引用:https://blog.csdn.net/weiqi7777/article/details/78636903
irun支持MSIE编译,MSIE的全称是 multi-snapshot incremental elaboration。将多个编译好的snapshot,组合成一个最终的snapshot,去仿真。
利用这个技术,我们就可以使用irun来进行增量编译,从而节约编译时间。
为了实现增量编译,我们将snapshot分为primary snapshot和incremental snapshot,primary snapshot指环境中不经常变化的代码,编译成的snapshot,incremental snapshot指环境中经常变化的代码,编译成的snapshot,最后再将这两个snapshot进行组合,得到最终的snapshot,去仿真。
一、编译流程
下图是单个primary snapshot的编译流程:
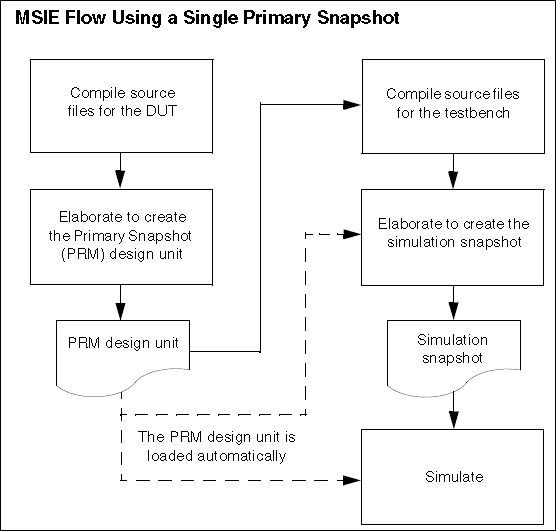
将DUT,编译成primary snapshot,TB载入primary snapshot后,和tb一起进行编译,得到仿真的snapshot,再去仿真。
下图是多个primary snapshot的编译流程:
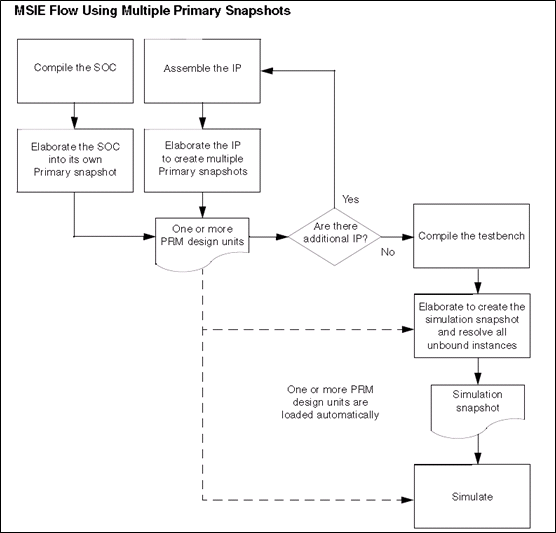
将SOC编译成primary snapshot,将IP编译成primary snapshot,将2个primary snapshot,和tb一起编译,得到最终的仿真snapshot,再进行仿真。
二、实现方法
一般情况下,我们是将DUT和TB进行分开编译,以实现增量编译。对于验证人员来说,DUT是不会变化的,因此我们可以将DUT,编译成primary snapshot,TB部分载入DUT的primary snapshot,和自己的TB代码一起编译,成最终的incremental snapshot,去仿真。这样,当环境修改之后,不需要重新编译RTL,这样,就节省了编译时间。特别是RTL的设计规模很大之后,这节约的时间,就更明显了。
三、测试
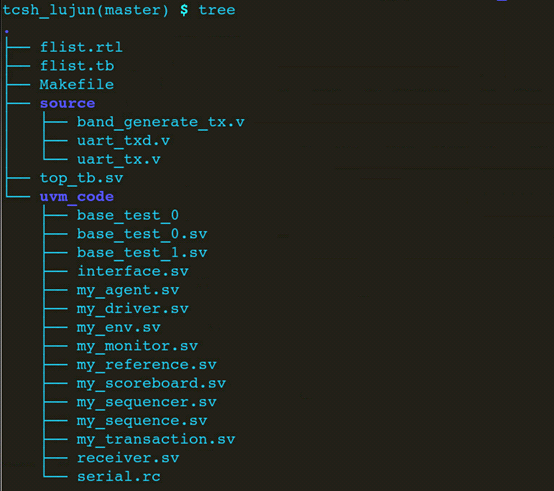
测试环境,组织结构如下:
- flist.rtl : 编译rtl的flist
- flist.tb : 编译tb的flist
- Makefile
- top_tb.sv : testbench顶层
- source: 存放rtl code的目录
- uvm_code:存放tb code的目录
1、makefile解析
Makefile内容如下:
tc:= base_test_0
irun_prim:
irun -sv -64bit -f flist.rtl -mkprimsnap -top uart_tx -l irun_rtl.log
irun_inca:
irun -c -sv -64bit -f flist.tb -uvm -uvmhome CDNS-1.2 -primtop uart_tx -l irun_tb.log
irun_run:
irun -R +UVM_TESTNAME=$(tc) -l irun_run.log
clean:
rm -rf INCA_libs
rm -f *.log
|
对于 irun_prim 目标,根据RTL代码生成primary snapshot。
- -sv: 启动sv编译
- -64bit: 启动64位的irun
- -f flist.rtl : 指定编译RTL的flist
- -mkprimsnap: 生成primary snapshot
- -top: 指定RTL的顶层
- -l: 指定log文件
对于 irun_inca 目标,载入RTL编译得到的primary snapshot,根据TB代码生成incremental snapshot,
- -c: 只编译,不仿真
- -f flist.tb: 指定编译TB的flist
- -uvm: 启动uvm编译
- -uvmhome CDNS-1.2: 指定uvm的home目录为irun工具目录下的UVM-1.2目录
- -primtop uart_tx: 指定需要载入primary snapshot的顶层。
对于 irun_run 目标,仿真。
- -R : 不编译,直接仿真
- +UVM_TESTNAME: uvm指定testcase的选项
2、第一次执行
make irun_prim; 生成primary snapshot
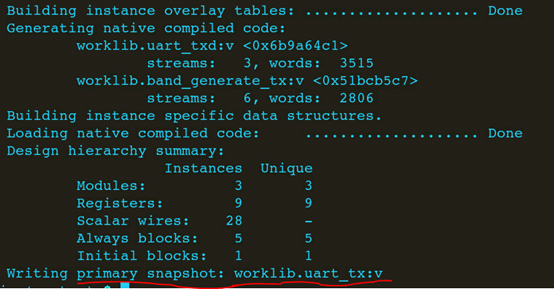
make irun_inca: 载入primary snapshot,和tb一起编译生成incremantal snapshot。
载入primary snapshot:
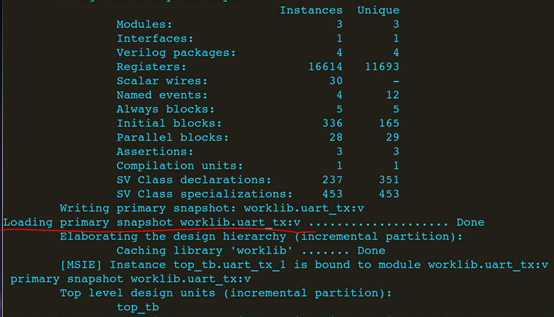
生成incremantal snapshot。
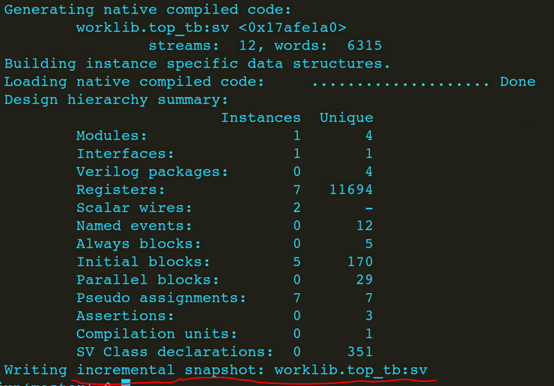
3、第二次执行
此时,修改top_tb.sv的代码,增加一行打印。
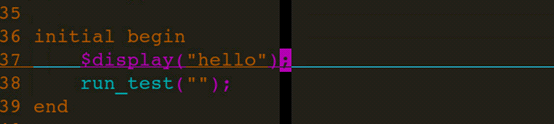
因为RTL没有编译,因此可以跳过编译RTL,直接make irun_inca。
载入 primary snapshot,跳过了代码生成。

生成incremantal snapshot。
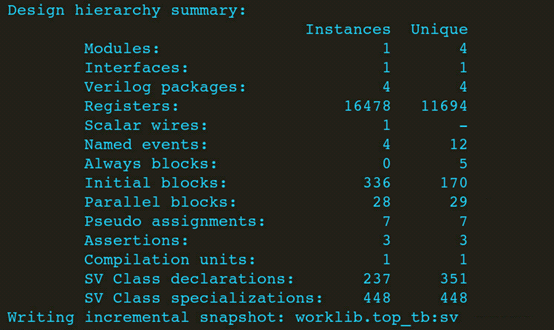
仿真,打印出hello。
测试的RTL,规模比较小,感受不到增量编译的好处,但是当RTL的规模一旦变得很大,编译RTL就要花费数十分钟,此时,就可以体会到增量编译的好处了。
在服务器,测试我们的环境,使用增量编译后,将编译时间,从5分钟,缩减到了20秒。