1.什么是Lucene?
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
2.什么是solr?
为什么要solr:
1、solr是将整个索引操作功能封装好了的搜索引擎系统(企业级搜索引擎产品)
2、solr可以部署到单独的服务器上(WEB服务),它可以提供服务,我们的业务系统就只要发送请求,接收响应即可,降低了业务系统的负载
3、solr部署在专门的服务器上,它的索引库就不会受业务系统服务器存储空间的限制
4、solr支持分布式集群,索引服务的容量和能力可以线性扩展
solr的工作机制:
1、solr就是在lucene工具包的基础之上进行了封装,而且是以web服务的形式对外提供索引功能
2、业务系统需要使用到索引的功能(建索引,查索引)时,只要发出http请求,并将返回数据进行解析即可
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
3.lucene和solr的关系
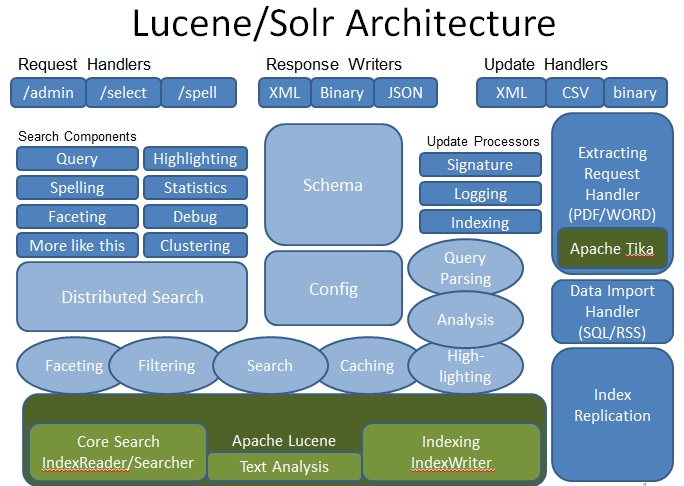
solr是门户,lucene是底层基础,solr和lucene的关系正如hadoop和hdfs的关系。那么solr是怎么调用到lucene的呢?
我们以查询为例,来看一下整个过程,导入过程可以参考:
solr源码分析之数据导入DataImporter追溯
4.solr是怎么调用到lucene?
4.1.准备工作
lucene-solr本地调试方法
使用内置jetty启动main方法。
4.2 进入Solr-admin:http://localhost:8983/solr/
创建一个new_core集合
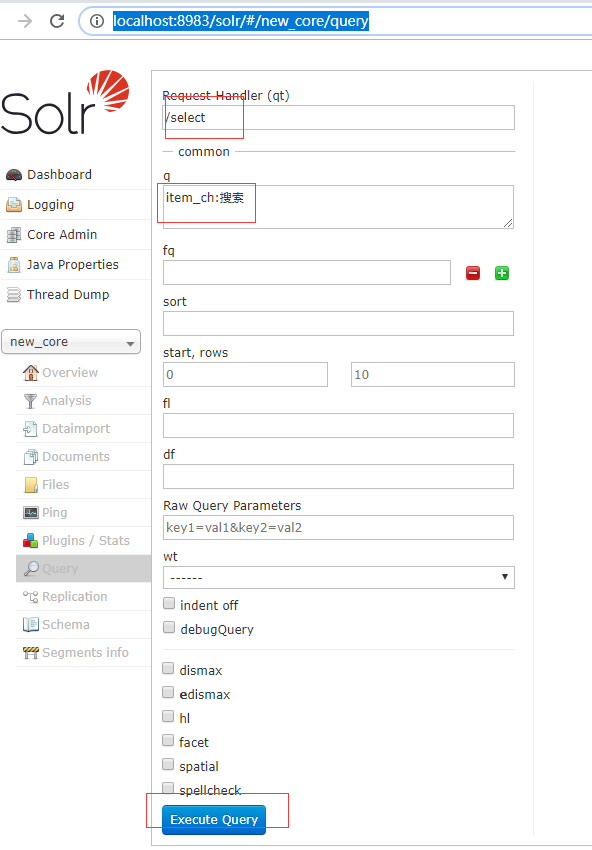
4.3 进入http://localhost:8983/solr/#/new_core/query
选择一个field进行查询
4.4 入口是SolrDispatchFilter,整个流程如流程图所示
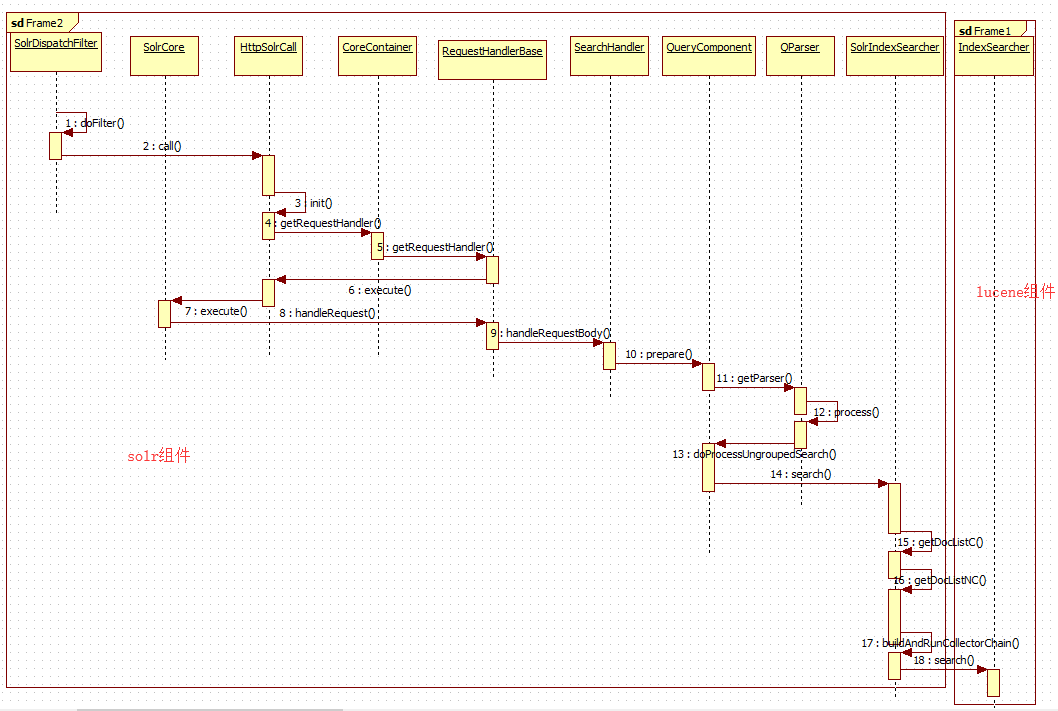
从上面的流程图可以看出,solr采用filter的模式(如struts2,springmvc使用servlet模式),然后以容器的方式来封装各种Handler,Handler负责处理各种请求,最终调用的是lucene的底层实现。
注意:solr没有使用lucene本身的QueryParser,而是自己重写了这个组件。
4.4.1 SolrDispatchFilter入口
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain, boolean retry) throws IOException, ServletException {
if (!(request instanceof HttpServletRequest)) return;
try {
if (cores == null || cores.isShutDown()) {
try {
init.await();
} catch (InterruptedException e) { //well, no wait then
}
final String msg = "Error processing the request. CoreContainer is either not initialized or shutting down.";
if (cores == null || cores.isShutDown()) {
log.error(msg);
throw new UnavailableException(msg);
}
}
AtomicReference<ServletRequest> wrappedRequest = new AtomicReference<>();
if (!authenticateRequest(request, response, wrappedRequest)) { // the response and status code have already been
// sent
return;
}
if (wrappedRequest.get() != null) {
request = wrappedRequest.get();
}
request = closeShield(request, retry);
response = closeShield(response, retry);
if (cores.getAuthenticationPlugin() != null) {
log.debug("User principal: {}", ((HttpServletRequest) request).getUserPrincipal());
}
// No need to even create the HttpSolrCall object if this path is excluded.
if (excludePatterns != null) {
String requestPath = ((HttpServletRequest) request).getServletPath();
String extraPath = ((HttpServletRequest) request).getPathInfo();
if (extraPath != null) { // In embedded mode, servlet path is empty - include all post-context path here for
// testing
requestPath += extraPath;
}
for (Pattern p : excludePatterns) {
Matcher matcher = p.matcher(requestPath);
if (matcher.lookingAt()) {
chain.doFilter(request, response);
return;
}
}
}
HttpSolrCall call = getHttpSolrCall((HttpServletRequest) request, (HttpServletResponse) response, retry);
ExecutorUtil.setServerThreadFlag(Boolean.TRUE);
try {
Action result = call.call(); //1
switch (result) {
case PASSTHROUGH:
chain.doFilter(request, response);
break;
case RETRY:
doFilter(request, response, chain, true);
break;
case FORWARD:
request.getRequestDispatcher(call.getPath()).forward(request, response);
break;
}
} finally {
call.destroy();
ExecutorUtil.setServerThreadFlag(null);
}
} finally {
consumeInputFully((HttpServletRequest) request);
}
}
红色部分的调用
4.4.2 HttpSolrCall
/**
* This method processes the request.
*/
public Action call() throws IOException {
MDCLoggingContext.reset();
MDCLoggingContext.setNode(cores);
if (cores == null) {
sendError(503, "Server is shutting down or failed to initialize");
return RETURN;
}
if (solrDispatchFilter.abortErrorMessage != null) {
sendError(500, solrDispatchFilter.abortErrorMessage);
return RETURN;
}
try {
init();//1
/* Authorize the request if
1. Authorization is enabled, and
2. The requested resource is not a known static file
*/
if (cores.getAuthorizationPlugin() != null && shouldAuthorize()) {
AuthorizationContext context = getAuthCtx();
log.debug("AuthorizationContext : {}", context);
AuthorizationResponse authResponse = cores.getAuthorizationPlugin().authorize(context);
if (authResponse.statusCode == AuthorizationResponse.PROMPT.statusCode) {
Map<String, String> headers = (Map) getReq().getAttribute(AuthenticationPlugin.class.getName());
if (headers != null) {
for (Map.Entry<String, String> e : headers.entrySet()) response.setHeader(e.getKey(), e.getValue());
}
log.debug("USER_REQUIRED "+req.getHeader("Authorization")+" "+ req.getUserPrincipal());
}
if (!(authResponse.statusCode == HttpStatus.SC_ACCEPTED) && !(authResponse.statusCode == HttpStatus.SC_OK)) {
log.info("USER_REQUIRED auth header {} context : {} ", req.getHeader("Authorization"), context);
sendError(authResponse.statusCode,
"Unauthorized request, Response code: " + authResponse.statusCode);
return RETURN;
}
}
HttpServletResponse resp = response;
switch (action) {
case ADMIN:
handleAdminRequest();
return RETURN;
case REMOTEQUERY:
remoteQuery(coreUrl + path, resp);
return RETURN;
case PROCESS:
final Method reqMethod = Method.getMethod(req.getMethod());
HttpCacheHeaderUtil.setCacheControlHeader(config, resp, reqMethod);
// unless we have been explicitly told not to, do cache validation
// if we fail cache validation, execute the query
if (config.getHttpCachingConfig().isNever304() ||
!HttpCacheHeaderUtil.doCacheHeaderValidation(solrReq, req, reqMethod, resp)) {
SolrQueryResponse solrRsp = new SolrQueryResponse();
/* even for HEAD requests, we need to execute the handler to
* ensure we don't get an error (and to make sure the correct
* QueryResponseWriter is selected and we get the correct
* Content-Type)
*/
SolrRequestInfo.setRequestInfo(new SolrRequestInfo(solrReq, solrRsp));
execute(solrRsp); //2
HttpCacheHeaderUtil.checkHttpCachingVeto(solrRsp, resp, reqMethod);
Iterator<Map.Entry<String, String>> headers = solrRsp.httpHeaders();
while (headers.hasNext()) {
Map.Entry<String, String> entry = headers.next();
resp.addHeader(entry.getKey(), entry.getValue());
}
QueryResponseWriter responseWriter = getResponseWriter();
if (invalidStates != null) solrReq.getContext().put(CloudSolrClient.STATE_VERSION, invalidStates);
writeResponse(solrRsp, responseWriter, reqMethod);
}
return RETURN;
default: return action;
}
} catch (Throwable ex) {
sendError(ex);
// walk the the entire cause chain to search for an Error
Throwable t = ex;
while (t != null) {
if (t instanceof Error) {
if (t != ex) {
log.error("An Error was wrapped in another exception - please report complete stacktrace on SOLR-6161", ex);
}
throw (Error) t;
}
t = t.getCause();
}
return RETURN;
} finally {
MDCLoggingContext.clear();
}
}
其中 1初始化,2.执行请求调用
4.4.3 获取Handler
protected void init() throws Exception {
// check for management path
String alternate = cores.getManagementPath();
if (alternate != null && path.startsWith(alternate)) {
path = path.substring(0, alternate.length());
}
// unused feature ?
int idx = path.indexOf(':');
if (idx > 0) {
// save the portion after the ':' for a 'handler' path parameter
path = path.substring(0, idx);
}
// Check for container handlers
handler = cores.getRequestHandler(path);
if (handler != null) {
solrReq = SolrRequestParsers.DEFAULT.parse(null, path, req);
solrReq.getContext().put(CoreContainer.class.getName(), cores);
requestType = RequestType.ADMIN;
action = ADMIN;
return;
}
// Parse a core or collection name from the path and attempt to see if it's a core name
idx = path.indexOf("/", 1);
if (idx > 1) {
origCorename = path.substring(1, idx);
// Try to resolve a Solr core name
core = cores.getCore(origCorename);
if (core != null) {
path = path.substring(idx);
} else {
if (cores.isCoreLoading(origCorename)) { // extra mem barriers, so don't look at this before trying to get core
throw new SolrException(ErrorCode.SERVICE_UNAVAILABLE, "SolrCore is loading");
}
// the core may have just finished loading
core = cores.getCore(origCorename);
if (core != null) {
path = path.substring(idx);
} else {
if (!cores.isZooKeeperAware()) {
core = cores.getCore("");
}
}
}
}
if (cores.isZooKeeperAware()) {
// init collectionList (usually one name but not when there are aliases)
String def = core != null ? core.getCoreDescriptor().getCollectionName() : origCorename;
collectionsList = resolveCollectionListOrAlias(queryParams.get(COLLECTION_PROP, def)); // &collection= takes precedence
if (core == null) {
// lookup core from collection, or route away if need to
String collectionName = collectionsList.isEmpty() ? null : collectionsList.get(0); // route to 1st
//TODO try the other collections if can't find a local replica of the first? (and do to V2HttpSolrCall)
boolean isPreferLeader = (path.endsWith("/update") || path.contains("/update/"));
core = getCoreByCollection(collectionName, isPreferLeader); // find a local replica/core for the collection
if (core != null) {
if (idx > 0) {
path = path.substring(idx);
}
} else {
// if we couldn't find it locally, look on other nodes
if (idx > 0) {
extractRemotePath(collectionName, origCorename);
if (action == REMOTEQUERY) {
path = path.substring(idx);
return;
}
}
//core is not available locally or remotely
autoCreateSystemColl(collectionName);
if (action != null) return;
}
}
}
// With a valid core...
if (core != null) {
MDCLoggingContext.setCore(core);
config = core.getSolrConfig();
// get or create/cache the parser for the core
SolrRequestParsers parser = config.getRequestParsers();
// Determine the handler from the url path if not set
// (we might already have selected the cores handler)
extractHandlerFromURLPath(parser);
if (action != null) return;
// With a valid handler and a valid core...
if (handler != null) {
// if not a /select, create the request
if (solrReq == null) {
solrReq = parser.parse(core, path, req);
}
invalidStates = checkStateVersionsAreValid(solrReq.getParams().get(CloudSolrClient.STATE_VERSION));
addCollectionParamIfNeeded(getCollectionsList());
action = PROCESS;
return; // we are done with a valid handler
}
}
log.debug("no handler or core retrieved for " + path + ", follow through...");
action = PASSTHROUGH;
}
4.4.4 CoreContainer
public SolrRequestHandler getRequestHandler(String path) {
return RequestHandlerBase.getRequestHandler(path, containerHandlers);
}
4.4.5 RequestHandlerBase
/**
* Get the request handler registered to a given name.
*
* This function is thread safe.
*/
public static SolrRequestHandler getRequestHandler(String handlerName, PluginBag<SolrRequestHandler> reqHandlers) {
if(handlerName == null) return null;
SolrRequestHandler handler = reqHandlers.get(handlerName);
int idx = 0;
if(handler == null) {
for (; ; ) {
idx = handlerName.indexOf('/', idx+1);
if (idx > 0) {
String firstPart = handlerName.substring(0, idx);
handler = reqHandlers.get(firstPart);
if (handler == null) continue;
if (handler instanceof NestedRequestHandler) {
return ((NestedRequestHandler) handler).getSubHandler(handlerName.substring(idx));
}
} else {
break;
}
}
}
return handler;
}
4.4.6HttpSolrCall
protected void execute(SolrQueryResponse rsp) {
// a custom filter could add more stuff to the request before passing it on.
// for example: sreq.getContext().put( "HttpServletRequest", req );
// used for logging query stats in SolrCore.execute()
solrReq.getContext().put("webapp", req.getContextPath());
solrReq.getCore().execute(handler, solrReq, rsp);
}
4.4.7 SolrCore
public void execute(SolrRequestHandler handler, SolrQueryRequest req, SolrQueryResponse rsp) {
if (handler==null) {
String msg = "Null Request Handler '" +
req.getParams().get(CommonParams.QT) + "'";
if (log.isWarnEnabled()) log.warn(logid + msg + ":" + req);
throw new SolrException(ErrorCode.BAD_REQUEST, msg);
}
preDecorateResponse(req, rsp);
if (requestLog.isDebugEnabled() && rsp.getToLog().size() > 0) {
// log request at debug in case something goes wrong and we aren't able to log later
requestLog.debug(rsp.getToLogAsString(logid));
}
// TODO: this doesn't seem to be working correctly and causes problems with the example server and distrib (for example /spell)
// if (req.getParams().getBool(ShardParams.IS_SHARD,false) && !(handler instanceof SearchHandler))
// throw new SolrException(SolrException.ErrorCode.BAD_REQUEST,"isShard is only acceptable with search handlers");
handler.handleRequest(req,rsp);
postDecorateResponse(handler, req, rsp);
if (rsp.getToLog().size() > 0) {
if (requestLog.isInfoEnabled()) {
requestLog.info(rsp.getToLogAsString(logid));
}
if (log.isWarnEnabled() && slowQueryThresholdMillis >= 0) {
final long qtime = (long) (req.getRequestTimer().getTime());
if (qtime >= slowQueryThresholdMillis) {
log.warn("slow: " + rsp.getToLogAsString(logid));
}
}
}
}
4.4.8 RequestHandlerBase
@Override
public void handleRequest(SolrQueryRequest req, SolrQueryResponse rsp) {
requests.inc();
Timer.Context timer = requestTimes.time();
try {
if(pluginInfo != null && pluginInfo.attributes.containsKey(USEPARAM)) req.getContext().put(USEPARAM,pluginInfo.attributes.get(USEPARAM));
SolrPluginUtils.setDefaults(this, req, defaults, appends, invariants);
req.getContext().remove(USEPARAM);
rsp.setHttpCaching(httpCaching);
handleRequestBody( req, rsp );
// count timeouts
NamedList header = rsp.getResponseHeader();
if(header != null) {
Object partialResults = header.get(SolrQueryResponse.RESPONSE_HEADER_PARTIAL_RESULTS_KEY);
boolean timedOut = partialResults == null ? false : (Boolean)partialResults;
if( timedOut ) {
numTimeouts.mark();
rsp.setHttpCaching(false);
}
}
} catch (Exception e) {
boolean incrementErrors = true;
boolean isServerError = true;
if (e instanceof SolrException) {
SolrException se = (SolrException)e;
if (se.code() == SolrException.ErrorCode.CONFLICT.code) {
incrementErrors = false;
} else if (se.code() >= 400 && se.code() < 500) {
isServerError = false;
}
} else {
if (e instanceof SyntaxError) {
isServerError = false;
e = new SolrException(SolrException.ErrorCode.BAD_REQUEST, e);
}
}
rsp.setException(e);
if (incrementErrors) {
SolrException.log(log, e);
numErrors.mark();
if (isServerError) {
numServerErrors.mark();
} else {
numClientErrors.mark();
}
}
} finally {
long elapsed = timer.stop();
totalTime.inc(elapsed);
}
}
4.4.9 SearchHandler
@Override
public void handleRequestBody(SolrQueryRequest req, SolrQueryResponse rsp) throws Exception
{
List<SearchComponent> components = getComponents();
ResponseBuilder rb = new ResponseBuilder(req, rsp, components);
if (rb.requestInfo != null) {
rb.requestInfo.setResponseBuilder(rb);
}
boolean dbg = req.getParams().getBool(CommonParams.DEBUG_QUERY, false);
rb.setDebug(dbg);
if (dbg == false){//if it's true, we are doing everything anyway.
SolrPluginUtils.getDebugInterests(req.getParams().getParams(CommonParams.DEBUG), rb);
}
final RTimerTree timer = rb.isDebug() ? req.getRequestTimer() : null;
final ShardHandler shardHandler1 = getAndPrepShardHandler(req, rb); // creates a ShardHandler object only if it's needed
if (timer == null) {
// non-debugging prepare phase
for( SearchComponent c : components ) {
c.prepare(rb); //1
}
} else {
// debugging prepare phase
RTimerTree subt = timer.sub( "prepare" );
for( SearchComponent c : components ) {
rb.setTimer( subt.sub( c.getName() ) );
c.prepare(rb);
rb.getTimer().stop();
}
subt.stop();
}
if (!rb.isDistrib) {
// a normal non-distributed request
long timeAllowed = req.getParams().getLong(CommonParams.TIME_ALLOWED, -1L);
if (timeAllowed > 0L) {
SolrQueryTimeoutImpl.set(timeAllowed);
}
try {
// The semantics of debugging vs not debugging are different enough that
// it makes sense to have two control loops
if(!rb.isDebug()) {
// Process
for( SearchComponent c : components ) {
c.process(rb); //2
}
}
else {
// Process
RTimerTree subt = timer.sub( "process" );
for( SearchComponent c : components ) {
rb.setTimer( subt.sub( c.getName() ) );
c.process(rb);
rb.getTimer().stop();
}
subt.stop();
// add the timing info
if (rb.isDebugTimings()) {
rb.addDebugInfo("timing", timer.asNamedList() );
}
}
} catch (ExitableDirectoryReader.ExitingReaderException ex) {
log.warn( "Query: " + req.getParamString() + "; " + ex.getMessage());
SolrDocumentList r = (SolrDocumentList) rb.rsp.getResponse();
if(r == null)
r = new SolrDocumentList();
r.setNumFound(0);
rb.rsp.addResponse(r);
if(rb.isDebug()) {
NamedList debug = new NamedList();
debug.add("explain", new NamedList());
rb.rsp.add("debug", debug);
}
rb.rsp.getResponseHeader().add(SolrQueryResponse.RESPONSE_HEADER_PARTIAL_RESULTS_KEY, Boolean.TRUE);
} finally {
SolrQueryTimeoutImpl.reset();
}
} else {
// a distributed request
if (rb.outgoing == null) {
rb.outgoing = new LinkedList<>();
}
rb.finished = new ArrayList<>();
int nextStage = 0;
do {
rb.stage = nextStage;
nextStage = ResponseBuilder.STAGE_DONE;
// call all components
for( SearchComponent c : components ) {
// the next stage is the minimum of what all components report
nextStage = Math.min(nextStage, c.distributedProcess(rb));
}
// check the outgoing queue and send requests
while (rb.outgoing.size() > 0) {
// submit all current request tasks at once
while (rb.outgoing.size() > 0) {
ShardRequest sreq = rb.outgoing.remove(0);
sreq.actualShards = sreq.shards;
if (sreq.actualShards==ShardRequest.ALL_SHARDS) {
sreq.actualShards = rb.shards;
}
sreq.responses = new ArrayList<>(sreq.actualShards.length); // presume we'll get a response from each shard we send to
// TODO: map from shard to address[]
for (String shard : sreq.actualShards) {
ModifiableSolrParams params = new ModifiableSolrParams(sreq.params);
params.remove(ShardParams.SHARDS); // not a top-level request
params.set(DISTRIB, "false"); // not a top-level request
params.remove("indent");
params.remove(CommonParams.HEADER_ECHO_PARAMS);
params.set(ShardParams.IS_SHARD, true); // a sub (shard) request
params.set(ShardParams.SHARDS_PURPOSE, sreq.purpose);
params.set(ShardParams.SHARD_URL, shard); // so the shard knows what was asked
if (rb.requestInfo != null) {
// we could try and detect when this is needed, but it could be tricky
params.set("NOW", Long.toString(rb.requestInfo.getNOW().getTime()));
}
String shardQt = params.get(ShardParams.SHARDS_QT);
if (shardQt != null) {
params.set(CommonParams.QT, shardQt);
} else {
// for distributed queries that don't include shards.qt, use the original path
// as the default but operators need to update their luceneMatchVersion to enable
// this behavior since it did not work this way prior to 5.1
String reqPath = (String) req.getContext().get(PATH);
if (!"/select".equals(reqPath)) {
params.set(CommonParams.QT, reqPath);
} // else if path is /select, then the qt gets passed thru if set
}
shardHandler1.submit(sreq, shard, params);
}
}
// now wait for replies, but if anyone puts more requests on
// the outgoing queue, send them out immediately (by exiting
// this loop)
boolean tolerant = rb.req.getParams().getBool(ShardParams.SHARDS_TOLERANT, false);
while (rb.outgoing.size() == 0) {
ShardResponse srsp = tolerant ?
shardHandler1.takeCompletedIncludingErrors():
shardHandler1.takeCompletedOrError();
if (srsp == null) break; // no more requests to wait for
// Was there an exception?
if (srsp.getException() != null) {
// If things are not tolerant, abort everything and rethrow
if(!tolerant) {
shardHandler1.cancelAll();
if (srsp.getException() instanceof SolrException) {
throw (SolrException)srsp.getException();
} else {
throw new SolrException(SolrException.ErrorCode.SERVER_ERROR, srsp.getException());
}
} else {
if(rsp.getResponseHeader().get(SolrQueryResponse.RESPONSE_HEADER_PARTIAL_RESULTS_KEY) == null) {
rsp.getResponseHeader().add(SolrQueryResponse.RESPONSE_HEADER_PARTIAL_RESULTS_KEY, Boolean.TRUE);
}
}
}
rb.finished.add(srsp.getShardRequest());
// let the components see the responses to the request
for(SearchComponent c : components) {
c.handleResponses(rb, srsp.getShardRequest());
}
}
}
for(SearchComponent c : components) {
c.finishStage(rb);
} //3
// we are done when the next stage is MAX_VALUE
} while (nextStage != Integer.MAX_VALUE);
}
// SOLR-5550: still provide shards.info if requested even for a short circuited distrib request
if(!rb.isDistrib && req.getParams().getBool(ShardParams.SHARDS_INFO, false) && rb.shortCircuitedURL != null) {
NamedList<Object> shardInfo = new SimpleOrderedMap<Object>();
SimpleOrderedMap<Object> nl = new SimpleOrderedMap<Object>();
if (rsp.getException() != null) {
Throwable cause = rsp.getException();
if (cause instanceof SolrServerException) {
cause = ((SolrServerException)cause).getRootCause();
} else {
if (cause.getCause() != null) {
cause = cause.getCause();
}
}
nl.add("error", cause.toString() );
StringWriter trace = new StringWriter();
cause.printStackTrace(new PrintWriter(trace));
nl.add("trace", trace.toString() );
}
else {
nl.add("numFound", rb.getResults().docList.matches());
nl.add("maxScore", rb.getResults().docList.maxScore());
}
nl.add("shardAddress", rb.shortCircuitedURL);
nl.add("time", req.getRequestTimer().getTime()); // elapsed time of this request so far
int pos = rb.shortCircuitedURL.indexOf("://");
String shardInfoName = pos != -1 ? rb.shortCircuitedURL.substring(pos+3) : rb.shortCircuitedURL;
shardInfo.add(shardInfoName, nl);
rsp.getValues().add(ShardParams.SHARDS_INFO,shardInfo);
}
}
4.4.10 QueryComponent
/**
* Actually run the query
*/
@Override
public void process(ResponseBuilder rb) throws IOException
{
LOG.debug("process: {}", rb.req.getParams());
SolrQueryRequest req = rb.req;
SolrParams params = req.getParams();
if (!params.getBool(COMPONENT_NAME, true)) {
return;
}
StatsCache statsCache = req.getCore().getStatsCache();
int purpose = params.getInt(ShardParams.SHARDS_PURPOSE, ShardRequest.PURPOSE_GET_TOP_IDS);
if ((purpose & ShardRequest.PURPOSE_GET_TERM_STATS) != 0) {
SolrIndexSearcher searcher = req.getSearcher();
statsCache.returnLocalStats(rb, searcher);
return;
}
// check if we need to update the local copy of global dfs
if ((purpose & ShardRequest.PURPOSE_SET_TERM_STATS) != 0) {
// retrieve from request and update local cache
statsCache.receiveGlobalStats(req);
}
// Optional: This could also be implemented by the top-level searcher sending
// a filter that lists the ids... that would be transparent to
// the request handler, but would be more expensive (and would preserve score
// too if desired).
if (doProcessSearchByIds(rb)) {
return;
}
// -1 as flag if not set.
long timeAllowed = params.getLong(CommonParams.TIME_ALLOWED, -1L);
if (null != rb.getCursorMark() && 0 < timeAllowed) {
// fundamentally incompatible
throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, "Can not search using both " +
CursorMarkParams.CURSOR_MARK_PARAM + " and " + CommonParams.TIME_ALLOWED);
}
QueryCommand cmd = rb.getQueryCommand();
cmd.setTimeAllowed(timeAllowed);
req.getContext().put(SolrIndexSearcher.STATS_SOURCE, statsCache.get(req));
QueryResult result = new QueryResult();
cmd.setSegmentTerminateEarly(params.getBool(CommonParams.SEGMENT_TERMINATE_EARLY, CommonParams.SEGMENT_TERMINATE_EARLY_DEFAULT));
if (cmd.getSegmentTerminateEarly()) {
result.setSegmentTerminatedEarly(Boolean.FALSE);
}
//
// grouping / field collapsing
//
GroupingSpecification groupingSpec = rb.getGroupingSpec();
if (groupingSpec != null) {
cmd.setSegmentTerminateEarly(false); // not supported, silently ignore any segmentTerminateEarly flag
try {
if (params.getBool(GroupParams.GROUP_DISTRIBUTED_FIRST, false)) {
doProcessGroupedDistributedSearchFirstPhase(rb, cmd, result);
return;
} else if (params.getBool(GroupParams.GROUP_DISTRIBUTED_SECOND, false)) {
doProcessGroupedDistributedSearchSecondPhase(rb, cmd, result);
return;
}
doProcessGroupedSearch(rb, cmd, result);
return;
} catch (SyntaxError e) {
throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, e);
}
}
// normal search result
doProcessUngroupedSearch(rb, cmd, result);
}
4.4.11 SolrIndexSearcher
private void doProcessUngroupedSearch(ResponseBuilder rb, QueryCommand cmd, QueryResult result) throws IOException {
SolrQueryRequest req = rb.req;
SolrQueryResponse rsp = rb.rsp;
SolrIndexSearcher searcher = req.getSearcher();
searcher.search(result, cmd);
rb.setResult(result);
ResultContext ctx = new BasicResultContext(rb);
rsp.addResponse(ctx);
rsp.getToLog().add("hits", rb.getResults().docList.matches());
if ( ! rb.req.getParams().getBool(ShardParams.IS_SHARD,false) ) {
if (null != rb.getNextCursorMark()) {
rb.rsp.add(CursorMarkParams.CURSOR_MARK_NEXT,
rb.getNextCursorMark().getSerializedTotem());
}
}
if(rb.mergeFieldHandler != null) {
rb.mergeFieldHandler.handleMergeFields(rb, searcher);
} else {
doFieldSortValues(rb, searcher);
}
doPrefetch(rb);
}
4.4.12SolrIndexSearcher
/**
* Builds the necessary collector chain (via delegate wrapping) and executes the query against it. This method takes
* into consideration both the explicitly provided collector and postFilter as well as any needed collector wrappers
* for dealing with options specified in the QueryCommand.
*/
private void buildAndRunCollectorChain(QueryResult qr, Query query, Collector collector, QueryCommand cmd,
DelegatingCollector postFilter) throws IOException {
EarlyTerminatingSortingCollector earlyTerminatingSortingCollector = null;
if (cmd.getSegmentTerminateEarly()) {
final Sort cmdSort = cmd.getSort();
final int cmdLen = cmd.getLen();
final Sort mergeSort = core.getSolrCoreState().getMergePolicySort();
if (cmdSort == null || cmdLen <= 0 || mergeSort == null ||
!EarlyTerminatingSortingCollector.canEarlyTerminate(cmdSort, mergeSort)) {
log.warn("unsupported combination: segmentTerminateEarly=true cmdSort={} cmdLen={} mergeSort={}", cmdSort, cmdLen, mergeSort);
} else {
collector = earlyTerminatingSortingCollector = new EarlyTerminatingSortingCollector(collector, cmdSort, cmd.getLen());
}
}
final boolean terminateEarly = cmd.getTerminateEarly();
if (terminateEarly) {
collector = new EarlyTerminatingCollector(collector, cmd.getLen());
}
final long timeAllowed = cmd.getTimeAllowed();
if (timeAllowed > 0) {
collector = new TimeLimitingCollector(collector, TimeLimitingCollector.getGlobalCounter(), timeAllowed);
}
if (postFilter != null) {
postFilter.setLastDelegate(collector);
collector = postFilter;
}
try {
super.search(query, collector);
} catch (TimeLimitingCollector.TimeExceededException | ExitableDirectoryReader.ExitingReaderException x) {
log.warn("Query: [{}]; {}", query, x.getMessage());
qr.setPartialResults(true);
} catch (EarlyTerminatingCollectorException etce) {
if (collector instanceof DelegatingCollector) {
((DelegatingCollector) collector).finish();
}
throw etce;
} finally {
if (earlyTerminatingSortingCollector != null) {
qr.setSegmentTerminatedEarly(earlyTerminatingSortingCollector.terminatedEarly());
}
}
if (collector instanceof DelegatingCollector) {
((DelegatingCollector) collector).finish();
}
}
5.总结
从solr-lucene架构图所示,solr封装了handler来处理各种请求,底下是SearchComponent,分为pre,process,post三阶段处理,最后调用lucene的底层api。
lucene 底层通过Similarity来完成打分过程,详细 介绍了lucene的底层文件结构,和一步步如何实现打分。
参考资料:
【1】http://www.blogjava.net/hoojo/archive/2012/09/06/387140.html
【2】https://www.cnblogs.com/peaceliu/p/7786851.html