背景
[作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor]
欢迎大家关注我的公众号,“互联网西门二少”,我将继续输出我的技术干货~

本篇是TensorFlow通信机制系列的第二篇文章,主要梳理使用gRPC网络传输部分模块的结构和源码。如果读者对TensorFlow中Rendezvous部分的基本结构和原理还不是非常了解,那么建议先从这篇文章开始阅读。TensorFlow在最初被开源时还只是个单机的异构训练框架,在迭代到0.8版本开始正式支持多机分布式训练。与其他分布式训练框架不同,Google选用了开源项目gRPC作为TensorFlow的跨机通信协议作为支持。gRPC的编程和使用其实是相对复杂的,TensorFlow为了能让gRPC的调用更加平滑,在调用链封装和抽象上面做了较多工作,甚至有些工作例如创建和管理gRPC channel涉及到了GrpcSession模块。从个人角度来看,利用gRPC进行Tensor通信的过程已经足够丰富,所以我们只针对gRPC传输Tensor过程进行梳理,至于涉及到gRPC管理方面的内容会在另一篇介绍分布式Session创建和管理的文章中集中梳理。
跨进程通信过程
根据之前写博客的经验,直接介绍类图结构和源码部分可能会让人懵圈,还是先从逻辑上把通信过程梳理清楚更能做到深入浅出。其实对于不是非常了解分布式系统或大规模并发系统的读者而言,TensorFlow中通信过程是有些“别扭”的。那么有的读者可能会觉得诧异,跨进程通信过程不就是一方做Send,另一方做Recv吗?这是一个理所当然的过程,为什么会“别扭”呢?是的,整个过程依然是一方做Send,另一方做Recv。而它的“别扭”之处就在于——真正的通信过程由Recv方触发,而不是Send方!这就是理解TensorFlow中使用gRPC传输Tensor过程的最关键点。
前一篇文章分析过在本地传输的场景下Tensor通信的大体过程,从机制和逻辑上来说,跨进程传输过程和本地传输没有很大的差异:TensorFlow使用Rendezvous通信Tensor,借助一个类似Table的数据结构作为传输的中转,并且Send方和Recv方依靠ParsedKey这一唯一传输标识符,跨进程通信也是如此。如果读者对这部分内容不了解,可以参考这篇文章。
Send方——将Ready的Tensor挂入本地Table
和本地传输场景下的Send过程相同,本地Tensor处于Ready状态后就被放挂了本地Worker的Table中,至此Send过程就全部完成了。所以Send过程完全没有涉及到任何跨网络传输的内容,并且Send过程是非阻塞的。
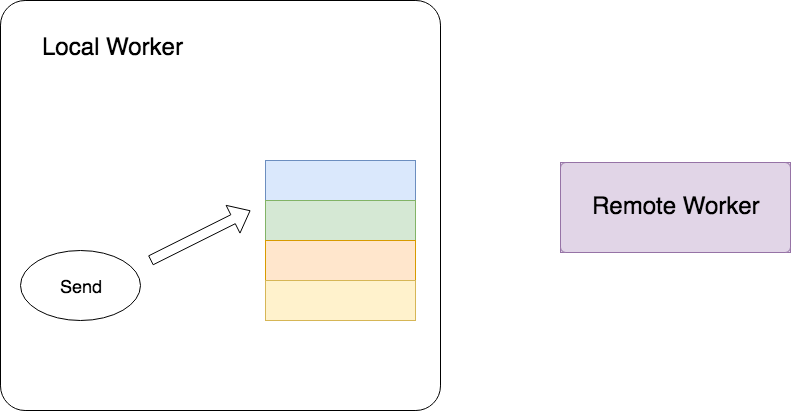
Recv方——向Send方主动发出请求,触发通信过程
Recv方是Tensor的接收方,它的处理过程是:将所需要的Tensor对应的ParsedKey拼出后,主动向Send方主动发出Request,Send方在接收到Request后立即在本地Table中查找方所需要的Tensor,找到后将Tensor封装成Response发送回Recv方。在这个过程中,Recv方可以认为是Client,Send方可以认为是Server,通过发送Request和Response来完成Tensor的传输。
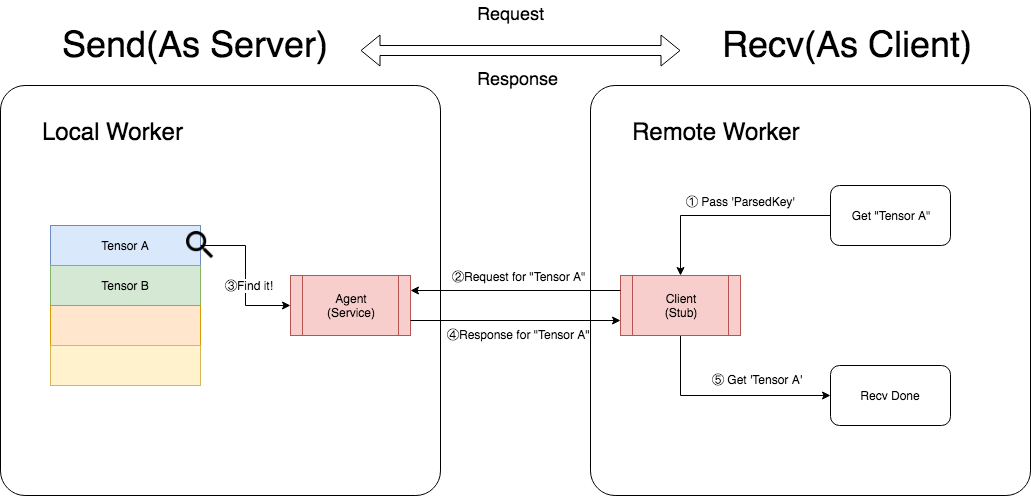
结构设计解析
建议读者在阅读本节时适当翻开TensorFlow C++部分源码,但只需要理解结构关系即可(比如类之间的继承、组合、依赖关系),暂时不要阅读类的实现内容。因为RemoteRendezvous部分涉及到的类结构非常多,直接陷入细节的阅读会深陷其中不能自拔,甚至弄得一头雾水十分疲惫。在梳理结构时一边参照下文中的类图结构,一边从设计模式和架构的角度尝试去理解每个模块的司职是理解本篇细节的关键。先理解宏观结构看懂架子,再去深入理解实现细节尝试去优化是读任何代码的正确顺序。
任何场景下,通信过程几乎都是可以通过简单的图将功能描述清楚的。但是不可否认的是,任何涉及到分布式通信的系统在架构上都会对通信层做相对复杂的封装。一方面是因为通信虽然功能简单,但其实现本身具有相对较高的复杂性(大家可以尝试阅读gRPC源码感受下底层软件的复杂度)。另一方面,应用层也需要与通信底层通过抽象尽量实现较好的解耦,这样也方便将应用层模块被其他团队扩展编写。下面我们一起来探究TensorFlow中涉及到跨进程通信的Rendezvous系列。
两层抽象继承关系——RemoteRendezvous与BaseRemoteRendezvous
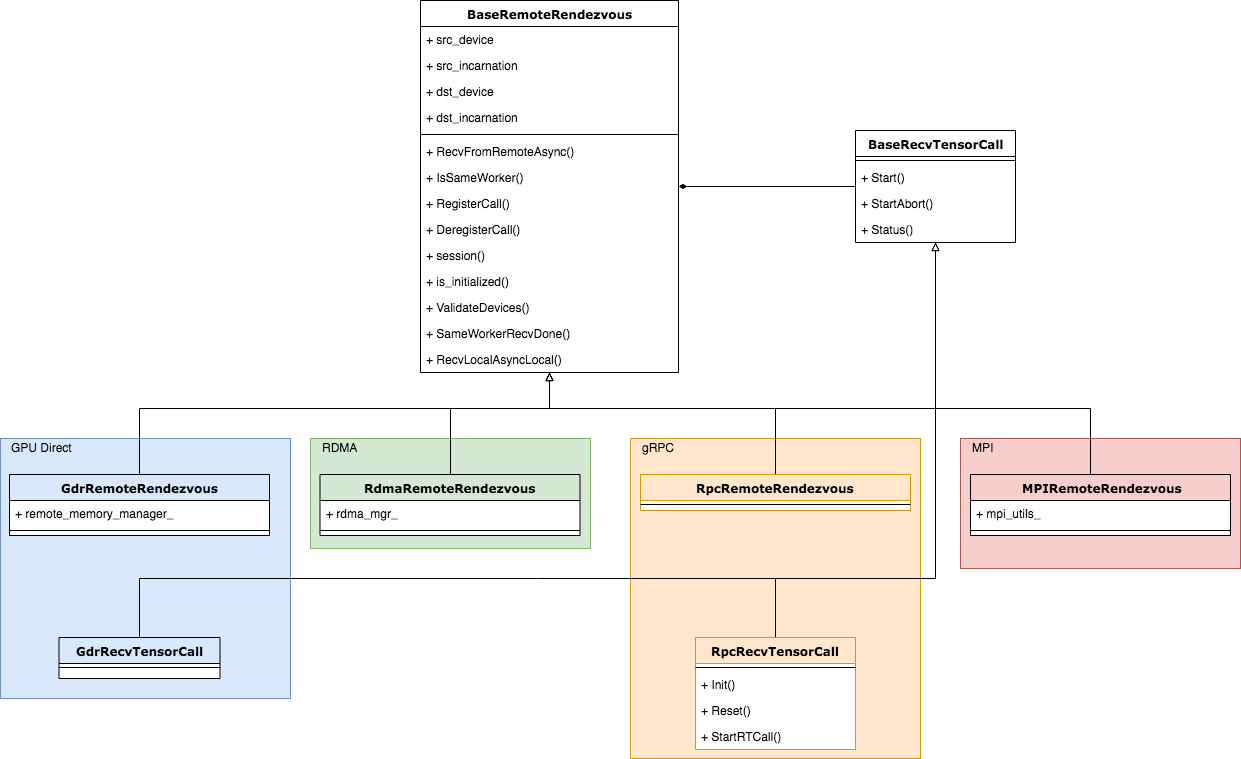
前一篇在介绍本地传输时我们熟悉了Rendezvous模块中与本地传输相关的类,例如LocalRendezvousImpl,IntraProcessRendezvous和SimpleRendezvous。对应地,跨进程传输也有不同的Rendezvous,从根源上来说,它们也继承于Rendezvous接口,并且不同的传输协议也有各自的Rendezvous。在这里,我们再次将前文中展示的总体类结构图展示出来,这次我们将涉及到远程传输的类用特殊颜色标出,如下图所示。

综合来看,从Rendezvous的继承结构来看,涉及到跨进程传输的Rendezvous有层:
1. RemoteRendezvous:只增加了一个Initialize方法,并标记为纯虚函数。这是因为跨进程Rendezvous需要借助Session做一些初始化工作,所以TensorFlow中所有涉及到跨进程通信的Rendezvous都需要重写Initialize函数,使用前也必须强制调用该函数。
2. 各种具体协议Rendezvous的基类——BaseRemoteRendezvous:既然所有涉及跨进程通信的Rendezvous都需要提供各自协议下实现的Initialize函数,那么没有比在RemoteRendezvous和真正特化的Rendezvous之间再添加一层继承关系更合适的做法了。事实上TensorFlow在此处也是这么设计的,这个承上启下的类就是BaseRemoteRendezvous。它还提供了公共的Send和Recv方法,这可以让继承它的特化Rendezvous尽最大可能做到代码复用。
BaseRecvTensorCall是通信的实体抽象,后面分析时会有更深的体会,在这里先有个印象即可。
开始特化——各种各样的RemoteRendezvous
TensorFlow目标是通用可扩展,所以被设计成允许底层支持多种通信协议的结构。事实上到目前为止,算上contrib目录的内容(contrib目录是广大TensorFlow贡献者添加的内容),TensorFlow已经支持包括gRPC,RDMA(Remote Direct Memroy Access),GDR(GPU Dirrect)和MPI四种通信协议,因此包含了四种对应的Rendezvous,他们分别是RpcRemoteRendezvous,RDMARemoteRendezvous,GdrRemoteRendezvous和MPIRemoteRendezvous。每种通信协议各有其特点,有时候其可用性也取决于硬件和软件条件(比如RDMA需要支持RDMA协议的网卡,通常跑在Infiniband和RoCE网络上,如果没有硬件支持,那么RDMA将无法使用,GDR也是这个道理)。从代码中可以看出,实现每种具体的RemoteRendezvous都有一定的复杂性,所以很难想象在没有封装抽象和代码复用的结构里如何实现这些内容。在本篇我们关注RpcRemoteRendezvous,它是gRPC协议实现的RemoteRendezvous。
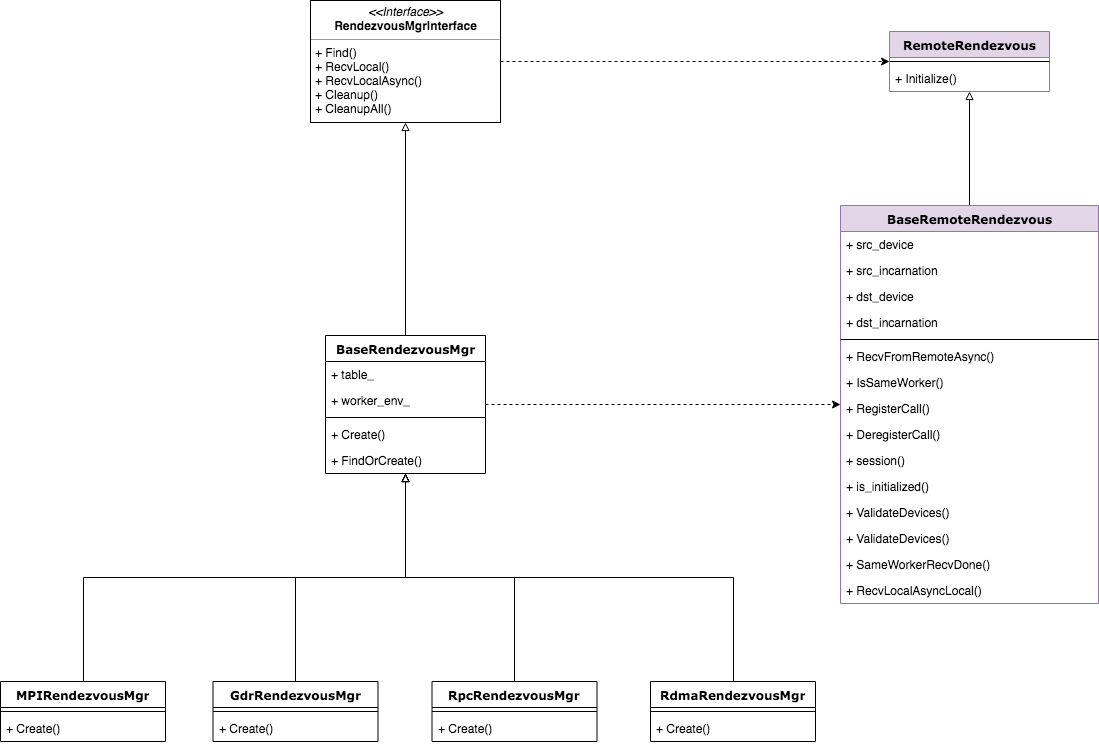
令人熟悉的管理器模式——RendezvousMgr
为了更好地管理RemoteRendezvous,TensorFlow设计了相应的管理器——RendezvousMgr相关类,并为每种具体的RemoteRendevzous做了特化。熟悉设计模式的读者都知道,管理器是一种经典的设计模式,它能使管理职责的变化独立于类本身。RendezvousMgr主要负责RemoteRendezvous的创建和销毁,它也定义了两个本地版本的Recv接口。有的读者可能会问,管理器为什么还允许做Recv?并且只能做本地的Recv?我个人判断添加这两个接口纯粹是为了方便某些地方的使用。至于RendezvousMgr的创建时机和RemoteRendezvous的初始化过程并不是本篇解析的范畴,因为这涉及到分布式场景下创建Server的较长链路,这部分内容会在以后的博客中详细解析。下面是RendezvousMgr相关的类图结构,我们可以看到其接口类中已经定义了Recv接口。
RpcRemoteRendezvous通信过程与源码解析
上一小节中对RemoteRendezvous相关类结构和类间的关系做了解析,旨在从架构层面帮助读者理解各个类的职能。虽然涉及到的内容比较多,但是整体的结构和逻辑还是非常清晰的。如果读者尝试通过阅读源码辅助理解上述内容之后仍然感觉有些眼花缭乱,没有关系,我们在这里暂时做一个简单地梳理,将重点内容梳理到以下几条。
1. 本地Rendezvous和RemoteRendezvous共同继承了同一个接口;
2. RemoteRendezvous需要支持不同的通信协议,因此派生了各种各样的实现类;
3. RemoteRendezvous的使用较为复杂,为此引入了管理器模式——RendezvousMgr,它负责RemoteRendezvous的创建和销毁,并添加了两个额外的Recv接口方便某些场景直接调用;
4. RemoteRendezvous做了两层继承结构只是为了添加一个Initialize方法。
本篇我们梳理使用gRPC协议的部分,从上文中梳理的结构中不难看出,这部分涉及到的类并不多。
1. Rendezvous相关类——RemoteRendezvous,BaseRemoteRendezvous,RpcRemoteRendezvous;
2. 管理器——BaseRendezvousMgr,RpcRendezvousMgr
3. 其他类——BaseRecvTensorCall,RpcRecvTensorCall和DefferedCall
毕竟是涉及到了gRPC协议本身的使用,所以有必要在梳理源码之前从宏观上对gRPC的工作流程做一个简单地梳理。
gRPC编程中的代理模式——Stub与Service
在此我们假设同学们对gRPC的原理和使用有一些基本的了解,比如需要使用Protobuf预先定义Service接口,并且区分Stub和Service等。对此不了解的同学还是建议先认真阅读一下gRPC的使用文档和范例,下面这段文字只对gRPC做一个非常简单的描述。
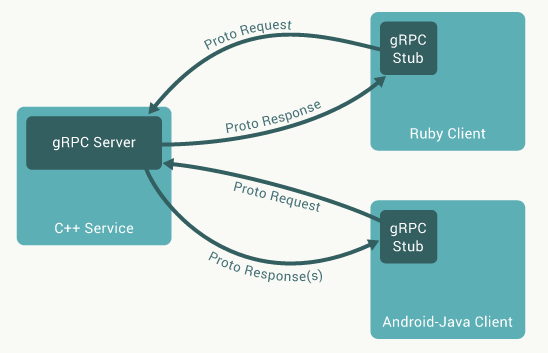
在一次RPC调用中,客户端需要调用服务端的服务,然后将处理结果返回给客户端。而gRPC做到了“让客户端调用远端函数时就像调用本地函数一样”的体验,这得益于一种经典的设计模式——代理模式。负责为客户端代理的节点(gRPC中称之为Stub)会将请求和参数传到服务端,并由Service进行实际的处理,然后将结果返回给Stub,最终返回到客户端中。我们甚至可以认为负责代理的Stub就是客户端,因为它的职责就是与远端交互并取得结果。另外,为了能够让传输量尽可能少,也为了能够让传输不受客户端和服务端具体的类型限制,gRPC在做跨网络传输前将消息统一序列化成Protobuf格式。下图是从gRPC官网教程中摘出的工作原理图。
Send过程
因为Send过程并不涉及跨进程传输,只是将Ready的Tensor挂入本地Table之中,所以它和LocalRendezvousImpl的Send完全相同。不仅如此,TensorFlow中的任何RemoteRendezvous的Send过程都要遵循这样的原理,基于代码复用的考虑,将这部分内容都被抽象到了公共基类BaseRemoteRendezvous的Send函数里是一个很好的设计。事实上,BaseRemoteRendezvous的Send过程就是调用了LocalRendezvousImpl的Send过程,所以LocalRendezvousImpl必须要作为BaseRemoteRendezvous的成员之一。下面的代码展示了这一过程。
1 Status BaseRemoteRendezvous::Send(const Rendezvous::ParsedKey& parsed, 2 const Rendezvous::Args& args, 3 const Tensor& val, const bool is_dead) { 4 VLOG(1) << "BaseRemoteRendezvous Send " << this << " " << parsed.FullKey(); 5 { 6 mutex_lock l(mu_); 7 if (!status_.ok()) return status_; 8 DCHECK(is_initialized_locked()); 9 if (!IsLocalDevice(session_->worker_name, parsed.src_device)) { 10 return errors::InvalidArgument( 11 "Invalid rendezvous key (src): ", parsed.FullKey(), " @ ", 12 session_->worker_name); 13 } 14 } 15 // Buffers "val" and "device_context" in local_. 16 return local_->Send(parsed, args, val, is_dead); 17 }
Recv过程
Recv过程就非常复杂了,因为每种RemoteRendezvous都涉及到不同的通信协议以及管理方式,所以Recv函数是真正需要继承重写的模块。在看RpcRemoteRendezvous具体的实现之前,我们必须先将gRPC定义服务的接口部分梳理清楚。
gRPC的服务定义接口文件
在TensorFlow的core/protobuf文件中,我们需要研究一下worker_service.proto文件,这个文件中定义了若干RPC Service接口。

虽然它定义了很多RPC服务接口,但是我们只需要关注和Tensor接收相关的接口定义即可。准确地说,目前我们必须要知道的是下面这个Service定义。
// See worker.proto for details.
rpc RecvTensor(RecvTensorRequest) returns (RecvTensorResponse) {
// RecvTensor Method
}
显然,这是一个让服务端处理“接收Tensor”的服务(注意是让服务端处理名为“接收Tensor”的服务,而不是让服务端去接收Tensor。因为客户端有接收Tensor的需求,但需要服务端发送Tensor,为客户端发送Tensor的服务被称之为“接收Tensor”),按照注释提示,我们可以在worker.proto中找到RecvTensorRequest和RecvTensorResponse的数据结构,这部分结构读者可以自己查阅,非常容易理解。在编译时,扩展的Protobuf编译器会对worker_service.proto中的rpc接口生成C++服务接口代码和Stub代码(毕竟Stub代码比较纯粹并且和业务逻辑无关,它只是一个向对应Service端发送处理请求的过程),TensorFlow只需要对具体的Service提供实现即可。
与gRPC生成的代码联系起来
gRPC会为worker_service.proto中每一个rpc服务生成C++接口代码,为了区分多个rpc服务,特意为每个服务生成了特殊的名字。比如RecvTensor服务的名字就是/tensorflow.WorkerService/RecvTensor。为了不直接使用冗长的字符串,TensorFlow为worker_service.proto中的每个服务都做了enumeration的映射,这部分代码在tensorflow/core/distributed_runtime/grpc_worker_service_impl.h和同名实现文件中。
1 // Names of worker methods. 2 enum class GrpcWorkerMethod { 3 kGetStatus, 4 kCreateWorkerSession, 5 kDeleteWorkerSession, 6 kRegisterGraph, 7 kDeregisterGraph, 8 kRunGraph, 9 kCleanupGraph, 10 kCleanupAll, 11 kRecvTensor, 12 kRecvBuf, 13 kLogging, 14 kTracing, 15 kCompleteGroup, 16 kCompleteInstance, 17 kGetStepSequence, 18 };
下面是从enumeration类型映射到具体字符串的函数。
1 const char* GrpcWorkerMethodName(GrpcWorkerMethod id) { 2 switch (id) { 3 case GrpcWorkerMethod::kGetStatus: 4 return "/tensorflow.WorkerService/GetStatus"; 5 case GrpcWorkerMethod::kCreateWorkerSession: 6 return "/tensorflow.WorkerService/CreateWorkerSession"; 7 case GrpcWorkerMethod::kDeleteWorkerSession: 8 return "/tensorflow.WorkerService/DeleteWorkerSession"; 9 case GrpcWorkerMethod::kRegisterGraph: 10 return "/tensorflow.WorkerService/RegisterGraph"; 11 case GrpcWorkerMethod::kDeregisterGraph: 12 return "/tensorflow.WorkerService/DeregisterGraph"; 13 case GrpcWorkerMethod::kRunGraph: 14 return "/tensorflow.WorkerService/RunGraph"; 15 case GrpcWorkerMethod::kCleanupGraph: 16 return "/tensorflow.WorkerService/CleanupGraph"; 17 case GrpcWorkerMethod::kCleanupAll: 18 return "/tensorflow.WorkerService/CleanupAll"; 19 case GrpcWorkerMethod::kRecvTensor: 20 return "/tensorflow.WorkerService/RecvTensor"; 21 case GrpcWorkerMethod::kRecvBuf: 22 return "/tensorflow.WorkerService/RecvBuf"; 23 case GrpcWorkerMethod::kLogging: 24 return "/tensorflow.WorkerService/Logging"; 25 case GrpcWorkerMethod::kTracing: 26 return "/tensorflow.WorkerService/Tracing"; 27 case GrpcWorkerMethod::kCompleteGroup: 28 return "/tensorflow.WorkerService/CompleteGroup"; 29 case GrpcWorkerMethod::kCompleteInstance: 30 return "/tensorflow.WorkerService/CompleteInstance"; 31 case GrpcWorkerMethod::kGetStepSequence: 32 return "/tensorflow.WorkerService/GetStepSequence"; 33 } 34 // Shouldn't be reached. 35 LOG(FATAL) << "Invalid id: this line shouldn't be reached."; 36 return "invalid id"; 37 }
另外,还需要为每个RPC服务注册为异步服务,这需要使用gRPC自带的AddMethod接口和MarkMethodAsync接口,如下所示。
1 WorkerService::AsyncService::AsyncService() { 2 for (int i = 0; i < kGrpcNumWorkerMethods; ++i) { 3 AddMethod(new ::grpc::internal::RpcServiceMethod( 4 GrpcWorkerMethodName(static_cast<GrpcWorkerMethod>(i)), 5 ::grpc::internal::RpcMethod::NORMAL_RPC, nullptr)); 6 ::grpc::Service::MarkMethodAsync(i); 7 } 8 }
好了,接下来就是解析源码中具体的交互过程了。其实TensorFlow在框架层面对gRPC的使用了一些Best Practice,比如异步处理请求的架构和多线程轮询Completion Queue等。将这些连在一起梳理需要更多的篇幅,一次性展示大量的内容也不利于阅读,所以我们只对发送和接收过程做一个梳理。
Client端的调用链
从BaseRemoteRendeezvous的RecvAsync出发,逐渐深入调用链底层。时序图是分析调用链的最好工具,下面给出了Client端到Stub的调用过程,这里面涉及到了几个新的类。
1. RpcRecvTensorCall:这是一次gRPC调用的抽象,继承了BaseRecvTensorCall这个抽象基类,它封装了复杂的后续调用链。
2. GrpcRemoteWorker:它也是client端的内容,只不过它是Remote端的代理。
3. RpcState:这是真正封装了一次RPC调用及状态的类,它会直接对Stub以及GenericClientAsyncResponseReader进行管理,比如向服务端发送异步请求并等待结果等。
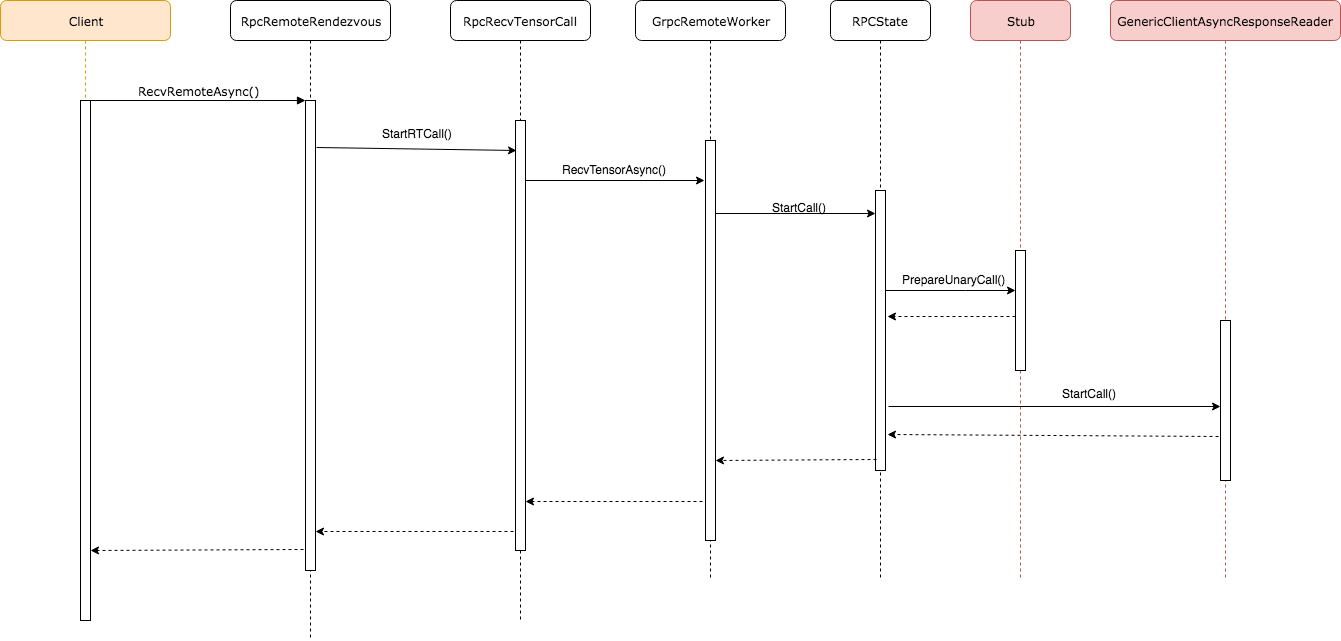
Client端是一个虚拟角色,它可以是调用RpcRemoteRendezvous的任何一个模块。我们可以看到,RpcRemoteRendezvous的一次RecvRemoteAsync过程非常长,并且Stub的调用时异步的。这里的代码确实有些多,所以我们只展示一下关键代码段,但是建议读者打开源码仔细阅读每个调用链。
下面是RecvRemoteAsync的代码段,主要做了RpcRecvTensorCall的初始化,注册以及启动工作。
1 void RpcRemoteRendezvous::RecvFromRemoteAsync( 2 const Rendezvous::ParsedKey& parsed, const Rendezvous::Args& recv_args, 3 DoneCallback done) { 4 CHECK(is_initialized()); 5 Status s; 6 7 // Prepare a RecvTensor call that can handle being aborted. 8 RpcRecvTensorCall* call = get_call_freelist()->New(); 9 10 // key.src_device identifies a remote device. 11 if (!DeviceNameUtils::SplitDeviceName(parsed.src_device, &call->src_worker_, 12 &call->src_rel_device_)) { 13 s = errors::Internal(parsed.src_device, 14 " is invalid remote source device."); 15 } 16 WorkerSession* sess = session(); 17 WorkerInterface* rwi = sess->worker_cache->CreateWorker(call->src_worker_); 18 if (s.ok() && rwi == nullptr) { 19 s = errors::Internal("No worker known as ", call->src_worker_); 20 } 21 22 Device* dst_device; 23 if (s.ok()) { 24 s = sess->device_mgr()->LookupDevice(parsed.dst_device, &dst_device); 25 } 26 if (!s.ok()) { 27 if (rwi != nullptr) { 28 sess->worker_cache->ReleaseWorker(call->src_worker_, rwi); 29 } 30 get_call_freelist()->Release(call, sess->worker_cache.get()); 31 done(s, Args(), recv_args, Tensor{}, false); 32 return; 33 } 34 35 call->Init(rwi, step_id_, parsed.FullKey(), recv_args.alloc_attrs, dst_device, 36 recv_args, std::move(done)); 37 38 // Record "call" in active_ so that it can be aborted cleanly. 39 RegisterCall(call); 40 41 // RendezvousMgr already aborted, shouldn't send RPC call any more 42 if (!call->status().ok()) { 43 call->done()(call->status(), Args(), Args(), Tensor(), false); 44 session()->worker_cache->ReleaseWorker(call->src_worker_, call->wi_); 45 call->wi_ = nullptr; 46 get_call_freelist()->Release(call, session()->worker_cache.get()); 47 return; 48 } 49 50 // Start "call". 51 Ref(); 52 call->Start([this, call]() { 53 // Removes "call" from active_. Prevent StartAbort(). 54 DeregisterCall(call); 55 // If StartAbort was called prior to DeregisterCall, then the 56 // current status should be bad. 57 Status s = call->status(); 58 call->done()(s, Args(), call->recv_args(), call->tensor(), call->is_dead()); 59 session()->worker_cache->ReleaseWorker(call->src_worker_, call->wi_); 60 call->wi_ = nullptr; 61 get_call_freelist()->Release(call, session()->worker_cache.get()); 62 Unref(); 63 }); 64 }
下面是GrpcRemoteWorker调用RPCState的过程,最后的IssueRequest即开始创建RPCState并触发stub的调用。
void RecvTensorAsync(CallOptions* call_opts, const RecvTensorRequest* request, TensorResponse* response, StatusCallback done) override { VLOG(1) << "RecvTensorAsync req: " << request->DebugString(); int64 start_usec = Env::Default()->NowMicros(); // Type-specialized logging for this method. bool logging_active = logger_->LoggingActive() || VLOG_IS_ON(2); StatusCallback wrapper_done; const StatusCallback* cb_to_use; if (!logging_active) { cb_to_use = &done; // No additional work to do, so just use done directly } else { wrapper_done = [this, request, response, done, start_usec](Status s) { if (logger_->LoggingActive()) { int64 end_usec = Env::Default()->NowMicros(); int64 step_id = request->step_id(); int64 bytes = response->tensor().TotalBytes(); int64 send_start_usec = start_usec; // If a send start time was reported by the other side, use // that instead. Maybe we should mark the display if we're using // our local time instead of the remote start time? if (response->metadata().send_start_micros()) { // send_start_micros is the timestamp taken when the // remote machine began to send the RecvTensor response. // Due to clock skew between source and dest machines, it // is possible that send_start_micros can be larger than // end_usec or less than start_usec. // // To respect causality, we enforce the invariants that // the RecvTensor response can not have been sent before // the RecvTensor request, and must have been sent before // it was received. send_start_usec = std::max( start_usec, static_cast<int64>(response->metadata().send_start_micros())); send_start_usec = std::min(send_start_usec, end_usec - 1); } const string& key = request->rendezvous_key(); std::vector<string> key_parts = str_util::Split(key, ';'); if (key_parts.size() != 5) { LOG(WARNING) << "Bad key: " << key; } else { logger_->RecordRecvTensor(step_id, send_start_usec, end_usec, key_parts[3], // tensor name key_parts[0], // src_device key_parts[2], // dst_device bytes); } } VLOG(2) << "done callback, req: " << request->DebugString() << " response " << response->metadata().DebugString(); done(s); }; cb_to_use = &wrapper_done; } IssueRequest(request, response, recvtensor_, *cb_to_use, call_opts); }
最后展示一下Stub的触发位置,这个函数在RPCState类中,并且在创建RPCState对象时立即被调用。
1 void StartCall() { 2 context_.reset(new ::grpc::ClientContext()); 3 context_->set_fail_fast(fail_fast_); 4 5 if (timeout_in_ms_ > 0) { 6 context_->set_deadline( 7 gpr_time_from_millis(timeout_in_ms_, GPR_TIMESPAN)); 8 } 9 if (call_opts_) { 10 call_opts_->SetCancelCallback([this]() { context_->TryCancel(); }); 11 } 12 13 VLOG(2) << "Starting call: " << method_; 14 15 call_ = std::move( 16 stub_->PrepareUnaryCall(context_.get(), method_, request_buf_, cq_)); 17 call_->StartCall(); 18 call_->Finish(&response_buf_, &status_, this); 19 }
Server端负责查找Tensor的Service
如果我们把异步处理请求的架构和多线程轮询Completion Queue的Best Practice去除,那么Service端其实并不复杂,调用链相对Client端短了很多,下面的时序图展示了自Server端接收请求后的调用过程,这里面也涉及到了几个新的类。
1. GrpcWorkerServiceThread:这是服务端处理请求的线程类。
2. GrpcWorker:这是真正负责处理请求的Worker,是GrpcRemoteWorker的服务端版本;
3. WorkerCall:这是服务端处理一次gRPC请求和响应的类,抽象为WorkerCall,其实这也是个别名,真实的名称较长;
4. ServerAsyncResponseWriter:这是gRPC为用户端提供的Response writer,是承载响应的实体。
5. Utils:这其实不是一个类,而是多个工具的组合,为了在时序图表达方便,统称为Utils。

可以看出,服务端接收到请求后,会调用RecvLocalAsync在本地将客户端所需要的Tensor查找出来,然后拷贝到CPU上,最后利用gRPC发送回客户端。同样,我们展示关键代码段。
下面是GrpcWorker调用RendezvousMgr的RecvLocalAsync为客户端寻找真正Tensor的过程。回调函数中能够看出,在找到对应Tensor后,需要将Tensor做Encode,然后拷贝到CPU端。
1 env_->rendezvous_mgr->RecvLocalAsync( 2 step_id, parsed, 3 [opts, response, done, src_dev, request]( 4 const Status& status, const Rendezvous::Args& send_args, 5 const Rendezvous::Args& recv_args, const Tensor& val, 6 const bool is_dead) { 7 opts->ClearCancelCallback(); 8 if (status.ok()) { 9 // DMA can only be used for Tensors that do not fall into 10 // the following three odd edge cases: 1) a zero-size 11 // buffer, 2) a dead tensor which has an uninit value, and 12 // 3) the tensor has the on_host allocation attribute, 13 // i.e. it's in CPU RAM *independent of its assigned 14 // device type*. 15 const bool on_host = send_args.alloc_attrs.on_host(); 16 { 17 // Non-DMA cases. 18 if (src_dev->tensorflow_gpu_device_info() && (!on_host)) { 19 DeviceContext* send_dev_context = send_args.device_context; 20 AllocatorAttributes alloc_attrs; 21 alloc_attrs.set_gpu_compatible(true); 22 alloc_attrs.set_on_host(true); 23 Allocator* alloc = src_dev->GetAllocator(alloc_attrs); 24 Tensor* copy = new Tensor(alloc, val.dtype(), val.shape()); 25 CHECK(send_dev_context) 26 << "send dev name: " << src_dev->name() 27 << " gpu_info: " << src_dev->tensorflow_gpu_device_info(); 28 // "val" is on an accelerator device. Uses the device_context to 29 // fill the copy on host. 30 StatusCallback copy_ready = [response, done, copy, 31 is_dead](const Status& s) { 32 // The value is now ready to be returned on the wire. 33 grpc::EncodeTensorToByteBuffer(is_dead, *copy, response); 34 done(s); 35 delete copy; 36 }; 37 38 send_dev_context->CopyDeviceTensorToCPU( 39 &val, request->rendezvous_key(), src_dev, copy, copy_ready); 40 } else { 41 grpc::EncodeTensorToByteBuffer(is_dead, val, response); 42 done(Status::OK()); 43 } 44 } 45 } else { 46 // !s.ok() 47 done(status); 48 } 49 });
至此,我们的Rendezvous之gRPC传输之旅就圆满结束了,在阅读本篇时还是希望读者能够在理解结构设计后,对照C++源码仔细阅读反复推敲里面的每一个细节,这样才能有更深的理解。
一个需要思考的问题——gRPC传输Tensor很低效?
是的,确实很低效。为什么?从设计哲学上说,gRPC本身设计并不适合深度学习训练场景。从细节上来说它有以下几个缺陷:
1. gRPC发送Tensor前,接收Tensor后必须要做序列化,在Tensor很大的时候这是一个非常讨厌的overhead,发送接收延迟过大;
2. 序列化根本没有对数据做任何压缩,这是因为Tensor都是稠密的,所以序列化没有意义;
3. 不能支持RDMA和GPU Direct。虽然这依赖于硬件,但是gRPC在软件层面也并没有做这些适配。
所以大部分人使用TensorFlow分布式时都会对性能有很大的抱怨,这里面很大的原因和gRPC有关。如果你使用NCCL或者MPI,那么你会得到不一样的性能。
总结
本篇文章篇幅较长,是Rendezvous机制系列的第二篇,主要梳理了涉及到gRPC传输的模块架构设计和源码细节,并且详细梳理了通信过程。理解TensorFlow跨机传输的关键在于理解一个事实:真正的通信过程由Recv方触发,而不是Send方!Send依然将Ready的Tensor挂入本地Table中,而Recv会向Send端发送gRPC请求查询所需要的Tensor,然后返回所需要的结果,这个过程虽然有些别扭,但逻辑上并不稀奇。从结构设计上来说,RemoteRendezvous沿用了Rendezvous接口,并且完全复用了LocalRendezvousImpl的Send代码,而Recv由于涉及到具体的通信细节和管理机制,则各有各的不同。另外,RemoteRendezvous相对LocalRendezvous复杂很多,需要管理器进行管理。最后一大部分是Send和Recv的源码细节展示,因为无论是客户端还是服务端,其调用链都比较长,所以以时序图的形式展示各个类之间的调用关系和协作关系较为清晰,具体每个调用的细节建议读者结合源码逐一分析,并连同本篇文章一起理解较为深刻。最后,我们总结了gRPC传输Tensor的明显缺陷,当然这也是为性能优化开辟了新的空间。