主要思路
使用协同过滤的思路,从当前指定的用户过去的行为和其他用户的过去行为的相似度进行相似度评分,然后使用这个相似度的评分,来构建其他用户过去的行为列表,去除当前指定用户与其他用户重复的内容,形成一份推荐列表,将其中的内容推荐给当前指定用户。
准备工作
- numpy库的安装,安装过程可以自行问度娘。一个比较简单的安装就是直接通过pip安装。
pip install numpy
或者下载numpy的whl离线包,在该文件的路径中使用pip命令安装
pip install numpy文件名.whl
- 数据集的下载,这个实例使用到了movielens的公开的数据集,可以在点这里下载,里面有100k,1m,10m,20m多个版本,这里的100k不是指文件大小100k,是指有100k(100000)条数据的意思。我这里使用了100k的那个数据集作为我的演示数据集
解压后的数据有这么多
下载后的数据是长这个样子的
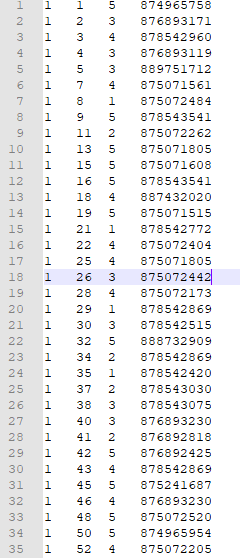
这个数据文件的第一列是用户名,因为这是一份公开数据,用户名被使用了数字代替,第二列是电影名称,因为还有另外一份表是显示完整的电影名称,这个只是显示了电影的ID,需要自己做数据整理形成比较完整的显示内容。
- 数据整理,上面图片中的这份数据,只需要用到前3列的数据,所以需要对数据集进行整理,这里我用最懒的方式
# 数据预处理
filename = 'u1.base'
dataset = []
with open(filename, 'r') as f:
datas = f.readlines()
for data in datas:
dataline = data.split(' ')[:-1]
dataset.append(dataline)
# 将数据组合成一个数据字典,大致的格式为{用户名:{电影名:评分,电影名:评分},用户名:{电影名:评分,电影名:评分}}
# 方便后面处理数据,取值、计算
data_dict = {}
for name, movie, rating in dataset:
if name not in data_dict:
data_dict[name] = {}
data_dict[name][movie] = int(rating) # 读过来的数据,这里是字符串,需要转成int,因为后面要计算值
将数据集读取后放到一个dict里面,但是建议可以做持久化,不用这样每次执行脚本都需要做一次数据整理。
项目结构图
整体的项目结构其实很简单,这也是Python的魅力——代码量少。就长下图的样子,一个脚本文件,两个数据文件,但是实际上只用了一个数据文件。

实现过程的部分代码展示
- 通过皮尔逊相关系数计算出两个用户之间的相似度
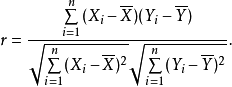
在python中实现,利用numpy库做运算计算
部分代码如下:
- 指定用户的相同评分电影值的和
user_a_sum = np.sum([dataset[user_a][item] for item in rated_by_both])
user_b_sum = np.sum([dataset[user_b] [item] for item in rated_by_both])
- 相同评分电影值的平方和
user_a_square_sum = np.sum([np.square(dataset[user_a][item]) for item in rated_by_both])
user_b_square_sum = np.sum([np.square(dataset[user_b][item]) for item in rated_by_both])
- 数据集的乘积的和
product_sum = np.sum([dataset[user_a][item] * dataset[user_b][item] for item in rated_by_both])
- 计算相似度
sxy = product_sum - (user_a_sum * user_b_sum / num_ratings)
sxx = user_a_square_sum - np.square(user_a_sum) / num_ratings
syy = user_b_square_sum - np.square(user_b_sum) / num_ratings
sxy / np.sqrt(sxx * syy)
需要注意,分母如果为零需要做一个抛异常处理。
- 遍历用户,查找相似度高的用户,形成推荐列表
similarity_score = pearson_score(dataset, user, u)
if similarity_score <= 0.9:
# 用户量大,有近千用户,如果取相似度大于0的,可能将全部的电影内容都推荐出来。这样的推荐就没有意义。
# 如果用户的相似度低于0.9的推荐不要,要找相似度高的用户的共同数据推荐才有意义
continue
for item in [x for x in dataset[u] if x not in dataset[user] or dataset[user][x] == 0]:
total_scores.update({item: dataset[u][item] * similarity_score})
similarity_sums.update({item: similarity_score})
需要考虑一个例外情况,就是如果数据集中的电影,当前指定的用户都评论过的话,这时的推荐列表长度是0
if len(total_scores) == 0
此时应该有一个例外的处理,避免最后输出的结果为空
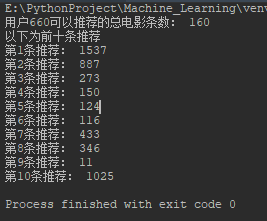
运行效果截图
user = '660'
movies = generate_recommendations(data_dict, user)
print('用户'+user+'可以推荐的总电影条数:', len(movies))
print('以下为前十条推荐')
for i, movie in enumerate(movies[:10]): # [:10]只取排名前十的推荐
print('第'+str(i + 1)+'条推荐:', movie)
最终的运行效果,因为我没有添加电影的名称到数据集中,所以推荐的内容也是显示ID。
其他补充
这只是一个简单的演示,实际上在很多真实应用的运用场景中,需要计算相似度的内容比这个演示中涉及的条件更多、更复杂。下载下来的数据集中还有对于电影的分类、用户的分类,可以在这个系统的基础上深入研究,分析用户评价过的电影,对这些电影的分类进行评分,形成用户喜欢的电影类型的列表,在根据这个列表约束推荐列表,剔除指定用户不喜欢的类型电影等等。
简易推荐引擎的python实现
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权