前文:
国产计算框架mindspore在gpu环境下编译分支r1.3,使用suod权限成功编译并安装,成功运行——(修复部分bug,给出具体编译和安装过程)—— 第一部分:依赖环境的安装
我们已经进行了依赖环境的安装,本篇文章则是进行源码的下载及编译,并安装编译后的文件并运行以测试是否成功。
========================================================================
必要环境已经全部安装好,开始编译工作,源代码下载:
git clone https://gitee.com/mindspore/mindspore.git -b r1.3源代码下载好以后我们先不进行源码编译,因为源代码中有部分bug没有修复,如果我们直接进行编译的话则会报错。
具体信息见:
https://www.cnblogs.com/devilmaycry812839668/p/15042017.html
https://www.cnblogs.com/devilmaycry812839668/p/15054624.html
https://www.cnblogs.com/devilmaycry812839668/p/15059000.html
由文章:https://www.cnblogs.com/devilmaycry812839668/p/15059000.html
中给出的bug修复方式我们进行修改。
修改mindspore源代码 分支:r1.3 下对应的文件:
cmake/external_libs/ompi.cmake
修改后的完整内容:
if(ENABLE_GITEE) set(REQ_URL "https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.3.tar.gz") set(MD5 "f4be54a4358a536ec2cdc694c7200f0b") else() set(REQ_URL "https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.3.tar.gz") set(MD5 "f4be54a4358a536ec2cdc694c7200f0b") endif() set(ompi_CXXFLAGS "-D_FORTIFY_SOURCE=2 -O2") mindspore_add_pkg(ompi VER 4.0.3 LIBS mpi URL ${REQ_URL} MD5 ${MD5} PRE_CONFIGURE_COMMAND ./configure CONFIGURE_COMMAND ./configure) include_directories(${ompi_INC}) add_library(mindspore::ompi ALIAS ompi::mpi)
使用help参数来查看编译时参数的设置:
bash build.sh -h
---------------- MindSpore: build start ---------------- Usage: bash build.sh [-d] [-r] [-v] [-c on|off] [-t ut|st] [-g on|off] [-h] [-b ge] [-m infer|train] [-a on|off] [-p on|off] [-i] [-R] [-D on|off] [-j[n]] [-e gpu|ascend|cpu] [-P on|off] [-z [on|off]] [-M on|off] [-V 10.1|11.1|310|910] [-I arm64|arm32|x86_64] [-K] [-B on|off] [-E] [-l on|off] [-n full|lite|off] [-H on|off] [-A on|off] [-S on|off] [-k on|off] [-W sse|neon|avx|avx512|off] [-L Tensor-RT path] Options: -d Debug mode -r Release mode, default mode -v Display build command -c Enable code coverage, default off -t Run testcases, default off -g Use glog to output log, default on -h Print usage -b Select other backend, available: ge:graph engine -m Select graph engine backend mode, available: infer, train, default is infer -a Enable ASAN, default off -p Enable pipeline profile, print to stdout, default off -R Enable pipeline profile, record to json, default off -i Enable increment building, default off -j[n] Set the threads when building (Default: -j8) -e Use cpu, gpu or ascend -s Enable security, default off -P Enable dump anf graph to file in ProtoBuffer format, default on -D Enable dumping of function graph ir, default on -z Compile dataset & mindrecord, default on -n Compile minddata with mindspore lite, available: off, lite, full, lite_cv, full mode in lite train and lite_cv, wrapper mode in lite predict -M Enable MPI and NCCL for GPU training, gpu default on -V Specify the device version, if -e gpu, default CUDA 10.1, if -e ascend, default Ascend 910 -I Enable compiling mindspore lite for arm64, arm32 or x86_64, default disable mindspore lite compilation -A Enable compiling mindspore lite aar package, option: on/off, default: off -K Compile with AKG, default on -B Enable debugger, default on -E Enable IBVERBS for parameter server, default off -l Compile with python dependency, default on -S Enable enable download cmake compile dependency from gitee , default off -k Enable make clean, clean up compilation generated cache -W Enable x86_64 SSE or AVX instruction set, use [sse|neon|avx|avx512|off], default off for lite and avx for CPU -H Enable hidden -L Link and specify Tensor-RT library path, default disable Tensor-RT lib linking
启动前文安装的Python环境:
conda activate ms
从帮助信息中(-S Enable enable download cmake compile dependency from gitee , default off)我们可以知道在编译时我们可以选择使用gitee源的地址,这样会大大提供编译时依赖文件的下载速度,因此完整的编译命令如下:
bash build.sh -e gpu -S on
发现编译报错:
make: *** [all] Error 2
----------------------------------------------------------------------------------
(可忽略部分开始:)
这部分内容为定位error并修正,实际安装时不需要这一步骤:
修改编译命令,进行编译错误定位:
(默认是多线程编译,即-j8,可以快速的进行依赖文件下载和编译,但是不利于error定位,我们先使用默认的方式编译可以快速的进行依赖文件下载和部分编译)
bash build.sh -e gpu -S on -j1
提示出具体的报错信息:


[100%] Linking CXX shared library libmindspore.so [100%] Built target mindspore_shared_lib [100%] Linking CXX shared library _c_dataengine.cpython-37m-x86_64-linux-gnu.so [100%] Built target _c_dataengine Consolidate compiler generated dependencies of target engine-cache-server [100%] Building CXX object mindspore/ccsrc/minddata/dataset/engine/cache/CMakeFiles/engine-cache-server.dir/cache_hw.cc.o /tmp/mindspore/mindspore/ccsrc/minddata/dataset/engine/cache/cache_hw.cc: 在构造函数‘mindspore::dataset::CacheServerHW::CacheServerHW()’中: /tmp/mindspore/mindspore/ccsrc/minddata/dataset/engine/cache/cache_hw.cc:42:45: 错误:从类型‘int64_t* {aka long int*}’到类型‘long long int*’的转换无效 [-fpermissive] int64_t mem_avail = numa_node_size(i, &free_avail); ^~~~~~~~~~~ In file included from /tmp/mindspore/mindspore/ccsrc/minddata/dataset/engine/cache/cache_hw.h:20:0, from /tmp/mindspore/mindspore/ccsrc/minddata/dataset/engine/cache/cache_hw.cc:16: /usr/local/include/numa.h:146:11: 附注: 初始化‘long long int numa_node_size(int, long long int*)’的实参 2 long long numa_node_size(int node, long long *freep); ^~~~~~~~~~~~~~ 在全局域: cc1plus: 错误:unrecognized command line option ‘-Wno-stringop-truncation’ [-Werror] cc1plus: 错误:unrecognized command line option ‘-Wno-class-memaccess’ [-Werror] cc1plus:所有的警告都被当作是错误 mindspore/ccsrc/minddata/dataset/engine/cache/CMakeFiles/engine-cache-server.dir/build.make:148: recipe for target 'mindspore/ccsrc/minddata/dataset/engine/cache/CMakeFiles/engine-cache-server.dir/cache_hw.cc.o' failed make[2]: *** [mindspore/ccsrc/minddata/dataset/engine/cache/CMakeFiles/engine-cache-server.dir/cache_hw.cc.o] Error 1 CMakeFiles/Makefile2:3127: recipe for target 'mindspore/ccsrc/minddata/dataset/engine/cache/CMakeFiles/engine-cache-server.dir/all' failed make[1]: *** [mindspore/ccsrc/minddata/dataset/engine/cache/CMakeFiles/engine-cache-server.dir/all] Error 2 Makefile:155: recipe for target 'all' failed make: *** [all] Error 2
错误定位的文件位置:
mindspore/mindspore/ccsrc/minddata/dataset/engine/cache/cache_hw.cc:42:45
错误信息:
从类型‘int64_t* {aka long int*}’到类型‘long long int*’的转换无效 [-fpermissive]
int64_t mem_avail = numa_node_size(i, &free_avail);
从该定位到的错误可以知道是编译过程中生成的代码中存在类型转换错误,于是进行修改:
将报错语句修改为:
int64_t mem_avail = numa_node_size(i, reinterpret_cast <long long int *>(&free_avail));
然后重新进行编译即可。
(可忽略部分结束。)
----------------------------------------------------------------------------------
我们可以直接跨过上面的可忽略部分中的错误定位(即,bash build.sh -e gpu -S on -j1)直接对文件进行修改,然后重新编译:
bash build.sh -e gpu -S on
成功编译:
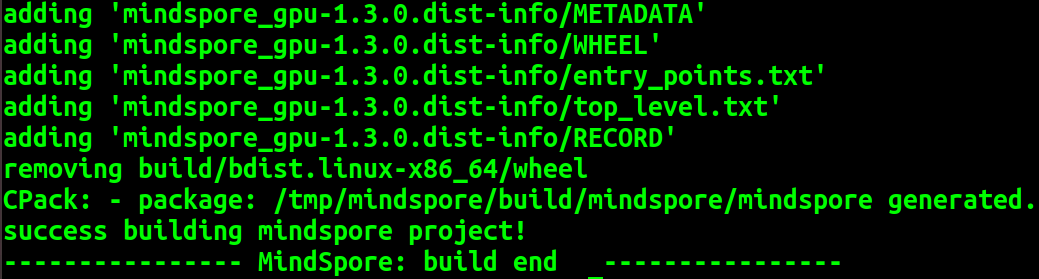
编译完成后生成的MindSpore WHL安装包路径为 build/package/mindspore_gpu-1.3.0-cp37-cp37m-linux_x86_64.whl;
将我们编译好的文件拷贝出来,在我们激活的Python环境下进行安装即可:
pip install mindspore_gpu-1.3.0-cp37-cp37m-linux_x86_64.whl
运行官网中的测试代码:
import numpy as np from mindspore import Tensor import mindspore.ops as ops import mindspore.context as context context.set_context(device_target="GPU") x = Tensor(np.ones([1,3,3,4]).astype(np.float32)) y = Tensor(np.ones([1,3,3,4]).astype(np.float32)) print(ops.tensor_add(x, y))
成功运行:
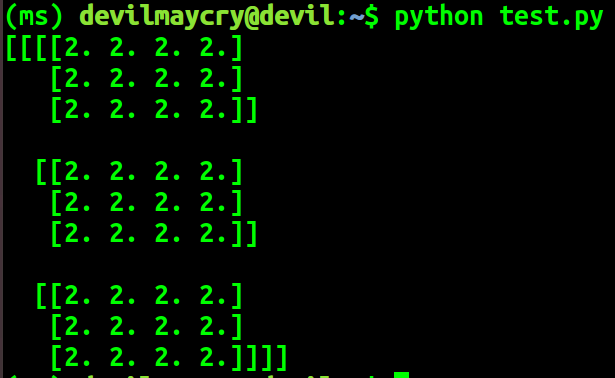
证明我们编译后的最终文件可以成功安装并运行,编译工作成功完成。