1.抓取数据
-- 查看慢查询收集是否开启 SHOW VARIABLES LIKE 'slow_query%'; -- 开启慢查询收集 SET GLOBAL slow_query_log='ON'; -- 查看慢查询收集的阈值 SHOW VARIABLES LIKE 'long_query_time'; -- 设置慢查询收集的阈值为3秒 SET GLOBAL long_query_time=3; -- 查看慢查询被收集的记录数目 SHOW GLOBAL STATUS LIKE '%Slow_queries%';
2.EXPLAIN 查看执行计划
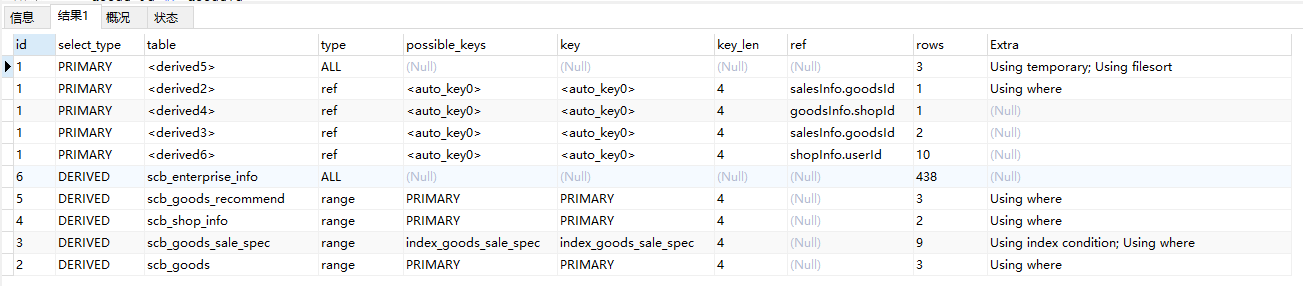
【 id 】
可以获得SQL的执行顺序
数字越大,越早被执行;数字相同,由上往下执行;
【 select_type 】
- SIMPLE 简单的查询
- PRIMARY 最外层的表,通常和UNION、DERIVED混合使用
- UNION 表被union
- DERIVED 派生表,如嵌套查询 SELECT t.* FROM ( SELECT class_name FROM tb_class ) t 中的 tb_class 表
【 table 】
参与的表名称
当值为 <derived4> 时,表示 id 为 4 的派生表
【 type 】
- ALL 全表扫描
- index 按照索引顺序全表扫描
- range 范围扫描
- ref 走了不唯一的索引扫描
- eq_ref 走了唯一性索引
- const where 主键 = 常量
【 possible_keys 】
预测应该被使用到的索引
【 key 】
实际使用到的索引
【 key_len 】
索引key的长度。
主要区分复合索引,当用到了相同的复合索引,有效列列越多,key_len长度越长
【 ref 】
一般标识 where 语句部分,where表等号 后边部分
- 库.表.字段
- 常量
【rows】
查询语句影响的行数
【Extra】
- Using filesort
当排序无法使用索引的时候,MySQL 会选择一定的算法进行排序,数据少时会在内存进行排序,数据多时会在磁盘进行排序
- Using temporary
一般查询语句中包含 order by , group by 会出现
为了解决查询,MySQL需要创建一个临时表来容纳结果。典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时。很明显就是通过where条件一次性检索出来的结果集太大了,内存放不下了,只能通过家里临时表来辅助处理;
3.建索引
全值匹配我最爱,带头大哥不能死,中间兄弟不能断,范围之后全无效
不能使用索引 !=、<>、is null、is not null、like ‘%xx’
少用 or
like 索引失效问题
建带有like列的复合索引
用IN 还是用 exists
大前提,AB两表id建索引
SELECT * FROM A WHERE A.id IN ( SELECT id FROM B )
从少的(B)里面挑多的(A)用in
从多的里面挑少的用exists