1.如何定位并优化慢查询sql
a.根据慢日志定位慢查询sql
SHOW VARIABLES LIKE '%query%' 查询慢日志相关信息

slow_query_log 默认是off关闭的,使用时,需要改为on 打开
slow_query_log_file 记录的是慢日志的记录文件
long_query_time 默认是10S,每次执行的sql达到这个时长,就会被记录
SHOW STATUS LIKE '%slow_queries%' 查看慢查询状态

Slow_queries 记录的是慢查询数量 当有一条sql执行一次比较慢时,这个vlue就是1 (记录的是本次会话的慢sql条数)
注意:
如何打开慢查询 : SET GLOBAL slow_query_log = ON;
将默认时间改为1S: SET GLOBAL long_query_time = 1;
(设置完需要重新连接数据库,PS:仅在这里改的话,当再次重启数据库服务时,所有设置又会自动恢复成默认值,永久改变需去my.ini中改)
b.使用explain等工具分析sql
在要执行的sql前加上explain 例如:EXPLAIN SELECT menu_name FROM t_sys_menu ORDER BY menu_id DESC;

接着看explain的关键字段
type:

如果发现type的值是最后两个中的其中一个时,证明语句需要优化了。
extra:

c.修改sql或者尽量让sql走索引
mysql查询优化器会根据具体情况自己判断走哪个索引,不一定是走主键(explain中的key可以看到走的哪个key)具体情况根据具体情况来定,当你要强制执行走某一个key时:
在查询的最后加上 force index(primary); 强制走主键的
2.联合索引的最左匹配原则的成因
最左匹配原则的概念参考:https://www.cnblogs.com/lanqi/p/10282279.html

成因:
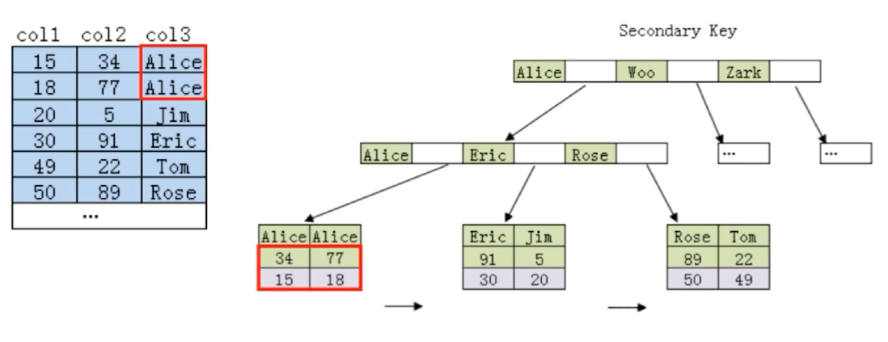
当通过(col3,col2)这样的联合索引去查找时,可以看到也是一个B+树的结构向下查找,若直接通过col2去查找,无法直接查找到34、77。也就用不到这个联合索引了。
3.索引是建立得越多越好吗
1.数据量小的表不需要建立索引,建立会增加额外的索引开销。
2.数据变更需要维护索引,因此更多的索引意味着更多的维护成本。
3.更多的索引意味着也需要更多的空间。