实验环境:
10.6.191.181 Elasticsearch 10.6.191.182 Kibana 10.6.191.183 Logstash
一、elasticsearch安装以及优化
1、elasticsearch安装
[root@es-node1 ~]# mkdir /usr/java [root@es-node1 ~]# tar zxvf jdk1.8.0_131.tar.gz -C /usr/java/ [root@es-node1 ~]# cp /etc/profile /etc/profile.back [root@es-node1 ~]# vim /etc/profile export JAVA_HOME=/usr/java/jdk1.8.0_131/ export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOMR/bin [root@es-node1 ~]# source /etc/profile [root@es-node1 ~]# java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode) [Elasticsearch] [root@es-node1 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.3.0.tar.gz [root@es-node1 ~]# tar zxvf elasticsearch-5.3.0.tar.gz -C /usr/src/ [root@es-node1 ~]# mv /usr/src/elasticsearch-5.3.0/ /usr/local/elasticsearch [root@es-node1 ~]# useradd elk [root@es-node1 ~]# chown -R elk:elk /usr/local/elasticsearch/
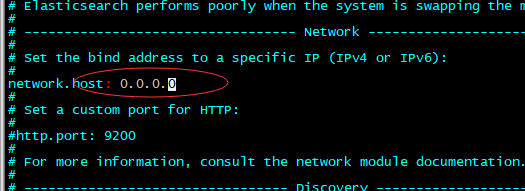
修改/usr/local/elasticsearch/config/elasticsearch.yml,
设置监听地址为network.hosts:0.0.0.0。
2、Elasticsearch优化

为了使得Elasticsearch获得高效稳定的性能,需要对系统和JVM两个方面进行优化
1)vim /etc/sysctl.conf ,新增如下两行:
fs.file-max=655360 #系统最大打开文件描述符数,建议修改为655360或者更高 vm.max_map_count=262144 #直接影响java线程数量,用来限制一个进程可以用于VM(虚拟内存区域大小)默认为65530,建议修改为262144或者更高
sysctl -p 重新加载文件/etc/sysctl.conf
Max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。
调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。
如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用
2)vim /etc/security/limits.conf,增加如下代码:
* soft nproc 20480 * hard nproc 20480 * soft nofile 65536 * hard nofile 65536 * soft memlock unlimited * hard memlock unlimited * soft nofile #任何一个用户可以打开的最大的文件描述符数量,默认1024,这里的数值会限制tcp连接 * soft nproc #任何一个用户可以打开的最大进程数
soft是一个警告值,而hard则是一个真正意义的阀值,超过就会报错
sed -i '5s#4096#20480#g' /etc/security/limits.d/20-nproc.conf
3、JVM调优
JVM调优主要是针对Elasticsearch的JVM内存资源进行优化,elasticsearch的内存资源配置文件为jvm.options。
vim /usr/local/elasticsearch/config/jvm.options
-Xms1g -Xmx1g #根据服务器内存大小,进行修改合适的值,建议修改服务器物理内存的一半最佳
4、启动elasticsearch
[root@es-node1 ~]# su - elasticsearch
[elasticsearch@es-node1 ~]$ /usr/local/elasticsearch/bin/elasticsearch -d
ps:当你的elasticsearch启动的时候,什么错误都没有报,但是就是端口进程没起来·,此时查看日志信息,输出如下,
这是因为目录权限属主属组是root账号,我们只需chown elk:elk -R /usr/local/elasticsearch/即可。
二、Elasticsearch插件(elasticsearch-head)部署
1、ES老版本(5.x以下)部署ES HEAD插件方法如下:
cd /usr/local/elasticsearch;
./bin/plugin install mobz/elasticsearch-head
Elasticsearch-head是elasticsearch的集群管理工具,它是完全由HTML5编写的独立网页程序,你可以通过插件把它安装到ES,然后重启ES,通过界面访问和管理即可。
2、ES新版本(5.x以上)部署ES HEAD插件方法如下:
1)安装nodejs和npm
yum install -y nodejs npm git (ps:如果yum不能正产安装npm和nodejs的话,采用源码吧)
源码安装 wget https://nodejs.org/dist/v9.8.0/node-v9.8.0-linux-x64.tar.xz xz -d node-v9.8.0-linux-x64.tar.xz tar xvf node-v9.8.0-linux-x64.tar
mv node-v9.8.0-linux-x64 /usr/local/node 在/etc/profile添加如下两行代码: export NODE_HOME=/usr/local/node
export PATH=$PATH:$NODE_HOME/bin
source /etc/profile
[root@es-node1 ~]# npm -v
5.6.0
[root@es-node1 ~]# node -v
9.8.0
2)下载源码并安装elasticsearch-head
git clone https://github.com/mobz/elasticsearch-head.git
mv elasticsearch-head/ /usr/local/ cd /usr/local/elasticsearch-head/ #基于国内taobao镜像安装grunt; npm install -g grunt --registry=https://registry.npm.taobao.org npm config set registry http://registry.cnpmjs.org/ #安装Head插件; npm install
PS:执行npm install 时报错:


解决方法:
npm config get proxy npm config get https-proxy npm config set registry http://registry.cnpmjs.org/
#上面三条解决上面的错误
npm install phantomjs-prebuilt@2.1.14 --ignore-scripts
#解决下面的错误
3、启动服务后报如下错误:

同时增加跨域的配置,增加如下两行代码:
http.cors.enabled: true http.cors.allow-origin: "*"
2)编辑/usr/local/elasticsearch-head/_site/app.js,修改head连接es的地址:
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200"; #将localhost修改为ES的IP地址 this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://10.6.191.181:9200";
3)修改/usr/local/elasticsearch-head/Gruntfile.js,找到connect部分,增加hostname: '*',
connect: { server: { options: { hostname: '*', port: 9100, base: '.', keepalive: true } } }
4、启动Elasticsearch-head独立服务:
nohup npm run start &
或者
nohup /usr/local/elasticsearch-head/node_modules/grunt/bin/grunt server &
三、Logstash客户端配置
1、部署JDK
由于Logstash基于JAVA语言开发,Agent部署需要安装JDK运行环境库;
tar -zxf jdk1.8.0_131.tar.gz
mkdir -p /usr/java
mv jdk1.8.0_131 /usr/java/
cat >> /etc/profile << EOF
export JAVA_HOME=/usr/java/jdk1.8.0_131
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOMR/bin
EOF
source /etc/profile
java -version
2、部署Logstash软件
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.3.0.tar.gz tar xzf logstash-5.3.0.tar.gz mv logstash-5.3.0 /usr/local/logstash/ mkdir -p /usr/local/logstash/config/etc/ cd /usr/local/logstash/config/etc/
创建ELK整合配置文件:vim logstash.conf,内容如下:
input {
stdin { }
}
output {
stdout {
codec => rubydebug {}
}
elasticsearch {
hosts => "10.6.191.181" }
}
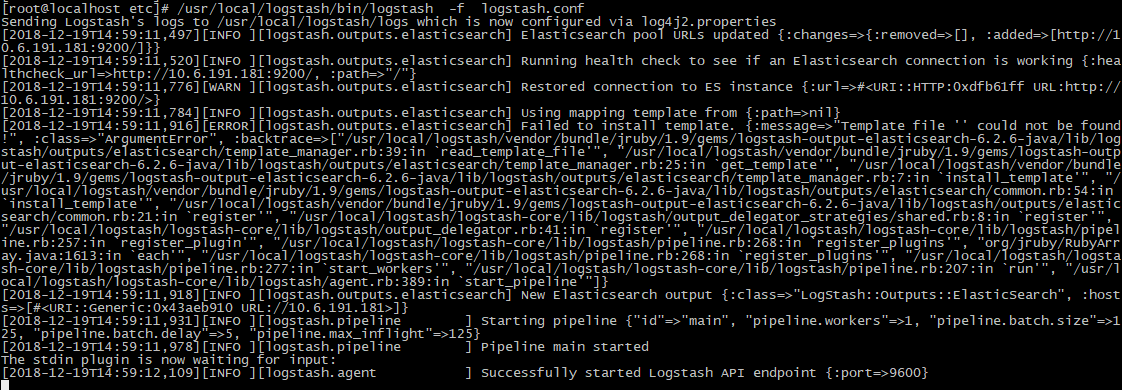
3、启动logstash服务
/usr/local/logstash/bin/logstash -f logstash.conf
四、 Kibana WEB安装配置
1、部署安装Kibana
1)安装不需要安装JAVA JDK环境,直接下载源码,解压即可:
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.3.0-linux-x86_64.tar.gz
tar xzf kibana-5.3.0-linux-x86_64.tar.gz mv kibana-5.3.0-linux-x86_64 /usr/local/kibana/
2)修改kibana配置文件信息,设置ES地址:vim /usr/local/kibana/config/kibana.yml

3)启动kibana。在浏览器输入10.6.191.182:5601
nohup /usr/local/kibana/bin/kibana &

这是会报错,这是由于plugin版本不一致导致,所以elasticsearch和kibana的版本要保持一致。
2、ELK-WEB日志数据图表
Logstash启动窗口中输入任意信息,会自动输出相应格式日志信息:
浏览器输入:10.6.191.181:5601
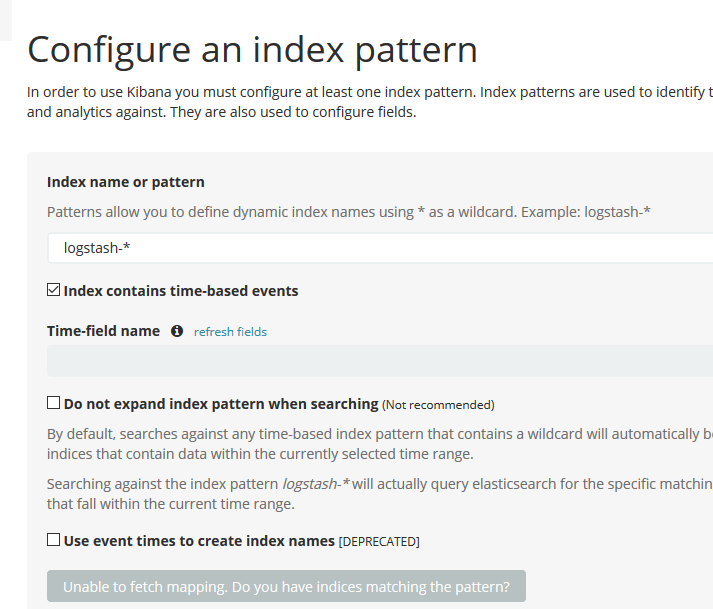
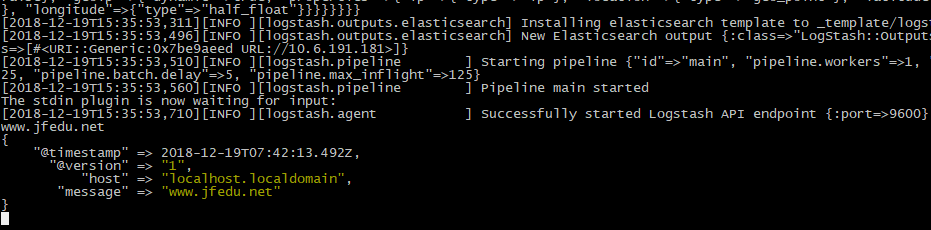
必须先选择一个日志,才能创建索引模式。

为了使用kibana 你必须配置至少一个索引模式,索引模式是用于确认Elasticsearch index,用来运行搜索和分析,也可以用于配置字段。
Index contains time-based events 索引基于时间的事件;
Use event times to create index names [DEPRECATED] 使用事件时间来创建索引名字【过时】
Index name or pattern 索引名字或者模式;
模式允许你定义动态的索引名字 使用*作为通配符,例如默认:
logstash-*
选择:
Time field name;
单击Discover,可以搜索和浏览 Elasticsearch 中的数据,默认搜索的是最近 15分钟的数据。可以自定义选择时间。
3、ELK-WEB中文汉化支持
Kibana WEB平台所有的字段均显示为英文,目前5.x版本默认没有中文汉化插件或者汉化包,感谢Github开源贡献者开发了汉化包,汉化包插件地址:
https://github.com/anbai-inc/Kibana_Hanization
Kibana汉化方法此项目,适用于Kibana 5.x-6.x的任意版本,汉化过程不可逆,汉化前请注意备份! 汉化资源会慢慢更新完善,已汉化过的Kibana可以重复使用此项目汉化更新的资源。
除一小部分资源外,大部分资源无需重启Kibana,刷新页面即可看到效果,Kibana汉化方法和步骤如下:
1)Github仓库下载kibana中文汉化包,下载指令如下:
git clone https://github.com/anbai-inc/Kibana_Hanization.git #wget http://bbs.jfedu.net/download/Kibana_Hanization_2018.tar.gz
2)切换至Kibana_Hanization目录,并且执行汉化过程
cd Kibana_Hanization/
python main.py /usr/local/kibana/(此处为系统kibana安装路径)

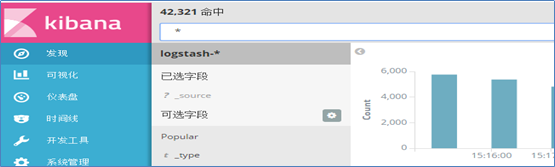
3)重启kibana服务即可,通过浏览器访问如图所示:
五、 Kibana WEB安全认证
当我们安装完ES、Kibana启动进程,可以直接在浏览器访问,这样不利于数据安全,接下来我们利用Apache的密码认证进行安全配置。通过访问Nginx转发只ES和kibana服务器,Kibana服务器安装Nginx
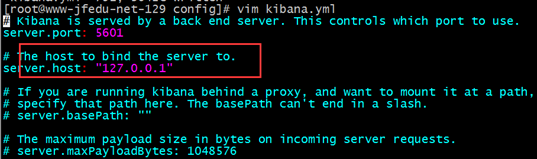
1、配置kibana
修改kibana配置文件监听IP为127.0.0.1
2、安装nginx
yum install pcre-devel pcre -y wget -c http://nginx.org/download/nginx-1.12.0.tar.gz tar -xzf nginx-1.12.0.tar.gz useradd www ;./configure --user=www --group=www --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module make
make install
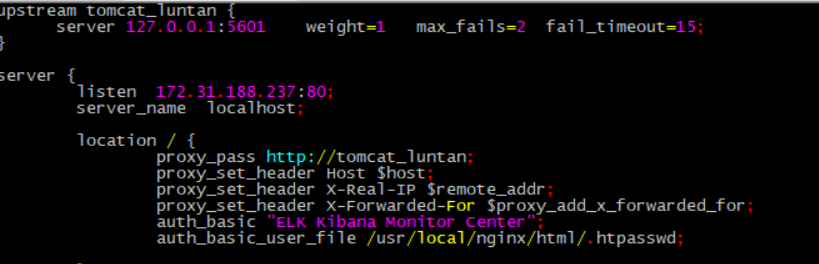
修改Nginx.conf配置文件代码如下,并添加Nginx权限认证:
worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; upstream jvm_web1 { server 127.0.0.1:5601 weight=1 max_fails=2 fail_timeout=30s; } server { listen 80; server_name localhost; location / { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_pass http://jvm_web1;
auth_basic "ELK Kibana Monitor Center";
auth_basic_user_file /usr/local/nginx/html/.htpasswd;
}
}
}
通过Apache加密工具htpasswd生成用户名和密码:
htpasswd -c /usr/local/nginx/html/.htpasswd admin

重启nginx
/usr/local/nginx/sbin/nginx -s reload