什么是模型:
模型是你的数据唯一的、权威的信息源。它包含你所储存数据的必要字段和行为。每个模型对 应数据库中唯一的一张表。
如何编写模型 :
模型:每个模型都用一个类表示,该类继承自django.db.models.Model。每个模型有多个 类的属性变量,而每一个类的属性变量又都代表了数据库表中的一个字段
字段:每个字段通过Field类的一个实例表示 —— 例如字符字段CharField和日期字段 DateTimeField。这种方法告诉Django,每个字段中保存着什么类型的数据
字段名:每个Field 实例的名字(例如username)就是字段的名字,并且是机器可读的格 式。你将在Python代码中使用到它的值,并且你的数据库将把它用作表的列名
(1)模型字段:
CharField
BooleanField
IntegerField
DateField / DateTimeField
EmailField
TextField
TimeField
(2)迁移命令:
makemigrations, 负责基于你的模型修改创建一个新的迁移
migrate, 负责执行迁移, 以及撤销和列出迁移的状态。
生成迁移文件
python manage.py makemigrations dashboard
会扫描和比较你当前迁移文件里面的版本,同时新的迁移文件会被创建
展示迁移的sql语句
python manage.py sqlmigrate dashboard 0007
数据迁移python manage.py migrate dashboard
(3)创建对象
Django 使用一种直观的方式把数据库表中的数据表示成Python 对象:一个模型类代表数据库中的一个表,一个模型类的实例代表这个数据库表中的一条特定的记录。
使用关键字参数实例化模型实例来创建一个对象,然后调用save() 把它保存到数据库中。使用关键字参数实例模型实例来创建个对象,然后调用save() 把它保存到数据库中。
也可以使用一条语句创建并保存一个对象,使用create()方法
(4)查询对象
通过模型中的管理器构造一个查询集,来从你的数据库中获取对象。
查询集(queryset)表示从数据库中取出来的对象的集合。它可以含有零个、一个或者多个过
滤器。过滤器基于所给的参数限制查询的结果。 从SQL 的角度,查询集和SELECT 语句等
价,过滤器是像WHERE 和LIMIT 一样的限制子句。
你可以从模型的管理器那里取得查询集。每个模型都至少有一个管理器,它默认命名为
objects 通过模型类来直接访问它objects。通过模型类来直接访问它,
管理器只可以通过模型的类访问,而不可以通过模型的实例访问,目的是为了强制区分“表
级别”的操作和“记录级别”的操作。
对于一个模型来说,管理器是查询集的主要来源。例如,User.objects.all() 返回包含数据库
中所有User 对象的一个查询集。
(5)获取所有对象
获取一个表中所有对象的最简单的方式是全部获取。可以使用管理器的all() 方法:
all()方法返回包含数据库中所有对象的一个查询集
all_users = User.objects.all()
31使用过滤器获取特定对象
all() 方法返回了一个包含数据库表中所有记录查询集。但在通常情况下,你往往想要获取
的是完整数据集的一个子集。
要创建这样一个子集,你需要在原始的的查询集上增加一些过滤条件。两个最普遍的途径是:
Òlter(**kwargs) 返回一个新的查询集,它包含满足查询参数的对象。
exclude(**kwargs) 返回一个新的查询集,它包含不满足查询参数的对象。
查询参数(上面函数定义中的**kwargs)需要满足特定的格式,下面字段查询一节中会提
到
(6)使用过滤器获取特定对象示例
要获取年份为2006的所有文章的查询集,可以使用Òlter()方法:
Entry.objects.filter(pub_date__year=2006)
利用默认的管理器,它相当于:
Entry.objects.all().filter(pub_date__year=2006)
(7)链式过滤
查询集的筛选结果本身还是查询集,所以可以将筛选语句链接在一起。像这样:
Entry.objects.filter(
headline__startswith='What’
).exclude(
pub_date__gte=datetime.date.today()
).filter(
pub_date__gte=datetime(2005, 1, 30)
)
这个例子最开始获取数据库中所有对象的一个查询集,之后增加一个过滤器,然后又增加一个
排除,再之后又是另外一个过滤器。最后的结果仍然是一个查询集,它包含标题以”What“开
头、发布日期在2005年1月30日至当天之间的所有记录。
过滤后的查询集是独立的过滤后的查询集是独立的
每次你筛选一个查询集,得到的都是全新的另一个查询集,它和之前的查询集之间没有任何绑
定关系。每次筛选都会创建一个独立的查询集,它可以被存储及反复使用。
q1 = Entry.objects.filter(headline__startswith="What")
q2 = q1.exclude(pub_date__gte=datetime.date.today())
q3 = q1.filter(pub_date__gte=datetime.date.today())
35
查询集是惰性执行的
查询集是惰性执行的 —— 创建查询集不会带来任何数据库的访问。你可以将过滤器保持一整
天,直到查询集 需要求值时,Django 才会真正运行这个查询。天,直到查询集 需要求值时,Django 才会真正运行这个查询。
>>> q = Entry.objects.filter(headline__startswith="What")
>>> q = q.filter(pub_date__lte=datetime.date.today())
>>> q = q.exclude(body_text__icontains="food")
>>> print(q)
虽然它看上去有三次数据库访问,但事实上只有在最后一行(print(q))时才访问一次数据
库。一般来说,只有在“请求”查询集 的结果时才会到数据库中去获取它们。当你确实需要结果
时,查询集 通过访问数据库来求值
(7)获取一个单一的对象——get()
Òlter() 始终给你一个查询集,即使只有一个对象满足查询条件 —— 这种情况下,查询集将
只包含一个元素。
如果你知道只有一个对象满足你的查询,你可以使用管理器的get() 方法,它直接返回该对
象:one_entry = Entry.objects.get(pk=1)
可以对get() 使用任何查询表达式,和Òlter() 一样
使用get() 和使用Òlter() 的切片[0] 有一点区别。如果没有结果满足查询,get() 将引发一个
DoesNotExist 异常。这个异常是正在查询的模型类的一个属性 —— 所以在上面的代码
中,如果没有主键为1 的Entry 对象,Django 将引发一个Entry.DoesNotExist。
如果有多条记录满足get() 的查询条件,Django 也将报错。这种情况将引发
MultipleObjectsReturned,它同样是模型类自身的一个属性。
(8)限制查询集
可以使用Python 的切片语法来限制查询集记录的数目 。它等同于SQL 的LIMIT 和OFFSET 子
句。
>>> Entry.objects.all()[:5]
>>> Entry.objects.all()[5:10]
(9)字段查询
字段查询是指如何指定SQL WHERE 子句的内容。它们通过查询集方法Òlter()、exclude() 和
get() 的关键字参数指定。
查询的关键字参数的基本形式是Òeld__lookuptype=value(中间是两个下划线)
>>> Entry.objects.filter(pub_date__lte='2006-01-01')
SELECT * FROM blog_entry WHERE pub_date <= '2006-01-01';
exact “精确”匹配
iexact 大小写不敏感的匹配
contains 大小写敏感的包含指定字符串
icontains 大小写不敏感的包含指定字符串大小写不敏感的包含指定字符串
startswith, endswith 以指字字符串开头或结尾
istartswith, iendswith
in 在给定的列表内
字段查询
gt 大于
gte 大于或等于
lt 小于
lte 小于或等于
range 在指定范围内
year /month / day/ week_day 对于日期和日期时间字段,匹配年/月/日/星期
40字段查询——exact
>>> Entry.objects.get(headline__exact="Man bites dog")
SELECT ... WHERE headline = 'Man bites dog';
>>> Blog.objects.get(id__exact=14)
>>> Blog.objects.get(id=14)
查询的快捷方式pk
Django 提供一个查询快捷方式pk ,它表示“primary key” 的意思
>>> Blog.objects.get(id__exact=14)
>>> Blog.objects.get(id=14)
>>> Blog.objects.get(pk=14)
order_by
默认情况下 QuerySet 根据模型Meta 类的ordering 选项排序 你可以使用order by 方法默认情况下,QuerySet 根据模型Meta 类的ordering 选项排序。你可以使用order_by 方法
给每个QuerySet 指定特定的排序
Entry.objects.filter(pub_date__year=2005).order_by('-pub_date', 'headline')
上面的结果将按照pub_date 降序排序,然后再按照headline 升序排序。"-pub_date" 前面
的负号表示降序排序。隐式的是升序排序。若要随机排序,请使用"?",像这样:
Entry.objects.order_by('?')
values
返回一个ValuesQuerySet —— QuerySet 的一个子类,迭代时返回字典而不是模型实例对
象。
每个字典表示一个对象,键对应于模型对象的属性名称。values() 接收可选的位置参数*Òelds,它指定SELECT 应该限制哪些字段。如果指定字段,
每个字典将只包含指定的字段的键/值。如果没有指定字段,每个字典将包含数据库表中所
有字段的键和值。
User.objects.values("id", "username")
values_list
与values() 类似,只是在迭代时返回的是元组而不是字典。每个元组包含传递给
values_list() 调用的字段的值 —— 所以第一个元素为第一个字段,以此类推。
User.objects.values_list('id', 'username')
45defer
在一些复杂的数据建模情况下,您的模型可能包含大量字段,其中一些可能包含大量数据
(例如,文本字段),或者需要昂贵的处理来将它们转换为Python对象。如果您在某些情
况下使用查询集的结果,当您最初获取数据时不知道是否需要这些特定字段,可以告诉
Django不要从数据库中检索它们。
User.objects.defer("username", "email")
删除对象
删除对象使用delete()。这个方法将立即删除对象且没有返回值。
Entry.objects.filter(pub_date__year=2005).delete()
拷贝模型实例
虽然没有内建的方法用于拷贝模型实例,但还是很容易创建一个新的实例并让它的所有字段都
拷贝过来。最简单的方法是,只需要将pk 设置为None。
blog = Blog(name='My blog', tagline='Blogging is easy')
blog.save() # blog.pk == 1
blog.pk = None
blog.save() # blog.pk == 2
更新对象
更新对象使用update()
Entry.objects.filter(pub_date__year=2007).update(headline='Everything is the same')
update() 方法会立即执行并返回查询匹配的行数(如果有些行已经具有新的值,返回的行
数可能和被更新的行数不相等)
F() -- 专门取对象中某列值的操作F() 专门取对象中某列值的操作
F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用。通常情况下我们
在更新数据时需要先从数据库里将原数据取出后方在内存里,然后编辑某些属性,最后提
交。例如
order = Order.objects.get(orderid='123456789')
order.amount += 1
order.save()
这时就可以使用F()方法,代码如下
from django.db.models import F
order = Order.objects.get(orderid='123456789')
order.amount = F('amount') - 1
order.save()
Q() -- 对对象的复杂查询
Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询。可以
组合使用 &(and),|(or),~(not)操作符,当一个操作符是用于两个Q的对象,它产生
个新的 对象一个新的Q对象。
Order.objects.get(
Q(desc__startswith='Who'),
Q(create_time=date(2016, 10, 2)) | Q(create_time=date(2016, 10, 6))
)
相当于
SELECT * from polls WHERE question LIKE 'Who%'
AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')
序列化模型对象
from django.core import serializers
data = serializers.serialize("json", SomeModel.objects.all())
序列化子集
from django.core import serializers
data = serializers.serialize("json", User.objects.all()[0:10], fields=('username','is_active'))
2.示例编写idc模型并同步到数据库
(1)models.py:
from django.db import models class Idc(models.Model): name = models.CharField("机房名",max_length=32) address = models.CharField("机房地址",max_length=200) phone = models.CharField("机房联系电话",max_length=15) email = models.EmailField("机房联系email") letter = models.CharField("idc字母简称",max_length=5)
(2)迁移:
(python36env) [vagrant@CentOS7 devops]$ python manage.py makemigrations dashboard 会生成一个0001_initial.py迁移文件
(python36env) [vagrant@CentOS7 devops]$ python manage.py migrate dashboard把迁移文件同步到数据库
MariaDB [devops]> show tables;
dashboard_idc
MariaDB [devops]> desc dashboard_idc;
3.listview利用示例--以json形式展示用户列表
(1)views.py:
from django.views.generic import TemplateView,ListView import json
class UserListView(ListView): #返回的是数据库的列表
template_name = "test.html" #指定模版,因为ListView是继承TemplateView
model = User #指定模型
paginate_by = 10 #分页分页展示10条
(2)urls.py:
from django.conf.urls import include, url
from .views import UserListView
urlpatterns = [
url(r'^hello/', UserListView.as_view(), name="hello"),
]
(3)test.html:
<body>
<ul>
{% for object in object_list %}
<li>
{{ object.username }}
</li>
{% endfor %}
</ul>
</body>
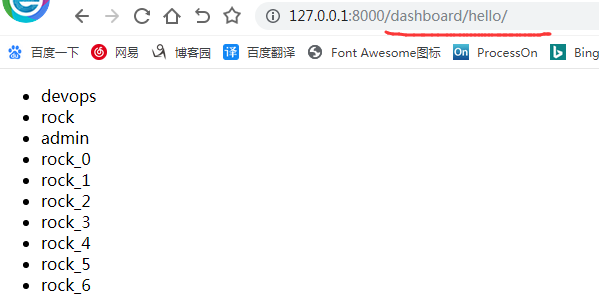
这样就出来如下效果了:
3.2 我想展示分页的所有功能;
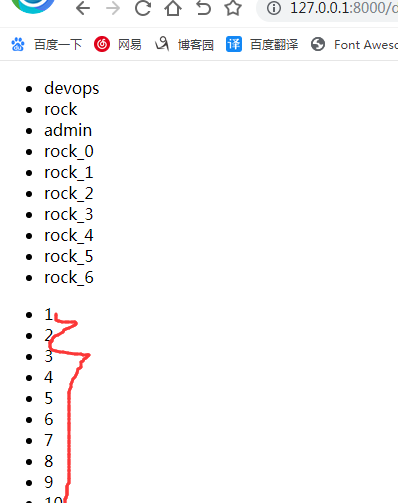
(1)test.html中加入如下代码:
</ul>
<ul >
{% for p in paginator.page_range %}
<li>{{ p }}</li>
{% endfor %}
</ul>
效果如下图:出来了
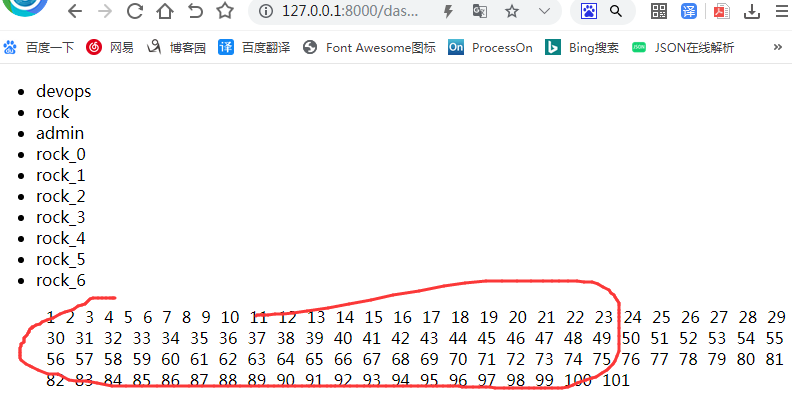
(2)让它们横展示,test.html中修改:
<style>
.page{list-style-type: none}
.page li{float:left;margin-left:10px;}
</style>
........
<ul class="page">
{% for p in paginator.page_range %}
<li>{{ p }}</li>
{% endfor %}
</ul>
效果如下图:
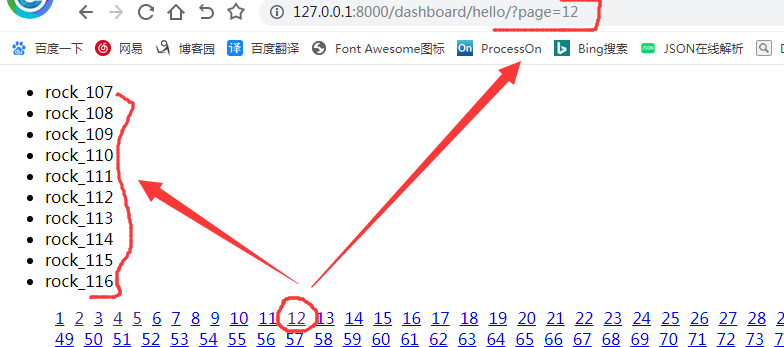
(3)给它们加上当前的url---在模版中引入url的别名({% url "hello" %})并给它们一a链接
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> .page{list-style-type: none} .page li{float:left;margin-left:10px;} </style> </head> <body> <ul> {% for object in object_list %} <li> {{ object.username }} </li> {% endfor %} </ul> <ul class="page"> {% for p in paginator.page_range %} <li><a href="{% url "hello" %}?page={{ p }}">{{ p }}</a></li> {% endfor %} </ul> </body> </html>
效果如下图: