Isaac gym的安装要求:
NVIDIA公司推出的GPU运行环境下的机器人仿真环境(NVIDIA Isaac Gym)的安装要求——强化学习的仿真训练环境
=====================================================
下载安装文件: IsaacGym_Preview_2_Package.tar.gz

解压:
tar -zxvf IsaacGym_Preview_2_Package.tar.gz
===================================================
使用 conda 安装软件包:(Ubuntu18.04系统下,要求已经安装配置anaconda)
解压安装文件后进入安装文件夹:(本文中解压文件位置为 ~ )
cd isaacgym/python/
执行命令:
sh ../create_conda_env_rlgpu.sh

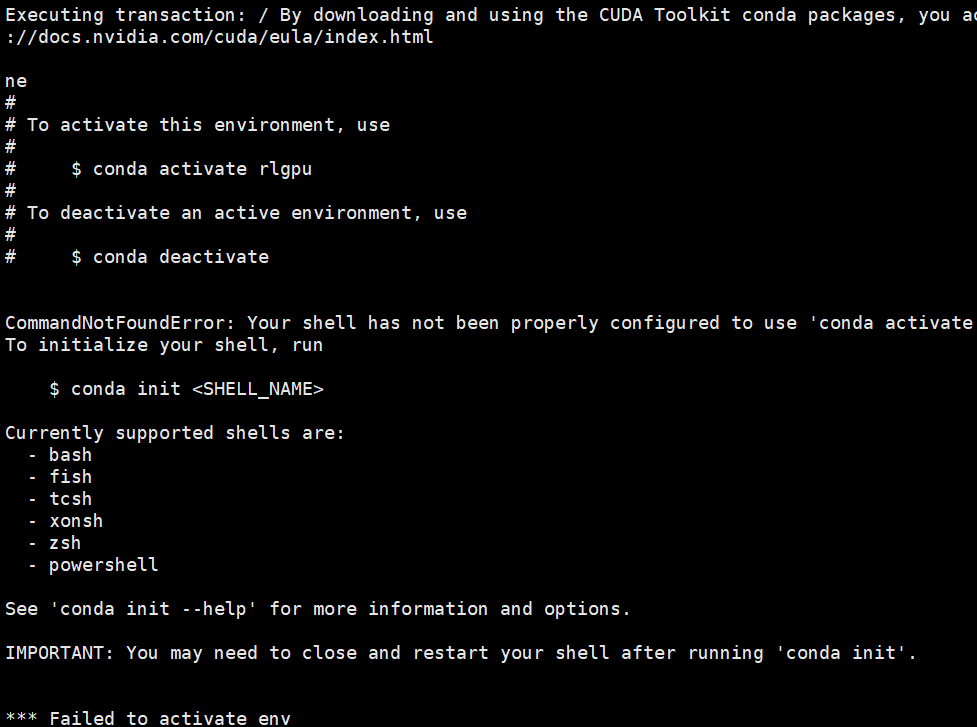
这里需要注意,虽然显示的是激活环境失败,但是这是依赖环境其实已经安装好了。
我们可以看下上步操作中具体的环境配置文件内容:cat ~/isaacgym/python/rlgpu_conda_env.yml
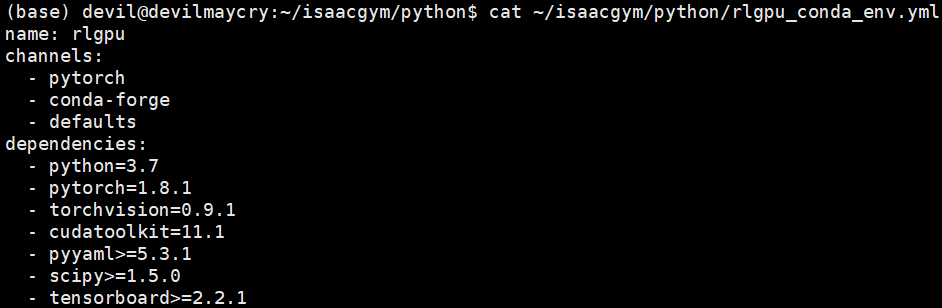
可以看到,其实安装 IsaacGym 的主要依赖环境为:
python=3.7
pytorch=1.8.1
cudatookit=11.1
其实主要的依赖环境就是上面这三个,在满足 NVIDIA公司推出的GPU运行环境下的机器人仿真环境(NVIDIA Isaac Gym)的安装要求——强化学习的仿真训练环境
的前提下,只要安装上面这三个依赖就可以安装 IsaacGym 了。
手动激活安装好的环境: conda activate rlgpu

在该环境下手动安装 IsaacGym 。
pip install -e .
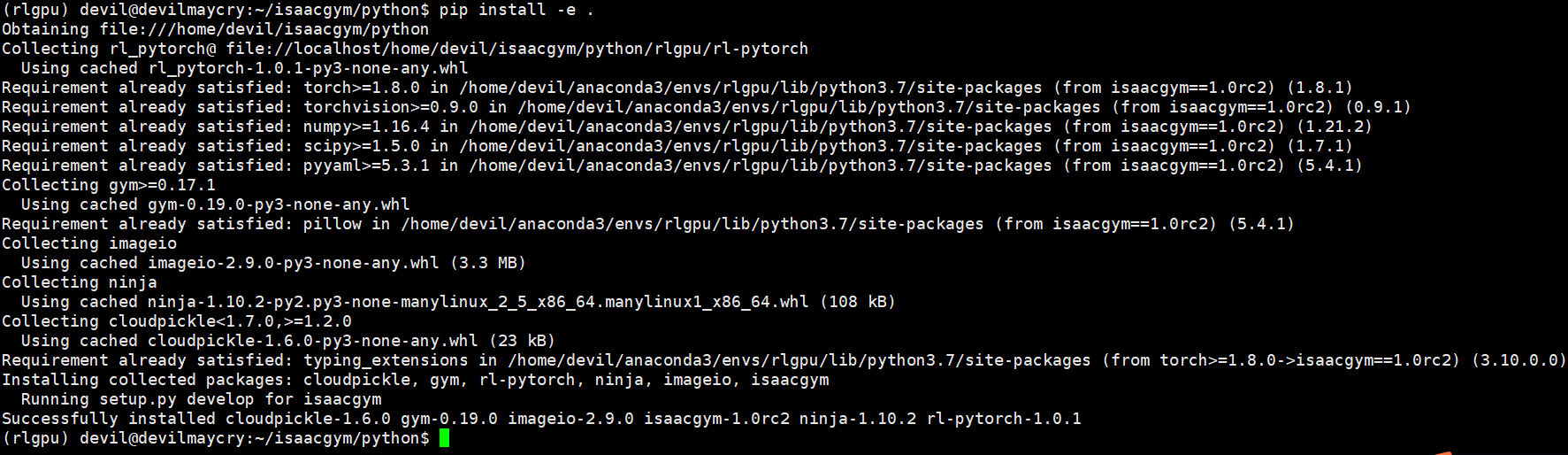
此时则完成了全部的安装。
注意这时直接运行例子是会报错的:
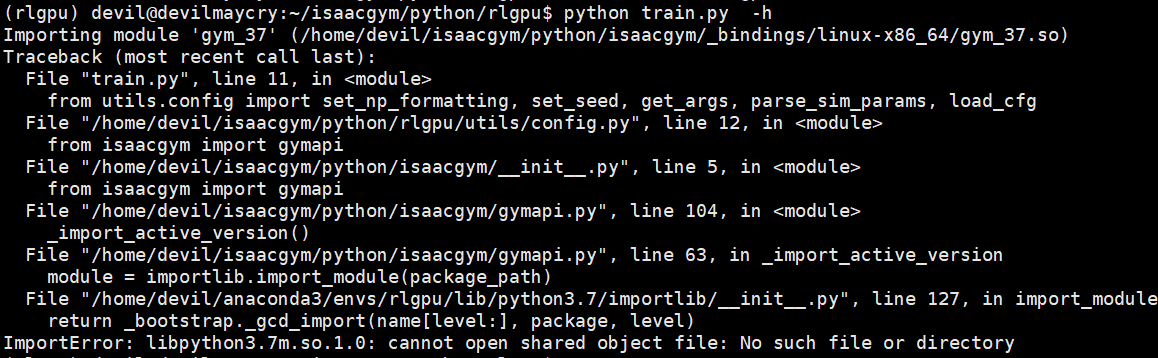
原因就是无法识别出Python库,因为 IsaacGym 我们这里采用的是默认安装,所以安装文件和原文件相同,所以在运行IsaacGym时会出现一些问题,这时我们只需要设置好动态链接库地址即可,方法:
查找当前环境下动态链接库libpython3.7m.so.1.0的位置:

设置动态链接库地址:
export LD_LIBRARY_PATH=/home/devil/anaconda3/envs/rlgpu/lib/:$LD_LIBRARY_PATH
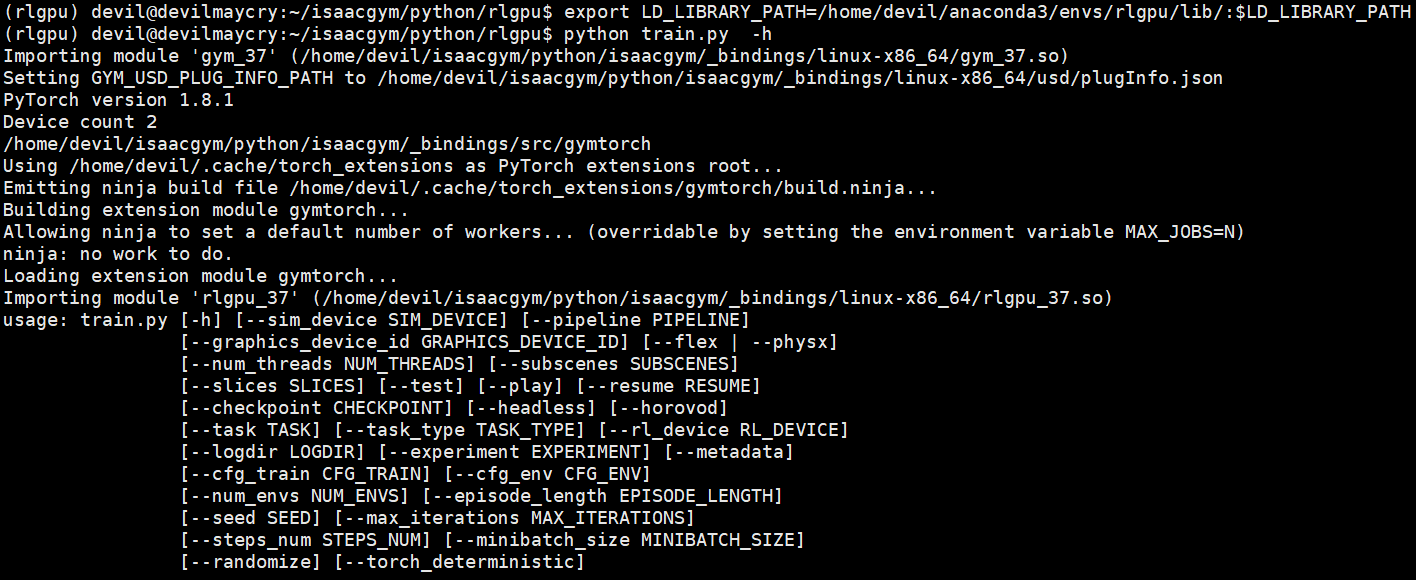
=============================================
特殊说明:
默认的 IsaacGym 安装路径为在原文件中安装,也就是说下载的原文件解压后进行安装,安装路径还是在原文件路径中,并没有把安装文件拷贝到默认的Python环境中,这也就意味着 IsaacGym 安装成功后原文件也不能删除或者移动,因为原文件和安装文件为同一个。我们可以认为 IsaacGym 的安装其实就是将原文件的路径加到了Python的默认库所识别的路径中。
安装后的原文件夹下内容:

可以看到,原文件和安装文件为同一个。
===========================================
我们可以看下安装后的文件结构:

文件夹:
examples : 是对环境进行操作的例子。
isaacgym 和 isaacgym.egg-info 是安装文件。
rlgpu 文件夹下面是使用pytorch下的PPO算法运行isaacgym的代码。
rlgpu文件夹可以看做是NVIDIA公司为仿真环境 isaacgym 写的pytorch版的PPO等常用机器人的reinforcement leanring算法代码,文件夹详情:

下面就给出几个使用rlgpu文件下的reinforcement learning代码训练isaacgym环境的例子:
下面的例子使用的文件:/home/devil/isaacgym/python/rlgpu/train.py
rlgpu下面的train.py
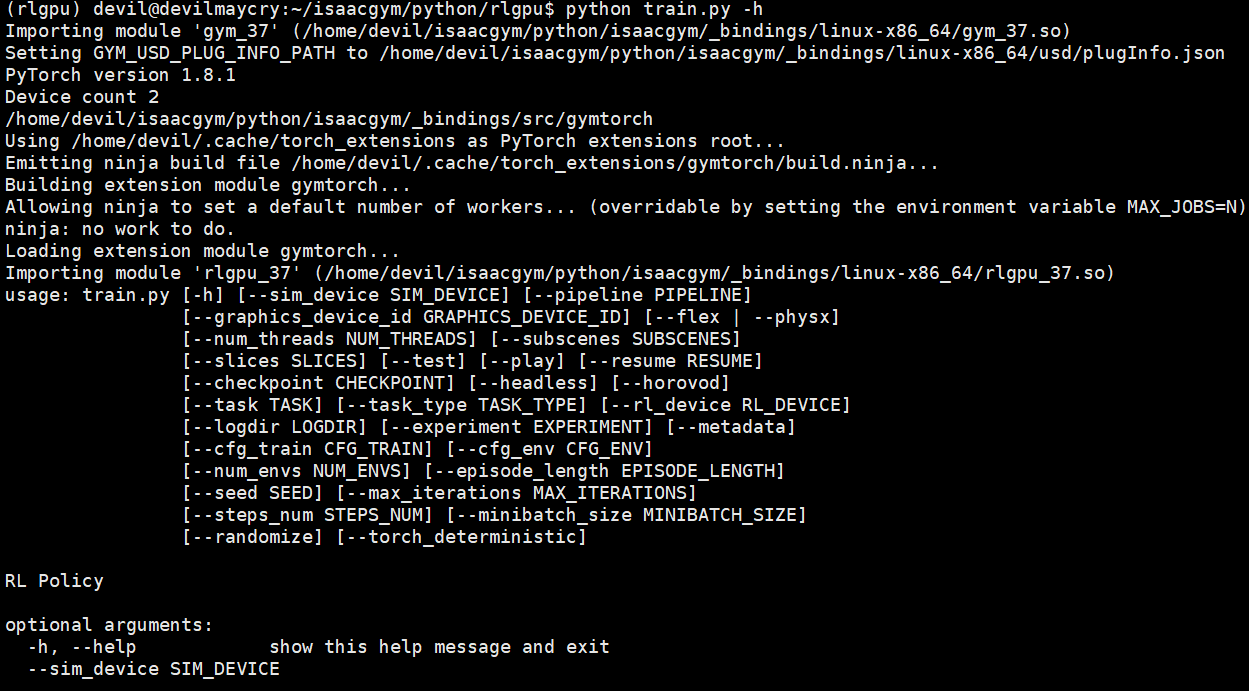
使用help解释来查看NVIDIA给出的reinforcement leanring算法命令参数:
python train.py -h
usage: train.py [-h] [--sim_device SIM_DEVICE] [--pipeline PIPELINE] [--graphics_device_id GRAPHICS_DEVICE_ID] [--flex | --physx] [--num_threads NUM_THREADS] [--subscenes SUBSCENES] [--slices SLICES] [--test] [--play] [--resume RESUME] [--checkpoint CHECKPOINT] [--headless] [--horovod] [--task TASK] [--task_type TASK_TYPE] [--rl_device RL_DEVICE] [--logdir LOGDIR] [--experiment EXPERIMENT] [--metadata] [--cfg_train CFG_TRAIN] [--cfg_env CFG_ENV] [--num_envs NUM_ENVS] [--episode_length EPISODE_LENGTH] [--seed SEED] [--max_iterations MAX_ITERATIONS] [--steps_num STEPS_NUM] [--minibatch_size MINIBATCH_SIZE] [--randomize] [--torch_deterministic] RL Policy optional arguments: -h, --help show this help message and exit --sim_device SIM_DEVICE Physics Device in PyTorch-like syntax --pipeline PIPELINE Tensor API pipeline (cpu/gpu) --graphics_device_id GRAPHICS_DEVICE_ID Graphics Device ID --flex Use FleX for physics --physx Use PhysX for physics --num_threads NUM_THREADS Number of cores used by PhysX --subscenes SUBSCENES Number of PhysX subscenes to simulate in parallel --slices SLICES Number of client threads that process env slices --test Run trained policy, no training --play Run trained policy, the same as test, can be used only by rl_games RL library --resume RESUME Resume training or start testing from a checkpoint --checkpoint CHECKPOINT Path to the saved weights, only for rl_games RL library --headless Force display off at all times --horovod Use horovod for multi-gpu training, have effect only with rl_games RL library --task TASK Can be BallBalance, Cartpole, CartpoleYUp, Ant, Humanoid, Anymal, FrankaCabinet, Quadcopter, ShadowHand, Ingenuity --task_type TASK_TYPE Choose Python or C++ --rl_device RL_DEVICE Choose CPU or GPU device for inferencing policy network --logdir LOGDIR --experiment EXPERIMENT Experiment name. If used with --metadata flag an additional information about physics engine, sim device, pipeline and domain randomization will be added to the name --metadata Requires --experiment flag, adds physics engine, sim device, pipeline info and if domain randomization is used to the experiment name provided by user --cfg_train CFG_TRAIN --cfg_env CFG_ENV --num_envs NUM_ENVS Number of environments to create - override config file --episode_length EPISODE_LENGTH Episode length, by default is read from yaml config --seed SEED Random seed --max_iterations MAX_ITERATIONS Set a maximum number of training iterations --steps_num STEPS_NUM Set number of simulation steps per 1 PPO iteration. Supported only by rl_games. If not -1 overrides the config settings. --minibatch_size MINIBATCH_SIZE Set batch size for PPO optimization step. Supported only by rl_games. If not -1 overrides the config settings. --randomize Apply physics domain randomization --torch_deterministic Apply additional PyTorch settings for more deterministic behaviour