https://zhuanlan.zhihu.com/p/158871695
最近做的小项目是协整关系用于配对交易。顺便复习了协整和相关性之间的差异。应该来说,协整关系是时间序列的一个重点内容,多次碰到,值得注意。
一、相关性(correlation)VS协整关系(cointegration)
1、相关性(correlation)
- 定义:通常是两个序列X 和 Y之间的线性依存关系(linear dependence),
- XY相关系数corr(X,Y)=0,未必独立(独立定义P(XY)=P(X)P(Y)),因为XY可能服从非线性的相关关系;而独立一定不相关。
- corr(X,Y)=0,是指X的线性组合无法解释Y。
- 相关系数介于[-1,1]之间—— ±1是完全线性相关。
- 检测相关性,pearsonr检测的是具体值之间的相关性,spearsonr检测的是rank之间的相关性(券商多因子中提到的RankIC一般就是spearmanr)。
from scipy.stats import pearsonr, spearmanr
pearson_corr, pearson_pvalue = pearsonr(X, Y)
spearnman_corr, spearnman_pvalue = spearmanr(X, Y)2、平稳性(Stationarity)
- 定义:如果数据产生过程的参数(例如均值和方差)不随着时间变化,那么数据平稳。
- 例如,时间序列
的均值和方差是常数、和时间t无关,那么
- 如果用平稳的分析刻画一个均值/方差随时间变化的时间序列,那么将会导致garbage in garbage out。
- 例如,下图series B,是一个随着时间t而均值不断增大的曲线。
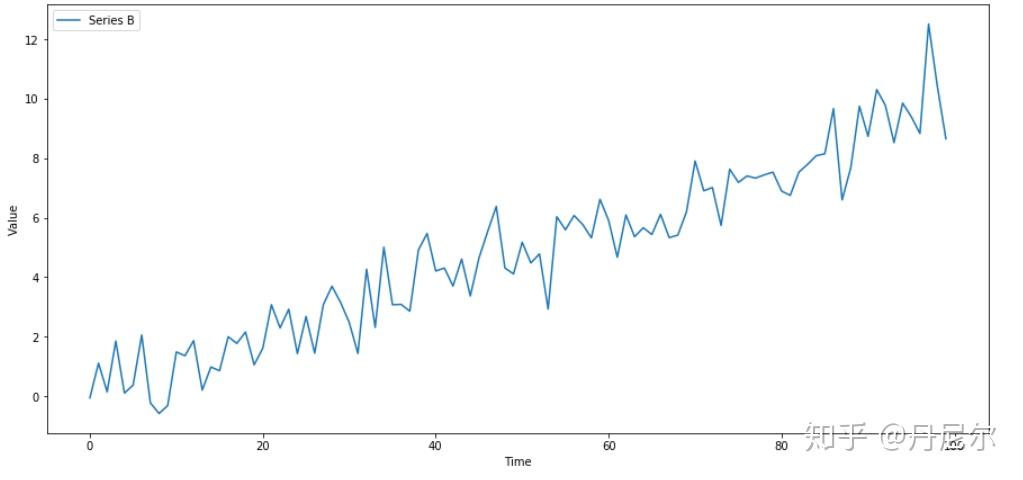
- 测试平稳性:使用augmented Dickey Fuller test,P值越小,说明越可能是平稳的时间序列。
from statsmodels.tsa.stattools import adfuller
pvalue = adfuller(some_series)[1]3、单整(Integration)——不是很重要
- 单整阶数(order of integration)
:如果一个时间序列Y的移动平均表达
,满足条件
,那么
服从
是随机过程的白噪声(残差项),
是残差项的权重,
是起决定作用的序列。
- 注意:
:如果一个序列X的一阶差分服从
- 实际运用:资产收益率一般被认为是服从
4、协整(Cointegration)
- 问题:单整
- 定义:如果
和
,那么
- 通常表达,
,其中
是平稳的时间序列,那么当回归系数
和
- 直觉
- 当两个资产价格服从协整关系的时候,那么其线性组合满足均值回复(mean reverting)的性质。
,那么从
中剔除
的影响之后,
是平稳的序列、满足均值回复。如果
超出了这个关系,那么就能够在突破上下限的时候进行套利交易。
- 测试协整关系
from statsmodels.tsa.stattools import coint
_, pvalue, _ = coint(X1, X2) P值越小,说明X1和X2的协整关系越强。
5、协整VS相关性
- 协整不一定相关
import pandas as pd
import numpy as np
from scipy.stats import pearsonr
from statsmodels.tsa.stattools import coint
import matplotlib.pyplot as plt
x1 = pd.Series(np.random.normal(0,1,1000))
x2 = x1.copy()
for i in range(10):
x2[(100*i):(100*i+100)] = (-1)**i
plt.figure(figsize=(6,3))
plt.plot(x1, c='blue')
plt.plot(x2, c='red')
plt.show()
_, pv, _ = coint(x1, x2)
print("Cointegration test p-value : ", pv)
correl, pv = pearsonr(x1, x2)
print("Correlation : ", correl)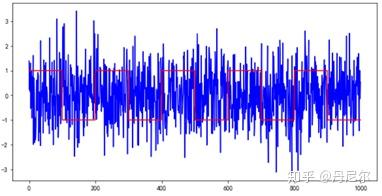
结果:协整关系非常显著p-value = 0.0;但是基本没有相关性。
- 相关不一定协整
ret1 = np.random.normal(1,1,100)
ret2 = np.random.normal(2,1,100)
s1 = pd.Series(np.cumsum(ret1))
s2 = pd.Series(np.cumsum(ret2))
plt.figure(figsize=(6,3))
plt.plot(s1)
plt.plot(s2)
plt.show()
_, pv, _ = coint(s1, s2)
print("Cointegration test p-value : ", pv)
correl, pv = pearsonr(s1, s2)
print("Correlation : ", correl)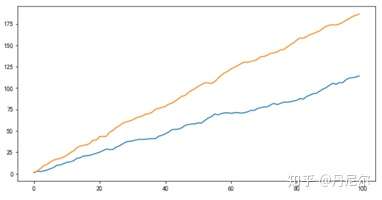
结果:相关性基本接近1,但是协整关系不显著。
因此,在配对交易策略中,协整关系是重点,相关性不用考虑。
二、配对交易策略(paris trading)
1、原理
- 因为假设X和Y服从
的关系,我们重点关注回归系数
的变化。诚然,
- 当
- 当
- 配对交易一般用于期货交易,因为期货允许short。
2、数据
链接:https://pan.baidu.com/s/1ZFfCLlk-RQ1YLTdtVldy4w
提取码:uyt4
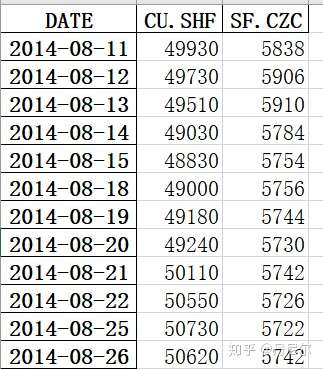
这里取出协整关系最强的期货合约“CU.SHF铜主连合约”和“SF.CZC硅铁主连合约”的日度“结算价格”数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import coint
data = pd.read_excel(r'...')
#测试相关性和协整关系
_, pv_coint, _ = coint(data['CU.SHF'], data['SF.CZC'])
corr, pv_corr = pearsonr(data['CU.SHF'], data['SF.CZC'])
print("Cointegration pvalue : %0.4f"%pv_coint)
print("Correlation coefficient is %0.4f and pvalue is %0.4f"%(corr, pv_corr))结果
Cointegration pvalue : 0.0000
Correlation coefficient is 0.8770 and pvalue is 0.0000协整关系和相关性都很强。
3、画出结算价走势
def plotSettlePrice(df, var1, var2, var1_name, var2_name, title):
temp = df[[var1, var2]].dropna()
fig = plt.figure(figsize=(10,5))
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
ax1 = fig.add_subplot(111)
ax1.plot(temp[var1], c = 'blue')
ax1.set_ylabel(var1_name)
ax1.set_title(title)
plt.legend(loc = 'upper left', labels=[var1_name])
ax1.set_xlabel('年份')
ax2 = ax1.twinx() # this is the important function
ax2.plot(temp[var2], c = 'orange')
ax2.set_ylabel(var2_name)
ax2.set_xlabel('年份')
plt.legend(loc = 'upper right', labels=[var2_name])
plt.show()
plotSettlePrice(data, 'CU.SHF', 'SF.CZC', 'CU.SHF铜', 'SF.CZC硅铁',
'CU.SHF铜 和 SF.CZC硅铁 价格走势图')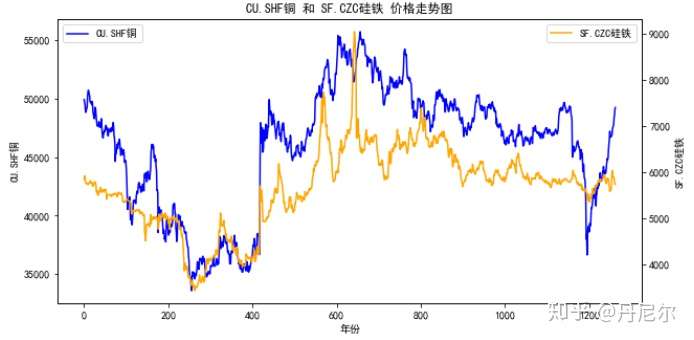
4、 计算CU.SHF结算价/SF.CZC结算价的比例Ratios
- 这个Ratios即为
- 我们默认
。
- 计算结算价比例,并且画出比例的频率直方图,基本符合正态分布。
def getRatios(df, var1, var2, plotOrNot):
df1 = df[[var1, var2]].dropna()
S1 = df1[var1]
S2 = df1[var2]
ratios = S1 / S2
if plotOrNot:
plt.figure(figsize=(10,5))
ratios.hist(bins = 200)
plt.title("Ratios histogram")
plt.ylabel('Frequency')
plt.xlabel('Intervals')
plt.show()
return S1, S2, ratios
S1, S2, ratios = getRatios(data, 'CU.SHF', 'SF.CZC', 1)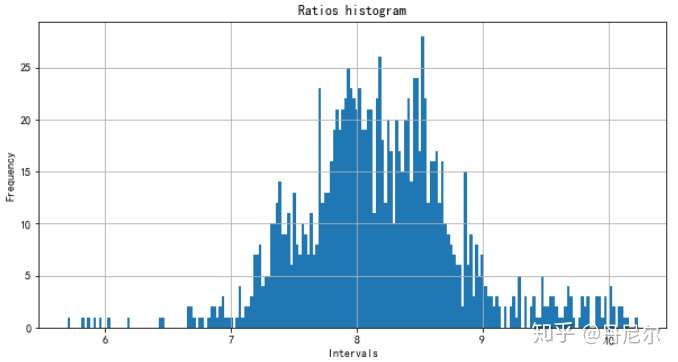
5、Z-Score
- 定义:
- ZScore将交易信号Ratios标准化处理。
- 为什么要标准化处理?
- 因为我们需要通过价格比例Ratios找到交易信号。但是Ratios的分布取决于具体的合约;而我们希望任何两个合约输入到程序中,都能够按照固定的模式找到交易信号。
- 怎样才是触发交易的信号?Ratios具体在哪个上限以上、才说明了CU更贵、SF更便宜,下降到哪个下限以下、才说明了相反情况?
- 因此,我们把Ratios标准化为Z-Score,并且认为在一个标准差(-1,1)内的波动是正常的;超过一个标准差(-∞,-1)&(1, ∞)即为触发了交易信号。这样,即便选取其他的合约,也不会受到β的不同而大改程序。
- 画出ZScore的时间走势,同时画出±1的水平直线,如果ZScore和±1的水平直线相交,我们认为触发了交易信号。
def getZScore(ratios, plotOrNot):
zScore = (ratios - ratios.mean()) / ratios.std()
if plotOrNot:
zScore.plot(figsize=(10,5))
plt.axhline(zScore.mean(), color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Ratio z-score', 'Mean', '+1', '-1'])
plt.title("zScore time series")
plt.xlabel('Date')
plt.ylabel('Intervals')
plt.show()
plt.figure(figsize=(10,5))
zScore.hist(bins = 200)
plt.title("zScore histogram")
plt.ylabel('Frequency')
plt.xlabel('Intervals')
plt.show()
return zScore
zScore = getZScore(ratios, 1)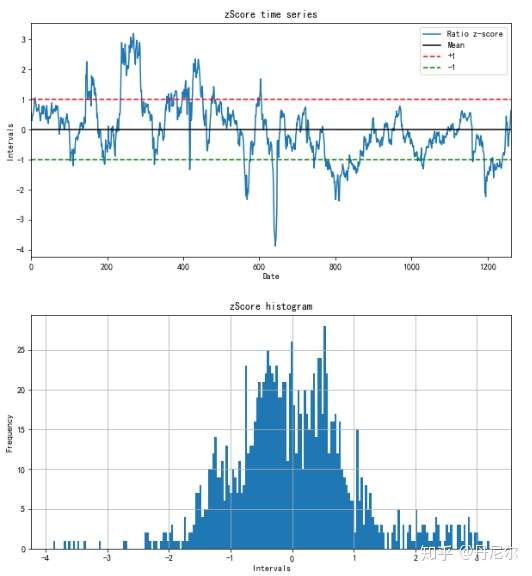
6、特征工程
- ZScore作为信号过于薄弱。因为它集中的是“整个时期”的关系;而我们交易必然是一个动态变化的过程。这里需要不断计算“一段时间”的ZScore,而不是“整个时期”的ZScore。
- 例如,在1月1号~2月1号的区间,我们得到一个ZScore,用于得到2月2号的交易信号;然后,在在1月2号~2月2号的区间,再次得到一个ZScore,用于得到2月3号的交易信号;以此类推;这是一个滚动的过程。
- 因此,我们滚动计算一段区间的ZScore。这里,我选取了Ratios滚动5日的均值、Ratios滚动60日的均值以及Ratios滚动60日的标准差,计算真正的信号ZScore_moving。
- 这里5、60的区间能够通过机器学习的算法进行调整,得到最好的结果的滚动区间。例如GPlearn。
- 同时拆分训练集和测试集。
def getMovingIndex(ratios, train_pct, w1, w2, plotOrNot):
### w1 < w2,拆分训练集+验证集,训练集的比例是train_pct
length = len(ratios)
trainLength = int(train_pct * length)
train = ratios[:trainLength]
test = ratios[trainLength:]
# 计算指标moving_average, moving_std,以及moving_z_score:这里可以使用gplearn!!
# 希望通过moving_z_score找到信号
ratios_mavg1 = train.rolling(window=w1, center=False).mean()
ratios_mavg2 = train.rolling(window=w2, center=False).mean()
std = train.rolling(window=w2, center=False).std()
zscore_mv = (ratios_mavg1 - ratios_mavg2) / std
if plotOrNot:
plt.figure(figsize=(10,5))
zscore_mv.hist(bins = 200)
plt.title("zScore with signals histogram")
plt.ylabel('Frequency')
plt.xlabel('Intervals')
plt.show()
plt.figure(figsize=(10,5))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg1.index, ratios_mavg1.values)
plt.plot(ratios_mavg2.index, ratios_mavg2.values)
plt.legend(['Ratio','%dd Ratio MA'%w1, '%dd Ratio MA'%w2])
plt.ylabel('Ratio')
plt.show()
plt.figure(figsize=(10,5))
zscore_mv.plot()
plt.axhline(0, color=