非常荣幸有机会来到清华大学的李兆基楼,去参加 tensorflow的全球巡回。本次主要介绍tf2.0的新特性和新操作。
1. 首先,tensorflow的操作过程和机器学习的正常步骤一样,(speaker: google产品经理)如图:

2. 接下来是 google tf 研发工程师,对tf2.0的新特性进行了部分讲解。
(注:eager是采用一种交互式的环境,类同于anaconda的web交互式编程)



tf还使用了分布式策略,解决单机无法解决的资源问题。

之后他也进行了tf架构的简述,经过tf训练形成的Model,可以嵌入到任何设备,包括 服务器的tensorflow serving和手机,微处理器等tensorflow lite装备。同时也支持前端,不需要网络传输,再去后端进行一系列的繁琐操作,快速的响应的tensorflow js。
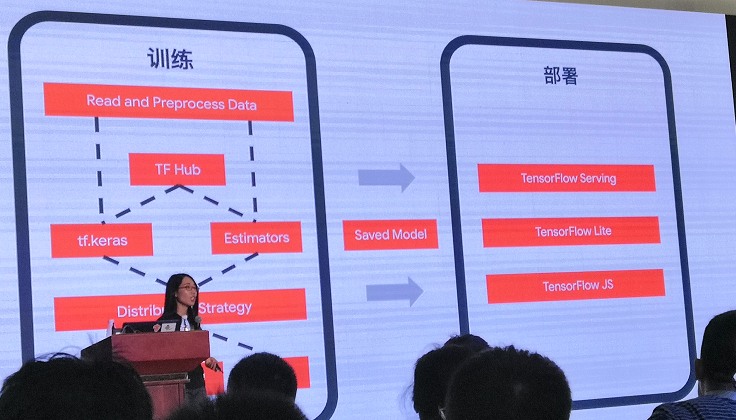
其中,tf还包括很对库,本人对tf,text较着重介绍。(tf.text -> 自然语言处理,第三部分讲,是另一个人)

之后,她对如何从tf1.0升级到2.0进行了说明(自动转化脚本可以讲1.0的代码直接升级到2.0)

具体很多细节可以参看tf的官网。

3。之后是另一个google tf的研发工程师,对tf,text进行详细的解释



情感分析:

4. 之后又介绍了tf.lite
通过在服务器训练的模型,怎么移植到手机端?



5.之后介绍了tf的分布式。
大致的策略是:每个机器的训练,经过固定迭代或者每个迭代,或者固定时间,将每个机器的误差汇总进行平均,计算完成后再统一对每个机器进行更新这一相同的值,之后再进行这一反复迭代的过程


主要有这样几个分布式:单机多GPU,多机单GPU,多机多GPU



