Python爬取彼岸桌面
https://blog.csdn.net/Zhangguohao666/article/details/105131503
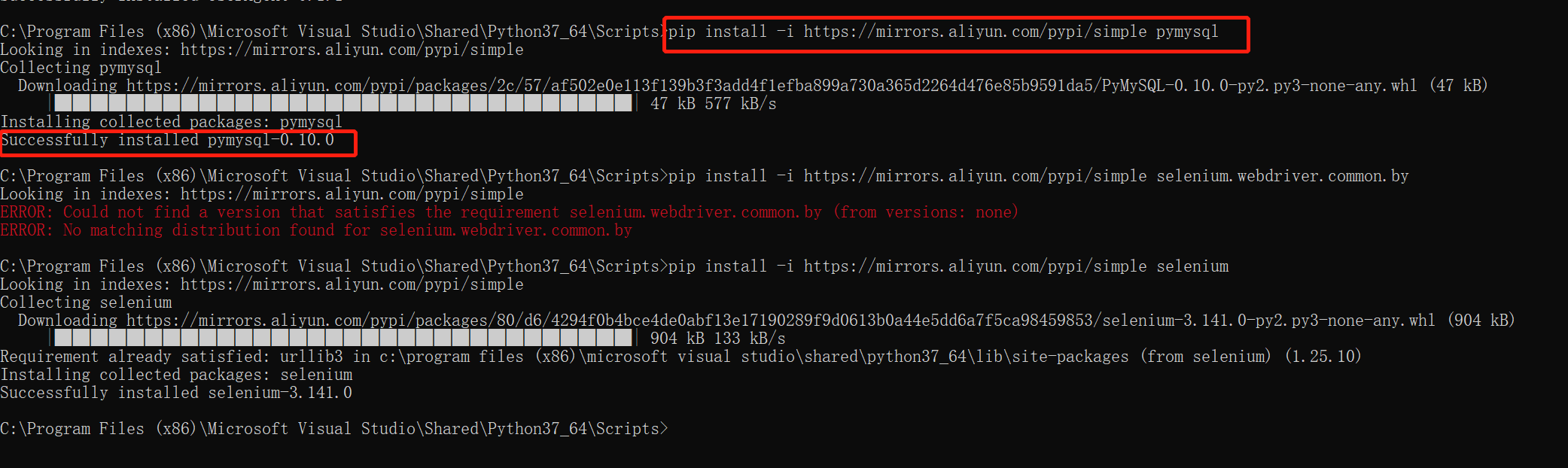
安装pip工具包 cd C:Program Files (x86)Microsoft Visual StudioSharedPython37_64Scripts>下执行
pip install -i https://mirrors.aliyun.com/pypi/simple selenium
1 pip install 是安装命令
2 -i https://mirrors.aliyun.com/pypi/simple 为指定的安装镜像网址
3 【selenium 为需要安装的工具包】


1 import json 2 import os 3 import random 4 import sys 5 from concurrent.futures.thread import ThreadPoolExecutor 6 import pymysql 7 from lxml import etree 8 from requests import * 9 from selenium import webdriver 10 from selenium.webdriver.common.by import By 11 from selenium.webdriver.support.ui import WebDriverWait 12 from selenium.webdriver.support import expected_conditions as EC 13 from selenium.webdriver.chrome.options import Options 14 15 class Spider: 16 def __init__(self, cookieFile=None): 17 if cookieFile is None: 18 self.writeCookie() 19 self.cookies = self.readCookies("cookie.txt") 20 else: 21 self.cookies = self.readCookies(cookieFile) 22 23 self.headers = { 24 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' 25 } 26 self.indexUrl = "http://pic.netbian.com" 27 self.catelogue = self.getCatalogue() 28 # 每天限量只能下载200张 29 self.downCount = 0 30 self.ddir = 'D:\桌面壁纸\' 31 32 def writeCookie(self): 33 #try: 34 chrome_options = Options() 35 chrome_options.add_argument('--headless') 36 chrome = webdriver.Chrome(options=chrome_options) 37 chrome.get("http://pic.netbian.com/e/memberconnect/?apptype=qq") 38 ptlogin_iframe = WebDriverWait(chrome, 15).until(EC.presence_of_element_located((By.ID,"ptlogin_iframe"))) 39 chrome.switch_to.frame(ptlogin_iframe) 40 chrome.find_element_by_id("switcher_plogin").click() 41 # 设置qq号 42 chrome.find_element_by_id("u").send_keys("输入您的QQ号") 43 # 设置qq密码 44 chrome.find_element_by_id("p").send_keys("输入您的密码") 45 # 确定登录 46 chrome.find_element_by_id("login_button").click() 47 WebDriverWait(chrome, 15).until(EC.url_to_be("http://pic.netbian.com/")) 48 with open("cookie.txt", "wt") as f: 49 for cookieMap in chrome.get_cookies(): 50 k = cookieMap["name"] 51 v = cookieMap["value"] 52 f.write(k+"="+v+" ") 53 #finally: 54 # chrome.quit() 55 56 def readCookies(self, cookieFile): 57 cookies = {} 58 with open(cookieFile, "r", encoding="utf-8") as f: 59 while True: 60 c = f.readline() 61 if c is not None: 62 c = c.strip() 63 if len(c) == 0: 64 break 65 else: 66 c = c.split("=") 67 cookies[c[0]] = c[1] 68 else: 69 break 70 return cookies 71 72 def reqGet(self, url): 73 html = get(url, headers=self.headers, cookies=self.cookies).content.decode("gbk") 74 return html 75 76 def getImg(self, url): 77 return get(url, headers=self.headers, cookies=self.cookies) 78 79 def getCatalogue(self): 80 index = self.reqGet(self.indexUrl) 81 h = etree.HTML(index) 82 href = h.xpath('//div[@class="classify clearfix"]/a/@href') 83 title = h.xpath('//div[@class="classify clearfix"]/a/text()') 84 return zip(title, href) 85 86 def getRealUrl(self, href): 87 """ 88 ('阿尔卑斯山风景4k高清壁纸3840x2160', 'http://pic.netbian.com/downpic.php?id=21953&classid=53') 89 """ 90 dh = self.reqGet(self.indexUrl + href) 91 h = etree.HTML(dh) 92 dataId = h.xpath('//div[@class="downpic"]/a/@data-id')[0] 93 title = h.xpath('//div[@class="photo-hd"]/h1/text()')[0] 94 url = "{0}/e/extend/downpic.php?id={1}&t={2}".format(self.indexUrl, dataId, random.random()) 95 msg = self.reqGet(url) 96 return title, self.indexUrl + json.loads(msg)['pic'] 97 98 def getPicUrls(self, url=None, html=None): 99 if html is None: 100 html = self.reqGet(url) 101 h = etree.HTML(html) 102 hrefs = h.xpath('//ul[@class="clearfix"]/li/a/@href') 103 realHrefs = [] 104 for href in hrefs: 105 realHrefs.append(self.getRealUrl(href)) 106 return realHrefs 107 108 def getMaxPage(self, html): 109 h = etree.HTML(html) 110 pages = h.xpath('//div[@class="page"]/a/text()') 111 return int(pages[-2].strip()) 112 113 def saveToDB(self, category, v, i): 114 url = "%s%sindex_%d.html" % (self.indexUrl, v, i) 115 if i == 1: 116 url = "%s%sindex.html" % (self.indexUrl, v) 117 nus = self.getPicUrls(url=url) 118 for nu in nus: 119 self.add(category, nu[0], nu[1]) 120 121 def savePicInfoToDB(self): 122 executor = ThreadPoolExecutor(max_workers=64) 123 for c, v in self.catelogue: 124 html = self.reqGet(self.indexUrl + v) 125 if not os.path.exists("%s%s" % (self.ddir, c)): 126 os.mkdir("%s%s" % (self.ddir, c)) 127 print("%s%s" % (self.ddir, c)) 128 maxPage = self.getMaxPage(html) 129 for i in range(1, maxPage + 1): 130 executor.submit(self.saveToDB, c, v, i) 131 executor.shutdown(wait=True) 132 133 def getConn(self): 134 conn = pymysql.Connect( 135 host="127.0.0.1", 136 port=3306, 137 charset='utf8', 138 user='root', 139 password='toor', 140 db='photos' 141 ) 142 return conn 143 144 def add(self, category, filename, url): 145 try: 146 conn = self.getConn() 147 cursor = conn.cursor() 148 sql = "INSERT INTO purl VALUES ('{0}', '{1}', '{2}')".format(category, filename, url) 149 cursor.execute(sql) 150 conn.commit() 151 print(filename + " was added to database successfully") 152 except: 153 sys.stderr.write(filename + " was existed! ") 154 finally: 155 cursor.close() 156 conn.close() 157 158 def downPic(self): 159 executor = ThreadPoolExecutor(max_workers=32) 160 sql = "select * from purl" 161 conn = self.getConn() 162 cursor = conn.cursor() 163 cursor.execute(sql) 164 result = cursor.fetchall() 165 for index in range(0, len(result)): 166 if self.downCount > 200: 167 print("finished today, welcome come back tomorrow!") 168 break 169 executor.submit(self.download, result[index]) 170 executor.shutdown(wait=True) 171 cursor.close() 172 conn.close() 173 174 def download(self, cnu): 175 path = "{0}{1}{2}.jpg".format(self.ddir, cnu[0], cnu[1]) 176 if os.path.exists(path) and os.path.getsize(path) > 10000: 177 return 178 print("download... " + path) 179 rimg = self.getImg(cnu[2]) 180 if (rimg.status_code != 200 or len(rimg.content) <= 1024): 181 print("invalid img!") 182 return 183 with open(path, "wb") as f: 184 f.write(rimg.content) 185 self.downCount += 1 186 print(str(self.downCount) + ": finished!!! " + path) 187 188 def start(self, hasUrlData=None): 189 if hasUrlData is None: 190 self.savePicInfoToDB() 191 self.downPic() 192 193 194 if __name__ == '__main__': 195 spider = Spider() # 如果没有cookie 196 # spider = Spider(cookieFile="D:") # 如果有cookie 197 spider.start(hasUrlData=True) # 已有数据库文件,直接下载,没有数据库文件则不填
1 import re 2 import requests 3 import os 4 import time 5 ''' 爬取的彼岸桌面的壁纸''' 6 # 总页模板 7 urls = 'http://www.netbian.com/meishi/index_{}.htm' 8 9 # 找出user-agent代理 模拟登入 10 headers = { 11 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' 12 } 13 14 # 创建保存图片的文件夹 15 if not os.path.exists("D:桌面壁纸"): 16 os.mkdir("D:桌面壁纸") 17 18 # 爬取前5页 19 for i in range(1,6): 20 # 加入time.sleep 推迟线程 防止爬取频率过快 ,后台异常 21 time.sleep(1) 22 # 第一页的特殊,单独标记起来 23 if i == 1: 24 main_url= 'http://www.netbian.com/meishi/index.htm' 25 #除第一页的 26 else : 27 main_url= urls.format(i) 28 print('--------------------------') 29 # get请求,获取每一页面的url 30 response = requests.get(main_url, headers=headers) 31 # 获取每一页网页代码文本信息 32 html = response.text 33 # 正则匹配 ,(.*?) 用于分组只显示src,不显示alt,防止乱码, .*? 全匹配 ,都是非贪婪匹配 34 img_urls = re.findall(r'<img src="(.*?)" alt=".*?">', html) 35 for url in img_urls: 36 # 图片名字,对url进行截取,负索引; 37 img_name = url.split('/')[-1] 38 # get请求,获取页面中图片的url 39 response = requests.get(url,headers=headers) 40 with open("D:桌面壁纸{}".format(img_name),"wb") as file: 41 # 保存图片 42 file.write(response.content)