为了结合上篇 文章 https://www.cnblogs.com/devilmaycry812839668/p/13264080.html
对RTX显卡是否能够实现P2P通信功能,同时专业级别显卡的共享内存功能是需要应用程序依托NVLINK高速访存的特性进行硬编码实现的很不是nvidia显卡或驱动原生具有的特性(这是个未验证的猜想),等,进行进一步的研究,转载下文:
https://blog.csdn.net/ZIV555/article/details/52556639
------------------------------------------------------------------------
知识点回顾:虚拟地址
一个进程要对内存的某存储单元进行读写操作时,需要该内存单元的内存位置,这个时候,通过物理寻址计算出该内存位置。然而不同的进程可能修改相同位置的内存导致程序间的相互影响,因此,计算机系统引入了虚拟地址。
- 每个进程都有自己的虚拟地址空间,相互之间无法读取其他进程的内存。
- 在大多数的系统中,虚拟地址空间分为许多页(>=4KB)。
- 虚拟地址与物理地址的映射表称为页表。这个转换过程称之为 程序的再定位。
- 32位操作系统,每个进程都有4GB大小空间的内存地址,因此一般来说,物理内存是不够用的。这个时候就引入了虚拟内存(如在磁盘中开辟空间)。
CUDA的地址空间
CUDA也使用了虚拟地址空间,为的是多个CUDA程序不会相互破坏GPU内存数据。然而,GPU没有给对内存的扩展,因此,虚拟地址通过页表转化后的物理地址必须对应物理内存。
在CUDA 1.0中,CPU与GPU各自独立拥有各自的虚拟地址空间和独立内存,必须显示的将数据拷贝才能使用对方内存中的数据。在这里,GPU可以在CPU内存中分配分页锁定内存(page-locked memory),该内存是分配在CPU物理内存中的,是DMA映射的。当数据从分页锁定内存拷贝到GPU内存中时,CUDA驱动程序会自动加速该内存拷贝的操作。
另外一点,异步拷贝操作要求CPU段的内存必须是分页锁定的,需要分页锁定内存起址信息,以确保内存复制完成之前,操作系统不会取消映射或者移动物理内存。
映射分页锁定内存 mapped memory
CUDA 2.2 提供了可映射分页锁定内存的特性。CPU端的分页锁定内存可以映射到GPU地址空间中,也就是说GPU端的页表包含了GPU虚拟地址与CPU物理地址的映射。这意味着在GPU端可以直接读取CPU端内存中的数据。这种方式我们称之为zero-copy。
需要注意几点:
- CPU端和GPU端的虚拟地址空间仍然是独立的。只不过在GPU端,页表中存在了关于CPU端分页锁定内存的映射关系。
- 由于存在不同的虚拟地址空间,因此这段映射的分页锁定内存存在两种形式:一种是,在CPU的指针,由cudaMallocHost返回;另外一种,是在GPU端的指针,需要通过 cudaHostGetDevicePointer()获得(记得之前需要调用cudaSetDeviceFlags()函数来设置cudaDeviceMapHost标志)。
- 在多卡的情况下,每个GPU都会有一个上下文。则如果我们将分页锁定内存设置为“可分享的”,即cudaHostAllocPortabled标志,那么这个映射将会存在所有GPU的CUDA上下文中。
- 随着统一虚拟地址(UVA)概念的出现,这种方式将不再推荐了。具体的见下一小节的讲解。
统一虚拟寻址 unified virtual addressing
在此之前我们讲到的两种情况,CPU端和GPU端都是独立的虚拟地址空间。在CUDA 4.0中,引入了统一虚拟寻址UVA的特性。顾名思义,在支持UVA的情况下(支持的系统会自动启动UVA),CPU内存和GPU内存的虚拟地址空间是一个整体了,不再是分开的。
几点编程上的便利:
- 对于CPU端的分页非锁定内存和GPU端的内存,CUDA可以推断出来该内存指针位于那个设备上面。因此,cudaMemcpy()函数最后的形参(拷贝方向)不需要指定具体的拷贝方向了,填写一个cudaMemcpyDefault即可,剩下的就交给CUDA来辨别拷贝方向了。
- 对于CPU端分页锁定内存,在UVA模式下,默认被映射和可分享的。而且CPU端和GPU端读写该内存的指针是相同的,只需要一个指针即可。一点例外:使用cudaHostRegister转化的CPU端分页锁定内存指针,设备端的指针还需要cudaHostGetDevicePointer()函数获得。
点对点寻址 peer-to-peer
在多卡环境下编程时,我们会碰到GPU与GPU之间的数据拷贝,使用的函数为(非点对点映射,只能称之为点对点内存拷贝):
__host__ cudaError_t cudaMemcpyPeer ( void* dst, int dstDevice, const void* src, int srcDevice, size_t count ) __host__ cudaError_t cudaMemcpyPeerAsync ( void* dst, int dstDevice, const void* src, int srcDevice, size_t count, cudaStream_t stream = 0 )
在这里的两个函数,指定了源设备和目的设备的ID,指定了拷贝的两个指针,指定了拷贝的大小。
当系统支持UVA时,我们就不必指定两个设备了,CUDA可以通过指针推断出来源于那个设备。因此,只需简化使用cudaMemcpy()函数就可以了。
__host__ cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
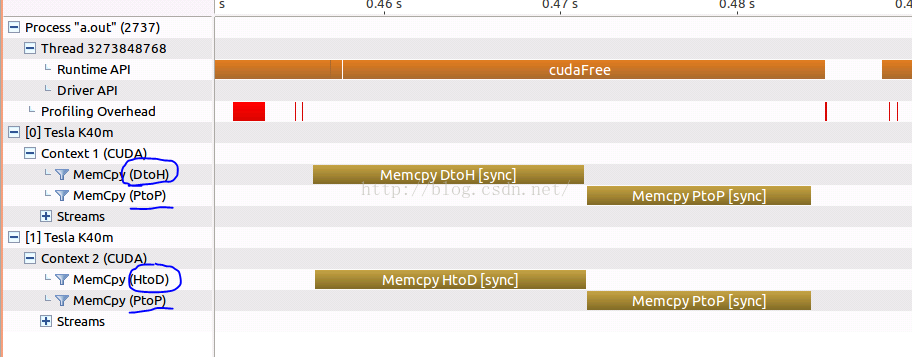
之前的这两种GPU之间数据拷贝其实是以CPU内存为媒介进行拷贝的。当我们使用nvvp软件查看GPU之间数据传输的timeline时,我们就发现整个拷贝包含两个步骤:
- SrcDevice to CPU (D2H)
- CPU to dstDevice (H2D)
这个是很耗时的。其实有一种更快的点对点寻址方式,peer-to-peer拷贝。这个特性不是默认打开的,通常我们需要这两步骤:
第一步,判断设备A是否可以通过P2P方式访问设备B:
__host__ cudaError_t cudaDeviceCanAccessPeer ( int* canAccessPeer, int device, int peerDevice )
第二步,如果可以,那么将P2P方式打开:
__host__ cudaError_t cudaDeviceEnablePeerAccess ( int peerDevice, unsigned int flags )
注意,这两步只是满足了设备A对设备B内存P2P访问,而设备B却无法对设备A P2P访问,因为这个是非对称的,仍需要使设备B对设备A做同样的操作。
当我们使用nvvp软件查看GPU之间数据传输的timeline时,我们就会发现,这是GPU之间的拷贝只包含了一个P2P的过程了。
在最后的测试用例中有相关的测试代码。
NVIDIA GPUDirect
1. 什么是GPUDirect? GPUDirect是GPU与其他设备通信的技术概括,包含了一系列的技术特性。我们在这里列举一下:

2. 2011年,增加了P2P特性,也就是我们刚才讲的GPU之间P2P的通信。因为取消了CPU内存的“媒介”功能,使得速度提升。
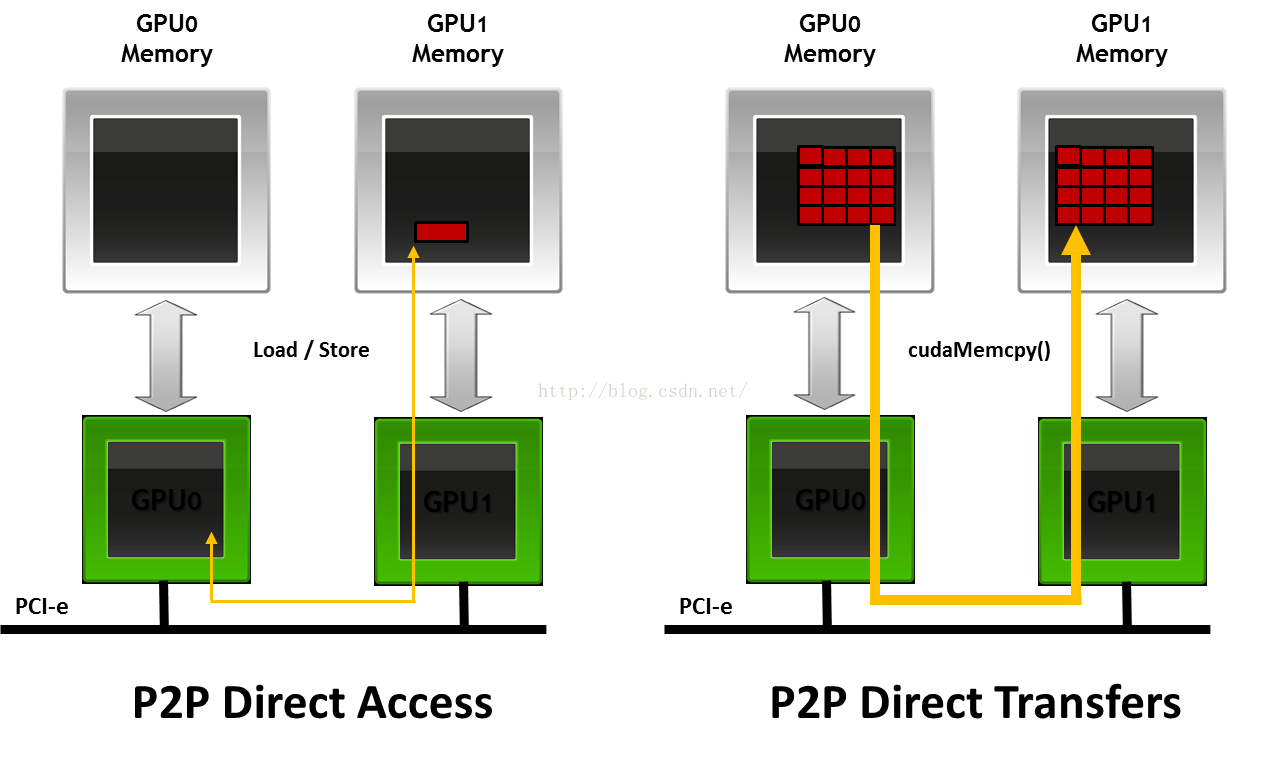
3. 2013年,引入了RDMA的特性,这个特性将使得GPU与第三方存储设备之间可以直接数据通信,同样取消了CPU内存的“媒介”功能。

测试用例
#include <stdio.h> #include <stdlib.h> #include <cuda_runtime.h> #include <helper_functions.h> #include <helper_cuda.h> #include <helper_string.h> const int num = 1 << 25; const int num_gpu = 2; int main() { int id_gpu; float *data_d[num_gpu]; //malloc for(id_gpu = 0; id_gpu < num_gpu; id_gpu++){ checkCudaErrors( cudaSetDevice(id_gpu) ); checkCudaErrors( cudaMalloc((void **)&data_d[id_gpu], num * sizeof(float)) ); }
//copy data from device 0 to device 1. checkCudaErrors( cudaSetDevice(0) ); checkCudaErrors( cudaMemcpy(data_d[1], data_d[0], num * sizeof(float), cudaMemcpyDefault) );
//p2p copy data. for (int i = 0; i < num_gpu; i++) { int p2p; for (int j = i+1; j < num_gpu; j++) { checkCudaErrors( cudaDeviceCanAccessPeer(&p2p, i, j) ); if (p2p) { printf("P2P support between device %d and %d. ", i, j); checkCudaErrors( cudaSetDevice(i) ); checkCudaErrors( cudaDeviceEnablePeerAccess(j, 0) ); checkCudaErrors( cudaSetDevice(j) ); checkCudaErrors( cudaDeviceEnablePeerAccess(i, 0) ); } else { printf("No P2P support between device %d and %d. ", i, j); } } }
checkCudaErrors( cudaSetDevice(0) ); checkCudaErrors( cudaMemcpy(data_d[1], data_d[0], num * sizeof(float), cudaMemcpyDefault) ); //cudaFree for(id_gpu = 0; id_gpu < num_gpu; id_gpu++){ checkCudaErrors( cudaSetDevice(id_gpu) ); checkCudaErrors( cudaFree(data_d[id_gpu]) ); } checkCudaErrors( cudaDeviceReset() ); return 0; }
测试结果截图(nvvp):
--------------------------------------------------------------------------------
额外自测的代码:
#include <stdio.h> #include <stdlib.h> #include <cuda_runtime.h> #include <helper_functions.h> #include <helper_cuda.h> #include <helper_string.h> const int num = 1 << 25; const int num_gpu = 2; int main() { int id_gpu; float *data_d[num_gpu]; //malloc for(id_gpu = 0; id_gpu < num_gpu; id_gpu++){ checkCudaErrors( cudaSetDevice(id_gpu) ); checkCudaErrors( cudaMalloc((void **)&data_d[id_gpu], num * sizeof(float)) ); } //copy data from device 0 to device 1. checkCudaErrors( cudaSetDevice(0) ); checkCudaErrors( cudaMemcpy(data_d[1], data_d[0], num * sizeof(float), cudaMemcpyDefault) ); //copy data from device 1 to device 0. checkCudaErrors( cudaSetDevice(1) ); checkCudaErrors( cudaMemcpy(data_d[0], data_d[1], num * sizeof(float), cudaMemcpyDefault) ); //p2p copy data. for (int i = 0; i < num_gpu; i++) { int p2p, p2p_0, p2p_1; for (int j = i+1; j < num_gpu; j++) { checkCudaErrors( cudaDeviceCanAccessPeer(&p2p_0, i, j) ); checkCudaErrors( cudaDeviceCanAccessPeer(&p2p_1, j, i) ); p2p = p2p_0 & p2p_1; if (p2p) { printf("P2P support between device %d and %d. ", i, j); checkCudaErrors( cudaSetDevice(i) ); checkCudaErrors( cudaDeviceEnablePeerAccess(j, 0) ); checkCudaErrors( cudaSetDevice(j) ); checkCudaErrors( cudaDeviceEnablePeerAccess(i, 0) ); } else { printf("No P2P support between device %d and %d. ", i, j); } } } checkCudaErrors( cudaSetDevice(0) ); checkCudaErrors( cudaMemcpy(data_d[1], data_d[0], num * sizeof(float), cudaMemcpyDefault) ); checkCudaErrors( cudaSetDevice(1) ); checkCudaErrors( cudaMemcpy(data_d[0], data_d[1], num * sizeof(float), cudaMemcpyDefault) ); //syn checkCudaErrors(cudaDeviceSynchronize()); //cudaFree for(id_gpu = 0; id_gpu < num_gpu; id_gpu++){ checkCudaErrors( cudaSetDevice(id_gpu) ); checkCudaErrors(cudaDeviceDisablePeerAccess((id_gpu+1)%2)); checkCudaErrors( cudaFree(data_d[id_gpu]) ); } checkCudaErrors( cudaDeviceReset() ); return 0; }