0、写在前面的话
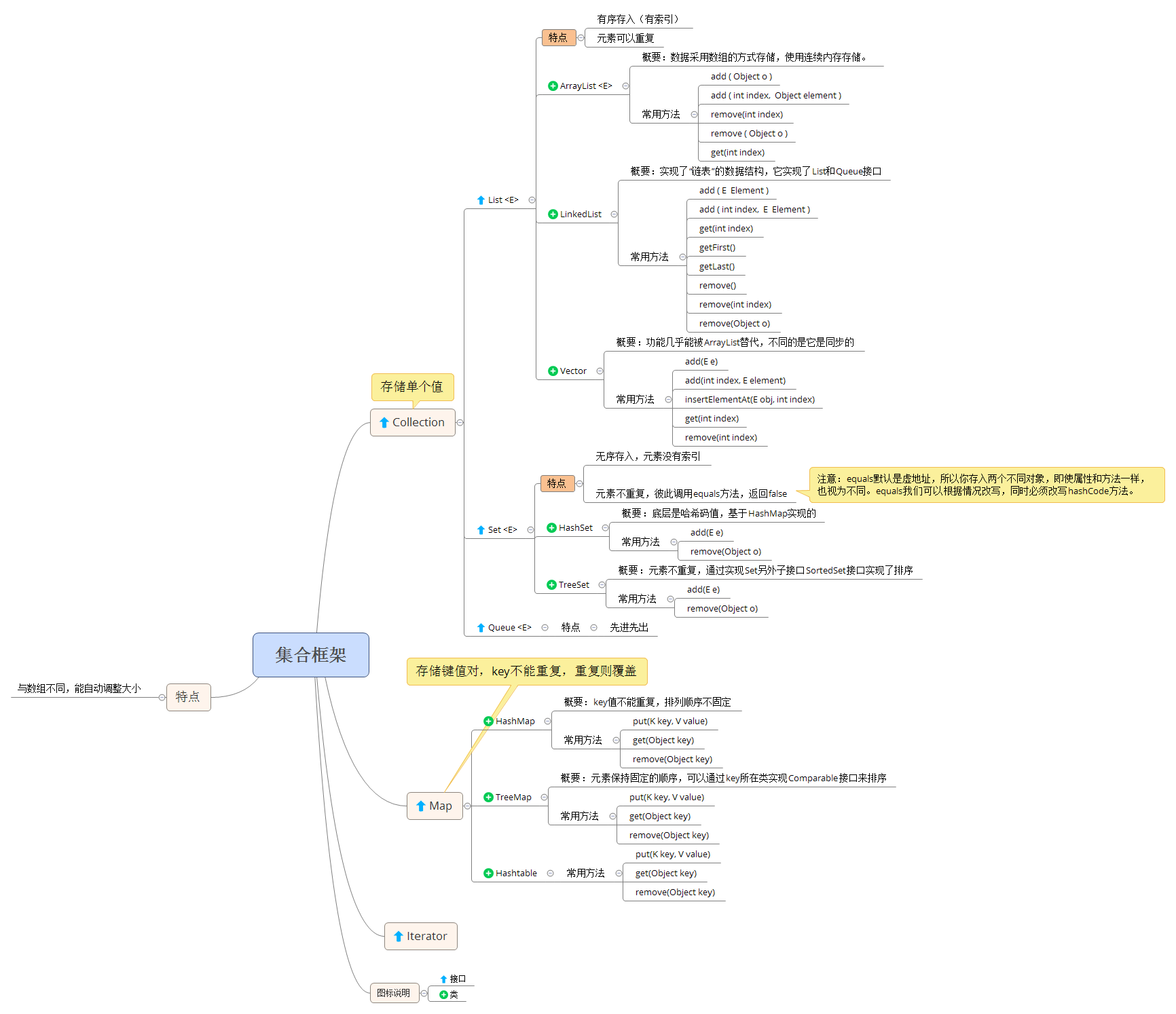
集合是Java的API中非常重要的概念,用来存储多个数据,并实现了不同的数据结构。
Java集合框架中常见的有三大接口:
- Collection
- Map
- Iterator
1、Collection
Collection接口是最基本的集合接口,和Map最主要的不同在于,它每次存储的是单个元素,而Map则存储的是键值对。
其下两大常用接口List和Set,还有个用得比较少的Queue:
- List 有序的集合,元素有序存入
- Set 无重复的集合,即存入的元素不重复
- Queue 队列,JDK1.5新增,实现了先进先出的存储结构
1.1 List
List接口是泛型接口,并继承自Collection接口,并扩展出属于自己的方法。元素都是与索引有关系,因此扩展的方法也基本与索引有关:
- add(int index, E)
- ...
1.1.1 ArrayList
ArrayList称之为数据列表,其底层采用的是数据方式的存储,它允许任何规则的元素存储,甚至包括null。
其默认初始容量为10(底层为数组),每次新增元素时,都要进行容量检查,如若超过容量则自动扩容为原来的1.5倍。
public boolean add(E e) {
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3) / 2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}x
1
public boolean add(E e) { 2
ensureCapacity(size + 1); // Increments modCount!!3
elementData[size++] = e;4
return true;5
}6
7
public void ensureCapacity(int minCapacity) {8
modCount++;9
int oldCapacity = elementData.length;10
if (minCapacity > oldCapacity) {11
Object oldData[] = elementData;12
int newCapacity = (oldCapacity * 3) / 2 + 1;13
if (newCapacity < minCapacity)14
newCapacity = minCapacity;15
// minCapacity is usually close to size, so this is a win:16
elementData = Arrays.copyOf(elementData, newCapacity);17
}18
}1.1.2 LinkedList
和ArrayList不同的在于,LinkedList底层不再是动态数组,而是实现了“链表”的数据结构,每个节点上存放数据信息,也因此拓展了一些方法:
- addFirst(E element)
- addLast(E element)
- ...
同时也因链表的数据接口,其访问不再具有随机性,查找元素无法像ArrayList通过索引来到达,而必须遍历访问。
链表的特点可以轻松地进行插入和删除操作,因为只需要移动指针,相反ArrayList比较麻烦,需要移动数据;但是在查找元素上LinkedList不如ArrayList。
1.1.3 Vector
Vector和ArrayList基本相似,不同的在于Vector是同步的,即它是线程安全的动态数组,而ArrayList是线程异步的,是不安全的。
1.2 Set
Set接口继承自Collection接口,其特点是内部元素不重复,且是无序的,即Set中的元素是没有索引的。
Set中对于元素是否重复的判定是通过equals方法来进行比较的,所以往往我们在使用Set时要考虑重写equals方法,另外要注意的是,一旦重写equals方法,一定要同时重写hashCode方法。
1.2.1 HashSet
HashSet查询速度快,其底层是哈希码值hashCode,也因此它不保证Set迭代的顺序。
1.2.2 TreeSet
HashSet不保证元素的顺序,但是TreeSet是可以实现内部元素排序的,但是要求内部元素必须实现Comparable接口,以规定排序的规则。
2、Map
Map和Collection接口不同的在于,其存储的内容是以键值对的形式存在的。所谓键值对,即 key:value 形式,键即你存值的编号,值即存放的数据,显然,如此的存储方式要求key值唯一,不得重复,一旦重复,那么数据会进行覆盖。
常用方法:
- put(K key, V value)
- get(Object key)
- ...
Map类型的遍历,往往通过keySet()方法,返回其key值的集合,再通过key值获取对应的数据。
2.1 HashMap
较常用的Map集合类,key值通过hashCode和equals保证元素的唯一性,但数据是无序的。
2.2 TreeMap
在保证key值不重复的情况下,还可以对value数据进行排序。TreeMap的排序是根据key值来进行的,key值必须实现Comparable接口,即compareTo方法。
2.3 Hashtable
HashMap和Hashtable都实现了Map接口,用法也几乎相同,不同在于:
- Hashtable自JDK1.0开始,线程安全,效率低,不允许null作为键或值
- HashMap线程不安全,效率高,非同步,null既可以作为键,也可以作为值
2.4 Properties
Properties类是Hashtable类的子类,所以也间接地实现了Map接口。在实际应用中,常使用Properties类对属性文件进行处理:
- load(InputStream in)
- getProperty(String key)
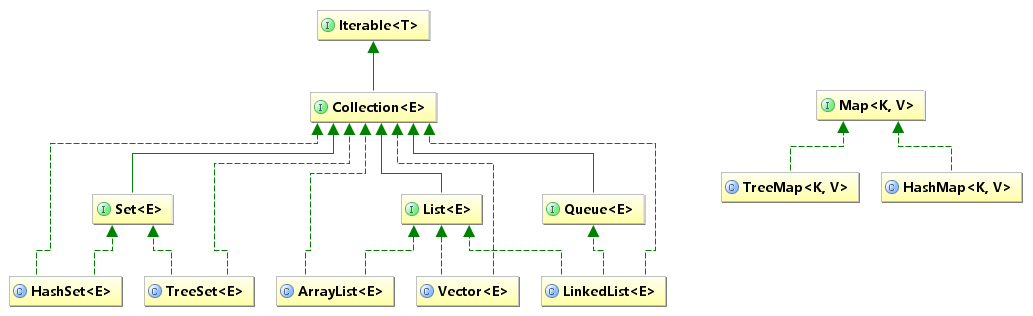
3、一张图