强化学习入门最经典的数据估计就是那个大名鼎鼎的 reinforcement learning: An Introduction 了, 最近在看这本书,第一章中给出了一个例子用来说明什么是强化学习,那就是tic-and-toc游戏, 感觉这个名很不Chinese,感觉要是用中文来说应该叫三子棋啥的才形象。

这个例子就是下面,在一个3*3的格子里面双方轮流各执一色棋进行对弈,哪一方先把自方的棋子连成一条线则算赢,包括横竖一线,两个对角线斜连一条线。
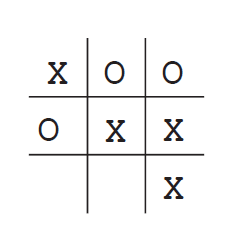

上图,则是 X 方赢,即:
reinforcement learning 的对应代码地址为:
https://github.com/ShangtongZhang/reinforcement-learning-an-introduction
该代码虽然很好,但是看起来较费力,于是自己就该它的基础上加了些注释并把结构进行了改动,具体代码如下:
源码地址:(本文给出的结构重建,注释版)
https://files.cnblogs.com/files/devilmaycry812839668/tic_tac_toe_code.zip
关于算法的解释可以具体参见书中的介绍,Reinforcement Learning:An Introduction 第一章
关于这个代码的,或者说是算法的设计主要是为了解释什么是时序差分的强化学习。
每一种状态都用一个值来表示,并用一个hash码表示,
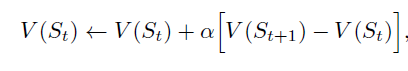
St 是此刻的棋盘状态值, St+1 是下一时刻的棋盘状态值。但是, 如果St状态到St+1 状态是因为自方进行策略探索而选择的不是最优的下一状态的动作,那么不进行此次计算。
状态值的变化树结构如下图:
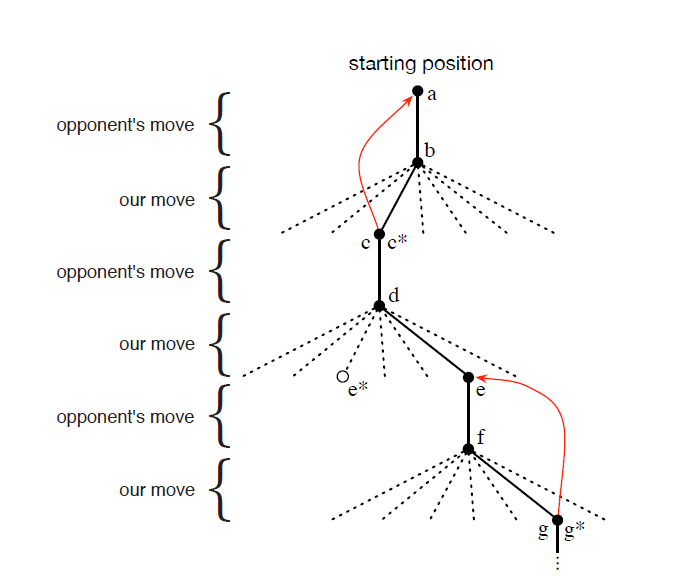
由 d 状态 到 e* 状态是此时可以选择的最优状态,但是我们选择了进入 e 状态的操作,这就是策略的探索操作。
具体的算法思想参照 reinforcement learning: An Introduction 原书。
==========================================================
目录结构如下图:

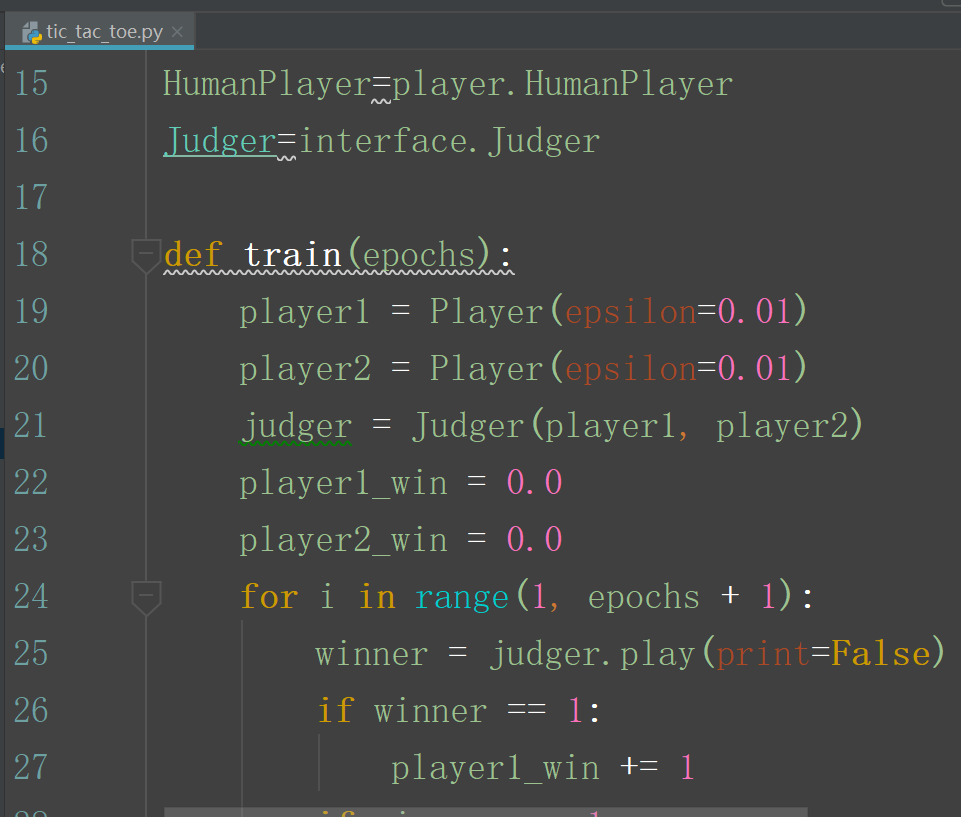
tic_tac_toe.py 是代码的主文件,需要运行该代码。
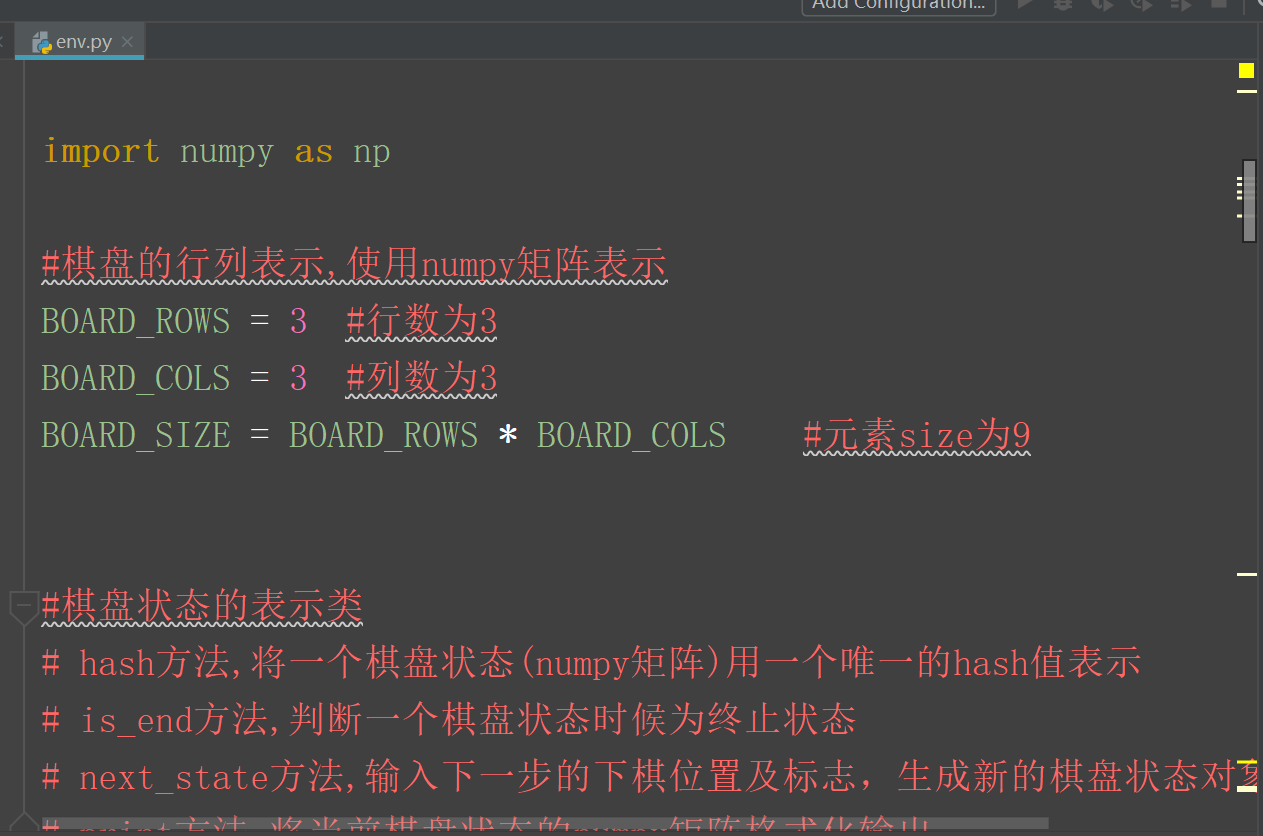
enviroment 文件夹中放的是 关于棋盘状态的类文件代码,和环境初始化的代码。

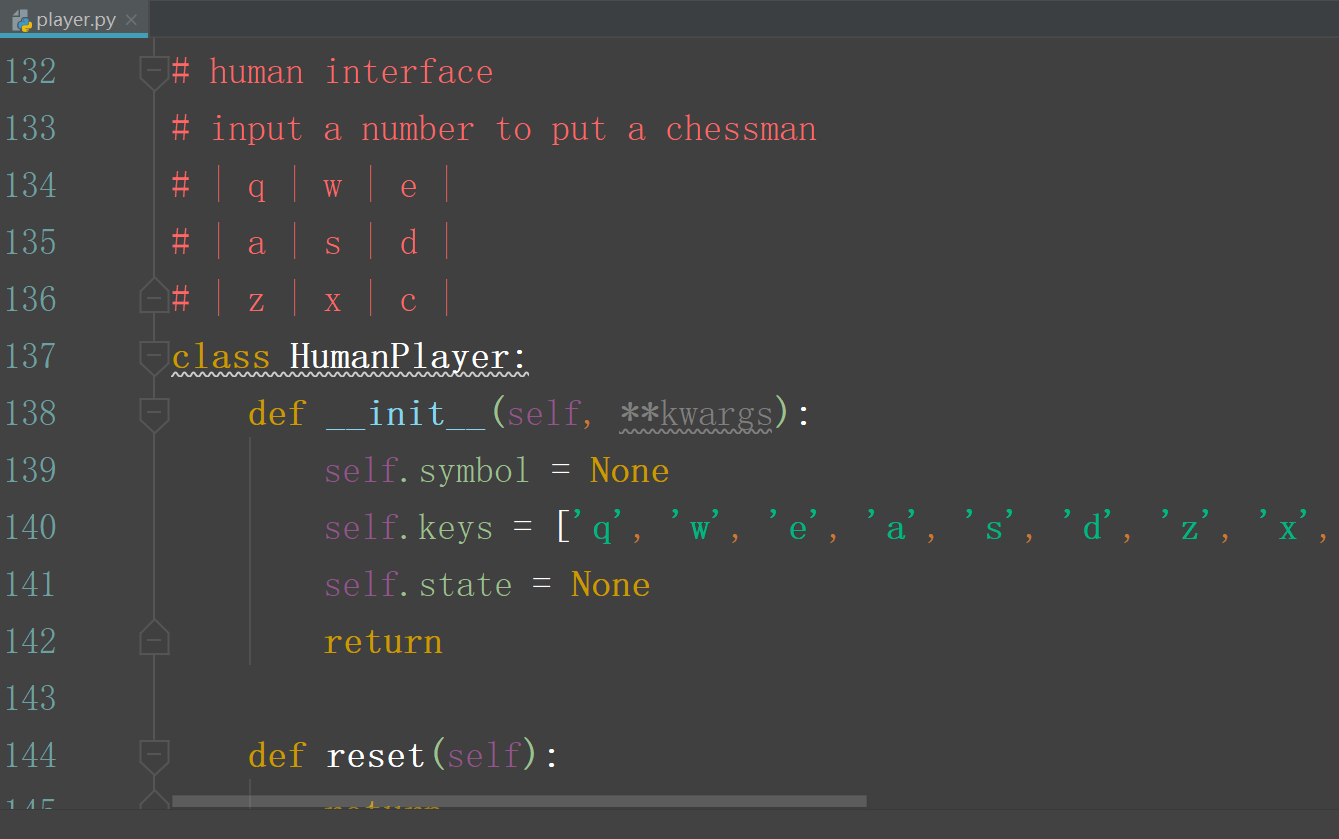
agents 文件夹中放的是 具体的下起策略中agent的代码:

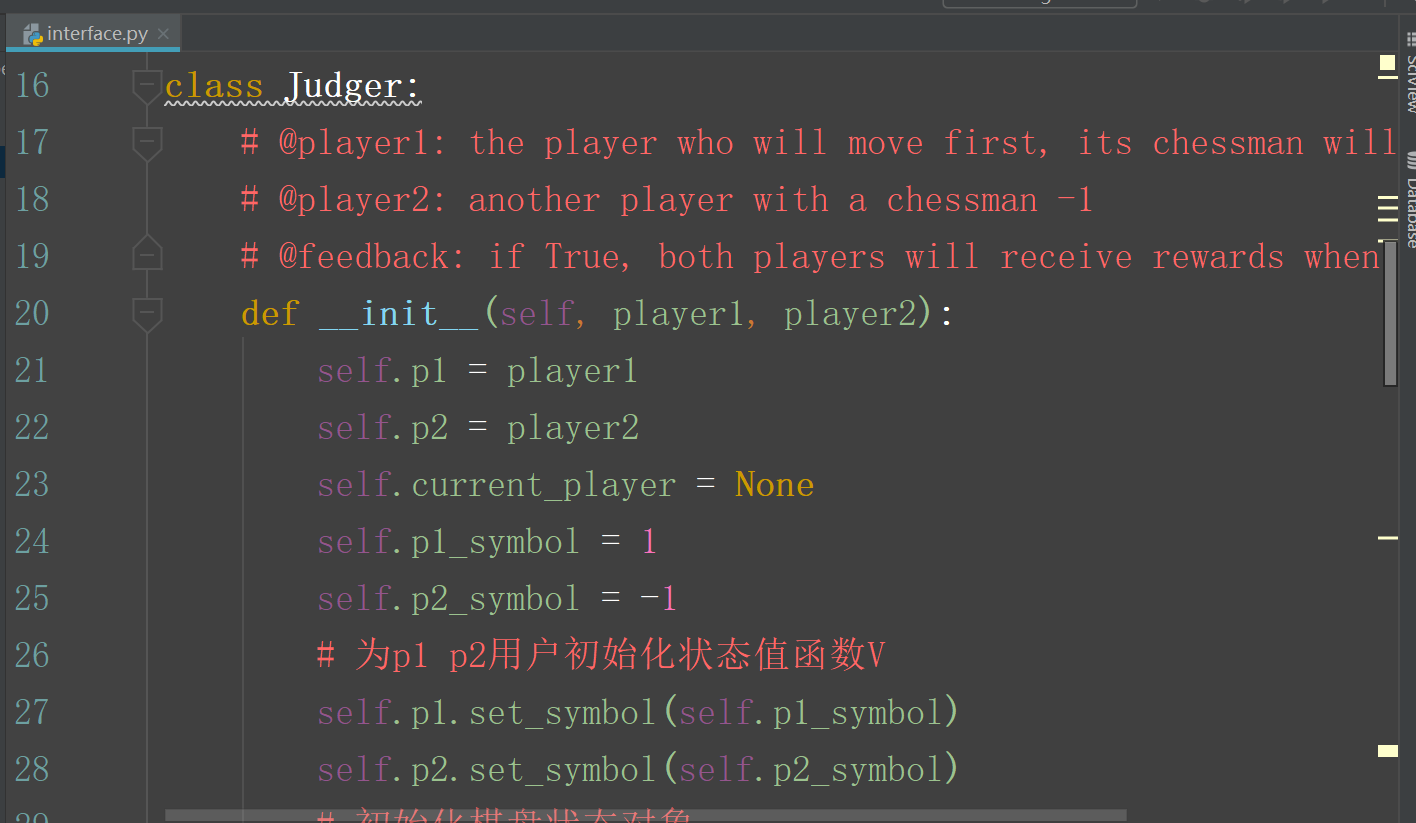
interface.py 中的代码是 agent 代码和主程序的接口文件:
主文件 tic_toe_tac.py