给自己看的,所以以举例子为主了
检索数据
SELECT 检索单列 SELECT name FROM student
检索多列 SELECT no, name FROM student
检索所有列 SELECT * FROM student
检索不同行 SELECT DISTINCT name, sex FROM student distinct修饰的select下的所有列,也就是说两条数据,name和sex中只要有一列不同,就算不同行了。
限制结果 SELECT no FROM student LIMIT 5 如果搜出来的行不足限制数,那么全输出
全限定表名 SELECT student.no FROM student
排序数据
ORDER BY 按单列排序 SELECT name FROM student ORDER BY no 未被检索的列(no字段)也是可以以其排序的
按多列排序 SELECT * FROM student ORDER BY birthday, sex 只有结果集中存在birthday相同的数据时,这些数据才会再按照sex排序
排序方向 SELECT * FROM student ORDER BY birthday DESC 从大到小排序,常见的情形是价格最贵的,日期最新的。
过滤数据
WHERE 单条件 SELECT name FROM student WHERE no=10
不匹配 SELECT name FROM student WHERE no!=10
范围 SELECT name FROM student WHERE no BETWEEN 1 AND 3 头尾都包含,即1、2、3
空值 SELECT name FROM student WHERE sex IS NULL
数据过滤
AND 多条件 SELECT name FROM student WHERE name='Deolin' AND sex=1
OR 多条件 SELECT name FROM student WHERE name='Deolin' OR name='Bld' 一般AND和OR共存的情况,直接有小括号保证计算次序,而不是通过记忆去依赖优先级
IN 范围 SELECT name FROM student WHERE name IN ('Deolin', 'Bld') in和or, 优先选用in,因为速度更快,易管理,更直观
NOT 否定单个条件 SELECT name FROM student WHERE NOT name IN ('Deolin1', 'Bld1')
通配符 为了效率,不过度使用;尽量不把通配符放在开始处
LIKE % 通配符匹配 SELECT name FROM student WHERE name LIKE 'D%n' 任何字符任何次数, name是'Dn' 'Deolin'…的数据都在范围内;LIKE '%'匹配不到null
LIKE _ 通配符匹配 SELECT name FROM student WHERE name LIKE 'Deol_n' 任何字符一次,只能1次,不能多也不能少
正则表达式
REGEXP
OR匹配 REGEXP '1000|2000' 匹配1000或2000
字符匹配 REGEXP '[ab12]ton' 匹配aton或bton或1ton或2ton
范围匹配 REGEXP '[0-9]' 相当于[0123456789]
REGEXP '[3-6]' 相当于[3456]
REGEXP '[b-d]' 相当于[bcd]
转义匹配 REGEXP '\%' 匹配字符 %
元字符匹配 REGEXP '\f' 换页 \f换页 \n换行 \r回车 \t制表 \v纵向制表
字符类匹配 REGEXP '[:alnum:]' 相当于[a-zA-Z0-9],而且三者都得有
REGEXP '[:alpha:]' 相当于[a-zA-Z],而且两者都得有
REGEXP '[:digit:]' 相当于[0-9]
多匹配 {n} 指定匹配次数
{n,} 指定匹配次数不小于n
{n,M} 指定匹配次数为n至M
* 0次或多次匹配
+ 相当于{1,}
? 相当于{0,1}
定位匹配 ^ $ 文本开始至文本结束 举例:REGEXP '1000|2000' 会匹配到 h1000或sd2000之类的,但是REGEXP ^'1000|2000'$只会匹配到1000和2000两个
否定匹配 [^ ] ^出现在集合(指中括号)中时,用于否定集合里的表达式
计算字段
CONCAT() 字段拼接 SELECT CONCAT('The name is '+name+'.') FROM student
RTRIM() 去除右边空格 SELECT RTRIM(name) FROM student LTRIM()左边空格,TRIM()两边空格
AS 别名 SELECT (RTRIM(name)+sex) AS name FROM student 结合函数和列与列之间的算数运算使用
函数
文本处理
LEFT() / RIGHT() 文本的左/右边字符
LENGTH() 文本长度
LOWER() / UPPER() 转换为小/大写
日期 日期比较时,尽量用DATE()包裹字段;目标值的链接符号虽然/和-都可以,但尽量和字段一致,使用-
DATE() / TIME() 取出字段的年月日/时分秒
YEAR() / MONTH() / DAY() 取出字段的年/月/日
HOUR() / MINUTE() / SECOND() 取出字段的时/分/秒
NOW() 现在的日期和时间
DAYOFWEEK() 周几
汇总数据
聚集函数 如果是select count(no) as cnt, name from student,那么虽然cnt的值是一致的,但是还是会被复制到每个行中,因为结果集被name字段“撑开”了
AVG() 聚集结果集中某列的平均值,参数是非数字也可行,但是会返回奇怪的结果,avg()忽略null值
COUNT() 用的太多了,“聚集”的作用都可以参考count count()参数是列名时,会忽略列中的null值,null值不计入总数
MAX() 聚集结果集中某列的最大值
MIN() 聚集结果集中某列的最小值 min()会忽略null值
SUM() 聚集结果集中某列的和,参数是非数字也可行,但是会返回奇怪的结果
分组数据
GROUP BY 创建分组
HAVING 过滤分组
子查询
IN (SELECT…) 子查询作为检索条件的值(的集合)
SELECT (SELECT…) 子查询作为检索项目的计算值 注意这里要全限定表名
理解分组
创建分组(GROUP BY)
简单说就是把结果集按列隐式地分组成了很多个结果集,分组是个结果集;
既然分组是个“结果集”,那么select中的聚集函数会对每个分组分别计算,
可以认为,分组的目的就是为了使用聚集函数;
group by可以跟任意数量的列名,代表结合多个列进行分组;
group by后面不能跟聚集函数;
列中的null值是一个特殊值,区别与其他的非null值;

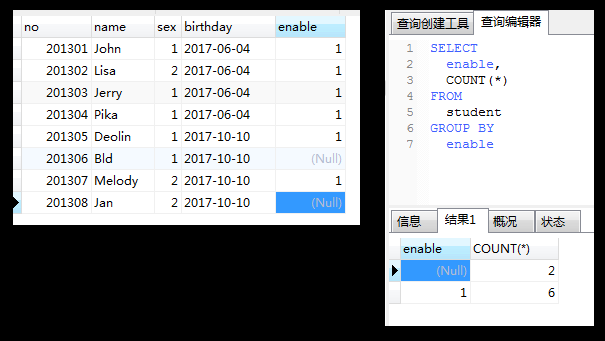
过滤分组(HAVING)
跟where非常相似,where的语法having几乎全适用;
where过滤的是整个结果集中不符合条件的每个数据,
having过滤的是整个结果集中符合条件的每个分组
