Pandas 是在 NumPy 基础上建立的新程序库,提供了一种高效的 DataFrame 数据结构。DataFrame 本质上是一种带行标签和列标签、支持相同类型数据和缺失值的多维数组。
3.1 安装并使用Pandas
import pandas as pd pd.__version__
'0.25.1'
3.2 Pandas对象简介
Pandas 的三个基本数据结构:Series、DataFrame 和 Index。
3.2.1 Pandas的Series对象
import numpy as np import pandas as pd data = pd.Series([0.25, 0.5, 0.75, 1.0]) print(data) print(data.values) print(data.index)
0 0.25
1 0.50
2 0.75
3 1.00
dtype: float64
[0.25 0.5 0.75 1. ]
RangeIndex(start=0, stop=4, step=1)
1. Serise是通用的NumPy数组
Series 对象和一维 NumPy 数组的本质差异其实是索引:NumPy 数组通过隐式定义的整数索引获取数值,而 Pandas 的 Series 对象用一种显式定义的索引与数值关联。
显式索引的定义让 Series 对象拥有了更强的能力。例如,索引不再仅仅是整数,还可以是任意想要的类型。也可以使用不连续或不按顺序的索引。例如:
data = pd.Series([0.25, 0.5, 0.75, 1.0], index=['a', 'b', 'c', 'd']) data = pd.Series([0.25, 0.5, 0.75, 1.0], index=[2, 5, 3, 7])
2. Series是特殊的字典
可以直接用 Python 的字典创建一个 Series 对象。
population_dict = {'California': 38332521,
'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
print(population)
California 38332521
Texas 26448193
New York 19651127
Florida 19552860
Illinois 12882135
dtype: int64
3. 创建Series对象
- pd.Series(data, index=index)
其中,index 是一个可选参数,data 参数支持多种数据类型。
3.2.2 Pandas的DataFrame对象
用前面美国五个州面积的数据创建一个新的 Series 来进行演示。
area_dict = {'California': 423967, 'Texas': 695662, 'New York': 141297,
'Florida': 170312, 'Illinois': 149995}
area = pd.Series(area_dict)
states = pd.DataFrame({'population': population,
'area': area})
print(states)

和 Series 对象一样,DataFrame 也有一个 index 属性可以获取索引标签;另外,DataFrame 还有一个 columns 属性,是存放列标签的 Index 对象。
print(states.index) print(states.columns)
Index(['California', 'Texas', 'New York', 'Florida', 'Illinois'], dtype='object')
Index(['population', 'area'], dtype='object')
Pandas 的 DataFrame 对象可以通过许多方式创建:
(1) 通过单个 Series 对象创建。
(2) 通过字典列表创建。任何元素是字典的列表都可以变成 DataFrame。即使字典中有些键不存在,Pandas 也会用缺失值 NaN(不是数字,not a number)来表示。
data = [{'a': i, 'b': 2 * i}
for i in range(3)]
print(pd.DataFrame(data))
print(pd.DataFrame([{'a': 1, 'b': 2}, {'b': 3, 'c': 4}]))

(3) 通过 Series 对象字典创建。如population和area的例子。
(4) 通过 NumPy 二维数组创建。假如有一个二维数组,就可以创建一个可以指定行列索引值的 DataFrame。如果不指定行列索引值,那么行列默认都是整数索引值。
pd.DataFrame(np.random.rand(3, 2),
columns=['foo', 'bar'],
index=['a', 'b', 'c'])
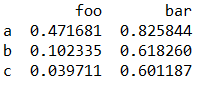
(5) 通过 NumPy 结构化数组创建。
A = np.zeros(3, dtype=[('A', 'i8'), ('B', 'f8')])
pd.DataFrame(A)

3.2.3 Pandas的Index对象
Pandas 的 Index 对象是一个很有趣的数据结构,可以将它看作是一个不可变数组或有序集合(实际上是一个多集,因为 Index 对象可能会包含重复值)。
ind = pd.Index([2, 3, 5, 7, 11]) print(ind)
Int64Index([2, 3, 5, 7, 11], dtype='int64')
ind[1]
3
ind[1] = 0
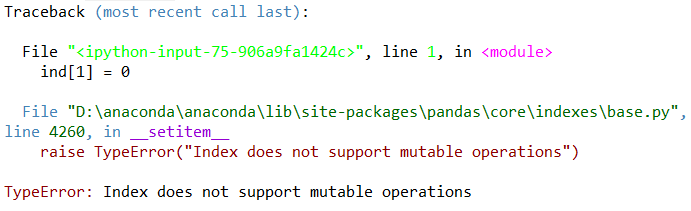
Index 对象的不可变特征使得多个 DataFrame 和数组之间进行索引共享时更加安全,尤其是可以避免因修改索引时粗心大意而导致的副作用。
还可以将Index看作有序集合,Index 对象遵循 Python 标准库的集合(set)数据结构的许多习惯用法,包括并集、交集、差集等。
indA = pd.Index([1, 3, 5, 7, 9]) indB = pd.Index([2, 3, 5, 7, 11]) print(indA & indB) # 交集 print(indA | indB) # 并集 print(indA ^ indB) # 异或
Int64Index([3, 5, 7], dtype='int64')
Int64Index([1, 2, 3, 5, 7, 9, 11], dtype='int64')
Int64Index([1, 2, 9, 11], dtype='int64')
3.3 数据取值与选择
3.3.1 Series数据选择方法
1. 将Series看作字典
和字典一样,Series 对象提供了键值对的映射;还可以用 Python 字典的表达式和方法来检测键 / 索引和值;Series 对象还可以用字典语法调整数据,就像通过增加新的键扩展字典一样。
data = pd.Series([0.25, 0.5, 0.75, 1.0], index=['a', 'b', 'c', 'd'])
# 通过键索引 print(data['b']) print('a' in data) print(data.keys()) print(list(data.items())) # 增加新数据 data['e'] = 1.25 print(data)
0.5
True
Index(['a', 'b', 'c', 'd'], dtype='object')
[('a', 0.25), ('b', 0.5), ('c', 0.75), ('d', 1.0)]
a 0.25
b 0.50
c 0.75
d 1.00
e 1.25
dtype: float64
2. 将Series看作一维数组
Series 不仅有着和字典一样的接口,而且还具备和 NumPy 数组一样的数组数据选择功能,包括索引、掩码、花哨的索引等操作。
data = pd.Series([0.25, 0.5, 0.75, 1.0, 1.25], index=['a', 'b', 'c', 'd', 'e']) # 将显式索引作为切片 print(data['a':'c']) # 将隐式整数索引作为切片 print(data[0:2]) # 掩码 print(data[(data > 0.3) & (data < 0.8)]) # 花哨的索引 print(data[['a', 'e']])
a 0.25
b 0.50
c 0.75
dtype: float64
a 0.25
b 0.50
dtype: float64
b 0.50
c 0.75
dtype: float64
a 0.25
e 1.25
dtype: float64
需要注意的是,当使用显式索引(即data['a':'c'])作切片时,结果包含最后一个索引;而当使用隐式索引(即 data[0:2])作切片时,结果不包含最后一个索引!
3. 索引器:loc、iloc和ix
由于整数索引很容易造成混淆,所以 Pandas 提供了一些索引器(indexer)属性来作为取值的方法。它们不是 Series 对象的函数方法,而是暴露切片接口的属性。
loc 属性,表示取值和切片都是显式的;而 iloc 属性,表示取值和切片都是 Python 形式的隐式索引。
3.3.2 DataFrame数据选择方法
1. 将DataFrame看作字典
area = pd.Series({'California': 423967, 'Texas': 695662,
'New York': 141297, 'Florida': 170312,
'Illinois': 149995})
pop = pd.Series({'California': 38332521, 'Texas': 26448193,
'New York': 19651127, 'Florida': 19552860,
'Illinois': 12882135})
data = pd.DataFrame({'area':area, 'pop':pop})
print(data['area'])
# 还可以以字典的语法形式调整对象
data['density'] = data['pop'] / data['area']
California 423967 Texas 695662 New York 141297 Florida 170312 Illinois 149995 Name: area, dtype: int64
2. 将DataFrame看作二维数组
可以把 DataFrame 看成是一个增强版的二维数组,用 values 属性按行查看数组数据。
print(data.values)
[[4.23967000e+05 3.83325210e+07 9.04139261e+01] [6.95662000e+05 2.64481930e+07 3.80187404e+01] [1.41297000e+05 1.96511270e+07 1.39076746e+02] [1.70312000e+05 1.95528600e+07 1.14806121e+02] [1.49995000e+05 1.28821350e+07 8.58837628e+01]]
在进行数组形式的取值时,我们就需要用另一种方法——前面介绍过的 Pandas 索引器 loc、iloc 和 ix 了。
print(data.iloc[:3, :2]) print(data.loc[:'New York', :'pop']) # 使用 ix 索引器可以实现一种混合效果 print(data.ix[:3, :'pop'])
3个输出都是:
area pop California 423967 38332521 Texas 695662 26448193 New York 141297 19651127
任何用于处理 NumPy 形式数据的方法都可以用于这些索引器。例如,可以在 loc 索引器中结合使用掩码与花哨的索引方法。
data.loc[data.density > 100, ['pop', 'density']]
pop density New York 19651127 139.076746 Florida 19552860 114.806121
3. 其他取值方法
还有一些取值方法和前面介绍过的方法不太一样。它们虽然看着有点奇怪,但是在实践中很方便。
如果对单个标签取值就选择列,而对多个标签用切片就选择行;切片也可以不用索引值,而直接用行数来实现;与之类似,掩码操作也可以直接对每一行进行过滤,而不需要使用 loc 索引器。
例如,以下索引都是合法的:
data['Florida':'Illinois'] data[1:3] data[data.density > 100]
3.4 Pandas数值运算方法
3.4.1 通用函数:保留索引
rng = np.random.RandomState(42) ser = pd.Series(rng.randint(0, 10, 4)) print(np.exp(ser)) df = pd.DataFrame(rng.randint(0, 10, (3, 4)), columns=['A', 'B', 'C', 'D']) print(np.sin(df * np.pi / 4))
0 403.428793
1 20.085537
2 1096.633158
3 54.598150
dtype: float64
A B C D
0 -1.000000 7.071068e-01 1.000000 -1.000000e+00
1 -0.707107 1.224647e-16 0.707107 -7.071068e-01
2 -0.707107 1.000000e+00 -0.707107 1.224647e-16
3.4.2 通用函数:索引对齐
当在两个 Series 或 DataFrame 对象上进行二元计算时,Pandas 会在计算过程中对齐两个对象的索引。
1. Series索引对齐
area = pd.Series({'Alaska': 1723337, 'Texas': 695662,
'California': 423967}, name='area')
population = pd.Series({'California': 38332521, 'Texas': 26448193,
'New York': 19651127}, name='population')
print(population / area)
Alaska NaN California 90.413926 New York NaN Texas 38.018740 dtype: float64
结果数组的索引是两个输入数组索引的并集,对于缺失位置的数据,Pandas 会用 NaN 填充。
如果用 NaN 值不是我们想要的结果,那么可以用适当的对象方法代替运算符。
A = pd.Series([2, 4, 6], index=[0, 1, 2]) B = pd.Series([1, 3, 5], index=[1, 2, 3]) C = A.add(B, fill_value=0) print(C)
0 2.0 1 5.0 2 9.0 3 5.0 dtype: float64
2. DataFrame索引对齐
在计算两个 DataFrame 时,类似的索引对齐规则也同样会出现在共同(并集)列中。
两个对象的行列索引可以是不同顺序的,结果的索引会自动按顺序排列。
rng = np.random.RandomState(42) A = pd.DataFrame(rng.randint(0, 20, (2, 2)), columns=list('AB')) B = pd.DataFrame(rng.randint(0, 10, (3, 3)), columns=list('BAC')) print(A + B) fill = A.stack().mean() C = A.add(B, fill_value=fill) print(C)
A B C
0 10.0 26.0 NaN
1 16.0 19.0 NaN
2 NaN NaN NaN
A B C
0 10.00 26.00 18.25
1 16.00 19.00 18.25
2 16.25 19.25 15.25
用 A中所有值的均值来填充缺失值。
Python运算符与Pandas方法的映射关系:
| Python Operator | Pandas Method(s) |
|---|---|
+ |
add() |
- |
sub(), subtract() |
* |
mul(), multiply() |
/ |
truediv(), div(), divide() |
// |
floordiv() |
% |
mod() |
** |
pow() |
3.4.3 通用函数:DataFrame与Series的运算
根据 NumPy 的广播规则,让二维数组减自身的一行数据会按行计算。在 Pandas 里默认也是按行运算的。
如果需要按列计算,那么就需要利用前面介绍过的运算符方法,通过 axis 参数设置。
rng = np.random.RandomState(42) A = pd.DataFrame(rng.randint(0, 20, (3, 4)), columns=list('QRST')) print(A) print(A-A.iloc[0]) print(A.subtract(A['R'], axis = 0))
Q R S T
0 6 19 14 10
1 7 6 18 10
2 10 3 7 2
Q R S T
0 0 0 0 0
1 1 -13 4 0
2 4 -16 -7 -8
Q R S T
0 -13 0 -5 -9
1 1 0 12 4
2 7 0 4 -1