希望取得在这些元素中的数据。
2)方法
要取得一个属性的值,可以使用Node.attr(String key) 方法
对于一个元素中的文本,可以使用Element.text()方法
对于要取得元素或属性中的HTML内容,可以使用Element.html(), 或 Node.outerHtml()方法
String html = "<p>An <a href='http://example.com/'><b>example</b></a> link.</p>";
Document doc = Jsoup.parse(html);//解析HTML字符串返回一个Document实现
Element link = doc.select("a").first();//查找第一个a元素
String text = doc.body().text(); // "An example link"//取得字符串中的文本
String linkHref = link.attr("href"); // "http://example.com/"//取得链接地址
String linkText = link.text(); // "example""//取得链接地址中的文本
String linkOuterH = link.outerHtml();
// "<a href="http://example.com"><b>example</b></a>"
String linkInnerH = link.html(); // "<b>example</b>"//取得链接内的html内容
3)说明
上述方法是元素数据访问的核心办法。此外还其它一些方法可以使用:
|
1
2
3
|
Element.id()Element.tagName()Element.className() and Element.hasClass(String className) |
这些访问器方法都有相应的setter方法来更改数据.
4.4、处理URLs
1)存在问题
你有一个包含相对URLs路径的HTML文档,需要将这些相对路径转换成绝对路径的URLs。
2)方法
在你解析文档时确保有指定base URI,然后
使用 abs: 属性前缀来取得包含base URI的绝对路径。代码如下:
Document doc = Jsoup.connect("http://www.open-open.com").get();
Element link = doc.select("a").first();
String relHref = link.attr("href"); // == "/"
String absHref = link.attr("abs:href"); // "http://www.open-open.com/"
3)说明
在HTML元素中,URLs经常写成相对于文档位置的相对路径: <a href="/download">...</a>.
当你使用 Node.attr(String key) 方法来取得a元素的href属性时,它将直接返回在HTML源码中指定定的值。
假如你需要取得一个绝对路径,需要在属性名前加 abs: 前缀。这样就可以返回包含根路径的URL地址attr("abs:href")
因此,在解析HTML文档时,定义base URI非常重要。
如果你不想使用abs: 前缀,还有一个方法能够实现同样的功能 Node.absUrl(String key)。
4.5、实例程序:获取所有连链接
1)说明
这个示例程序将展示如何从一个URL获得一个页面。然后提取页面中的所有链接、图片和其它辅助内容。并检查URLs和文本信息。
2)运行下面程序需要执行一个URLs作为参数
package org.jsoup.examples;
import org.jsoup.Jsoup;
import org.jsoup.helper.Validate;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/**
* Example program to list links from a URL.
*/
public class ListLinks {
public static void main(String[] args) throws IOException {
Validate.isTrue(args.length == 1, "usage: supply url to fetch");
String url = args[0];
print("Fetching %s...", url);
Document doc = Jsoup.connect(url).get();
Elements links = doc.select("a[href]");
Elements media = doc.select("[src]");
Elements imports = doc.select("link[href]");
print("
Media: (%d)", media.size());
for (Element src : media) {
if (src.tagName().equals("img"))
print(" * %s: <%s> %sx%s (%s)",
src.tagName(), src.attr("abs:src"), src.attr("width"), src.attr("height"),
trim(src.attr("alt"), 20));
else
print(" * %s: <%s>", src.tagName(), src.attr("abs:src"));
}
print("
Imports: (%d)", imports.size());
for (Element link : imports) {
print(" * %s <%s> (%s)", link.tagName(),link.attr("abs:href"), link.attr("rel"));
}
print("
Links: (%d)", links.size());
for (Element link : links) {
print(" * a: <%s> (%s)", link.attr("abs:href"), trim(link.text(), 35));
}
}
private static void print(String msg, Object... args) {
System.out.println(String.format(msg, args));
}
private static String trim(String s, int width) {
if (s.length() > width)
return s.substring(0, width-1) + ".";
else
return s;
}
}
3)查看结果
Fetching http://news.ycombinator.com/...
Media: (38)
* img: <http://ycombinator.com/images/y18.gif> 18x18 ()
* img: <http://ycombinator.com/images/s.gif> 10x1 ()
* img: <http://ycombinator.com/images/grayarrow.gif> x ()
* img: <http://ycombinator.com/images/s.gif> 0x10 ()
* script: <http://www.co2stats.com/propres.php?s=1138>
* img: <http://ycombinator.com/images/s.gif> 15x1 ()
* img: <http://ycombinator.com/images/hnsearch.png> x ()
* img: <http://ycombinator.com/images/s.gif> 25x1 ()
* img: <http://mixpanel.com/site_media/images/mixpanel_partner_logo_borderless.gif> x (Analytics by Mixpan.)
Imports: (2)
* link <http://ycombinator.com/news.css> (stylesheet)
* link <http://ycombinator.com/favicon.ico> (shortcut icon)
Links: (141)
* a: <http://ycombinator.com> ()
* a: <http://news.ycombinator.com/news> (Hacker News)
* a: <http://news.ycombinator.com/newest> (new)
* a: <http://news.ycombinator.com/newcomments> (comments)
* a: <http://news.ycombinator.com/leaders> (leaders)
* a: <http://news.ycombinator.com/jobs> (jobs)
* a: <http://news.ycombinator.com/submit> (submit)
* a: <http://news.ycombinator.com/x?fnid=JKhQjfU7gW> (login)
* a: <http://news.ycombinator.com/vote?for=1094578&dir=up&whence=%6e%65%77%73> ()
* a: <http://www.readwriteweb.com/archives/facebook_gets_faster_debuts_homegrown_php_compiler.php?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+readwriteweb+%28ReadWriteWeb%29&utm_content=Twitter> (Facebook speeds up PHP)
* a: <http://news.ycombinator.com/user?id=mcxx> (mcxx)
* a: <http://news.ycombinator.com/item?id=1094578> (9 comments)
* a: <http://news.ycombinator.com/vote?for=1094649&dir=up&whence=%6e%65%77%73> ()
* a: <http://groups.google.com/group/django-developers/msg/a65fbbc8effcd914> ("Tough. Django produces XHTML.")
* a: <http://news.ycombinator.com/user?id=andybak> (andybak)
* a: <http://news.ycombinator.com/item?id=1094649> (3 comments)
* a: <http://news.ycombinator.com/vote?for=1093927&dir=up&whence=%6e%65%77%73> ()
* a: <http://news.ycombinator.com/x?fnid=p2sdPLE7Ce> (More)
* a: <http://news.ycombinator.com/lists> (Lists)
* a: <http://news.ycombinator.com/rss> (RSS)
* a: <http://ycombinator.com/bookmarklet.html> (Bookmarklet)
* a: <http://ycombinator.com/newsguidelines.html> (Guidelines)
* a: <http://ycombinator.com/newsfaq.html> (FAQ)
* a: <http://ycombinator.com/newsnews.html> (News News)
* a: <http://news.ycombinator.com/item?id=363> (Feature Requests)
* a: <http://ycombinator.com> (Y Combinator)
* a: <http://ycombinator.com/w2010.html> (Apply)
* a: <http://ycombinator.com/lib.html> (Library)
* a: <http://www.webmynd.com/html/hackernews.html> ()
* a: <http://mixpanel.com/?from=yc> ()
五、数据修改
5.1、设置属性值
1)存在问题
在你解析一个Document之后可能想修改其中的某些属性值,然后再保存到磁盘或都输出到前台页面。
2)方法
可以使用属性设置方法 Element.attr(String key, String value), 和 Elements.attr(String key, String value).
假如你需要修改一个元素的 class 属性,可以使用 Element.addClass(String className) 和 Element.removeClass(String className) 方法。
Elements 提供了批量操作元素属性和class的方法,比如:要为div中的每一个a元素都添加一个 rel="nofollow" 可以使用如下方法:
doc.select("div.comments a").attr("rel", "nofollow");
3)说明
与Element中的其它方法一样,attr 方法也是返回当 Element (或在使用选择器是返回 Elements 集合)。
这样能够很方便使用方法连用的书写方式。比如:
doc.select("div.masthead").attr("title", "jsoup").addClass("round-box");
5.2、设置一个元素的HTML内容
1)存在问题
你需要一个元素中的HTML的内容
2)方法
可以使用Element中的HTML设置方法具体如下:
Element div = doc.select("div").first(); // <div></div>
div.html("<p>lorem ipsum</p>"); // <div><p>lorem ipsum</p></div>
div.prepend("<p>First</p>");//在div前添加html内容
div.append("<p>Last</p>");//在div之后添加html内容
// 添完后的结果: <div><p>First</p><p>lorem ipsum</p><p>Last</p></div>
Element span = doc.select("span").first(); // <span>One</span>
span.wrap("<li><a href='http://example.com/'></a></li>");
// 添完后的结果: <li><a href="http://example.com"><span>One</span></a></li>
3)说明
Element.html(String html) 这个方法将先清除元素中的HTML内容,然后用传入的HTML代替。
Element.prepend(String first) 和 Element.append(String last) 方法用于在分别在元素内部HTML的前面和后面添加HTML内容
Element.wrap(String around) 对元素包裹一个外部HTML内容。