本系列导航:
- eBPF 概述:第 1 部分:介绍
- eBPF 概述:第 2 部分:机器和字节码
- eBPF 概述:第 3 部分:软件开发生态
- eBPF概述:第 4 部分:在嵌入式系统运行
- eBPF概述:第 5 部分:追踪用户进程
原文地址:https://www.collabora.com/news-and-blog/blog/2019/04/05/an-ebpf-overview-part-1-introduction/
首发地址:https://ebpf.top/post/ebpf-overview-part-1/
发布时间: 2019-04-05
作者:Adrian Ratiu
翻译: 狄卫华
1. 前言
有兴趣了解更多关于 eBPF 技术的底层细节?那么请继续移步,我们将深入研究 eBPF 的底层细节,从其虚拟机机制和工具,到在远程资源受限的嵌入式设备上运行跟踪。
注意:本系列博客文章将集中在 eBPF 技术,因此对于我们来讲,文中 BPF 和 eBPF 等同,可相互使用。BPF 名字/缩写已经没有太大的意义,因为这个项目的发展远远超出了它最初的范围。BPF 和 eBPF 在该系列中会交替使用。
- 第 1 部分和第 2 部分 为新人或那些希望通过深入了解 eBPF 技术栈的底层技术来进一步了解 eBPF 技术的人提供了深入介绍。
- 第 3 部分是对用户空间工具的概述,旨在提高生产力,建立在第 1 部分和第 2 部分中介绍的底层虚拟机机制之上。
- 第 4 部分侧重于在资源有限的嵌入式系统上运行 eBPF 程序,在嵌入式系统中完整的工具链技术栈(BCC/LLVM/python 等)是不可行的。我们将使用占用资源较小的嵌入式工具在 32 位 ARM 上交叉编译和运行 eBPF 程序。只对该部分感兴趣的读者可选择跳过其他部分。
- 第 5 部分是关于用户空间追踪。到目前为止,我们的努力都集中在内核追踪上,所以是时候我们关注一下用户进程了。
如有疑问时,可使用该流程图:
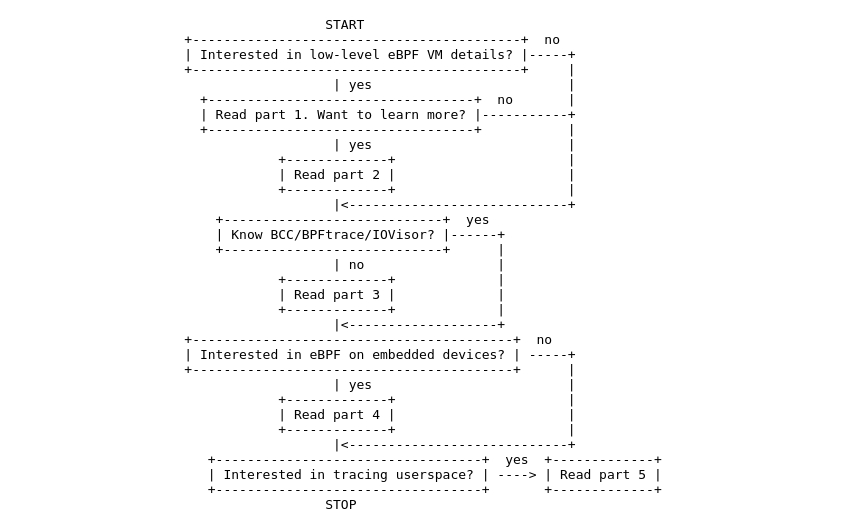
2. eBPF 是什么?
eBPF 是一个基于寄存器的虚拟机,使用自定义的 64 位 RISC 指令集,能够在 Linux 内核内运行即时本地编译的 "BPF 程序",并能访问内核功能和内存的一个子集。这是一个完整的虚拟机实现,不要与基于内核的虚拟机(KVM)相混淆,后者是一个模块,目的是使 Linux 能够作为其他虚拟机的管理程序。eBPF 也是主线内核的一部分,所以它不像其他框架那样需要任何第三方模块(LTTng 或 SystemTap),而且几乎所有的 Linux 发行版都默认启用。熟悉 DTrace 的读者可能会发现 DTrace/BPFtrace 对比非常有用。
在内核内运行一个完整的虚拟机主要是考虑便利和安全。虽然 eBPF 程序所做的操作都可以通过正常的内核模块来处理,但直接的内核编程是一件非常危险的事情 - 这可能会导致系统锁定、内存损坏和进程崩溃,从而导致安全漏洞和其他意外的效果,特别是在生产设备上(eBPF 经常被用来检查生产中的系统),所以通过一个安全的虚拟机运行本地 JIT 编译的快速内核代码对于安全监控和沙盒、网络过滤、程序跟踪、性能分析和调试都是非常有价值的。部分简单的样例可以在这篇优秀的 eBPF 参考中找到。
基于设计,eBPF 虚拟机和其程序有意地设计为不是图灵完备的:即不允许有循环(正在进行的工作是支持有界循环【译者注:已经支持有界循环,#pragma unroll 指令】),所以每个 eBPF 程序都需要保证完成而不会被挂起、所有的内存访问都是有界和类型检查的(包括寄存器,一个 MOV 指令可以改变一个寄存器的类型)、不能包含空解引用、一个程序必须最多拥有 BPF_MAXINSNS 指令(默认 4096)、"主"函数需要一个参数(context)等等。当 eBPF 程序被加载到内核中,其指令被验证模块解析为有向环状图,上述的限制使得正确性可以得到简单而快速的验证。
译者注: BPF_MAXINSNS 这个限制已经被放宽至 100 万条指令(BPF_COMPLEXITY_LIMIT_INSNS),但是非特权执行的 BPF 程序这个限制仍然会保留。
历史上,eBPF (cBPF) 虚拟机只在内核中可用,用于过滤网络数据包,与用户空间程序没有交互,因此被称为 "伯克利数据包过滤器"(译者注:早期的 BPF 实现被称为经典 cBPF)。从内核 v3.18(2014 年)开始,该虚拟机也通过 bpf() syscall 和uapi/linux/bpf.h 暴露在用户空间,这导致其指令集在当时被冻结,成为公共 ABI,尽管后来仍然可以(并且已经)添加新指令。
因为内核内的 eBPF 实现是根据 GPLv2 授权的,它不能轻易地被非 GPL 用户重新分发,所以也有一个替代的 Apache 授权的用户空间 eBPF 虚拟机实现,称为 "uBPF"。撇开法律条文不谈,基于用户空间的实现对于追踪那些需要避免内核-用户空间上下文切换成本的性能关键型应用很有用。
3. eBPF 是怎么工作的?
eBPF 程序在事件触发时由内核运行,所以可以被看作是一种函数挂钩或事件驱动的编程形式。从用户空间运行按需 eBPF 程序的价值较小,因为所有的按需用户调用已经通过正常的非 VM 内核 API 调用("syscalls")来处理,这里 VM 字节码带来的价值很小。事件可由 kprobes/uprobes、tracepoints、dtrace probes、socket 等产生。这允许在内核和用户进程的指令中钩住(hook)和检查任何函数的内存、拦截文件操作、检查特定的网络数据包等等。一个比较好的参考是 Linux 内核版本对应的 BPF 功能。
如前所述,事件触发了附加的 eBPF 程序的执行,后续可以将信息保存至 map 和环形缓冲区(ringbuffer)或调用一些特定 API 定义的内核函数的子集。一个 eBPF 程序可以链接到多个事件,不同的 eBPF 程序也可以访问相同的 map 以共享数据。一个被称为 "program array" 的特殊读/写 map 存储了对通过 bpf() 系统调用加载的其他 eBPF 程序的引用,在该 map 中成功的查找则会触发一个跳转,而且并不返回到原来的 eBPF 程序。这种 eBPF 嵌套也有限制,以避免无限的递归循环。
运行 eBPF 程序的步骤:
- 用户空间将字节码和程序类型一起发送到内核,程序类型决定了可以访问的内核区域(译者注:主要是 BPF 辅助函数的各种子集)。
- 内核在字节码上运行验证器,以确保程序可以安全运行(kernel/bpf/verifier.c)。
- 内核将字节码编译为本地代码,并将其插入(或附加到)指定的代码位置。(译者注:如果启用了 JIT 功能,字节码编译为本地代码)。
- 插入的代码将数据写入环形缓冲区或通用键值 map。
- 用户空间从共享 map 或环形缓冲区中读取结果值。
map 和环形缓冲区结构是由内核管理的(就像管道和 FIFO 一样),独立于挂载的 eBPF 或访问它们的用户程序。对 map 和环形缓冲区结构的访问是异步的,通过文件描述符和引用计数实现,可确保只要有至少一个程序还在访问,结构就能够存在。加载的 JIT 后代码通常在加载其的用户进程终止时被删除,尽管在某些情况下,它仍然可以在加载进程的生命期之后继续存在。
为了方便编写 eBPF 程序和避免进行原始的 bpf()系统调用,内核提供了方便的 libbpf 库,包含系统调用函数包装器,如bpf_load_program 和结构定义(如 bpf_map),在 LGPL 2.1 和 BSD 2-Clause 下双重许可,可以静态链接或作为 DSO。内核代码也提供了一些使用 libbpf 简洁的例子,位于目录 samples/bpf/ 中。
4. 样例学习
内核开发者非常可怜,因为内核是一个独立的项目,因而没有用户空间诸如 Glibc、LLVM、JavaScript 和 WebAssembly 诸如此类的好东西! - 这就是为什么内核中 eBPF 例子中会包含原始字节码或通过 libbpf 加载预组装的字节码文件。我们可以在 sock_example.c 中看到这一点,这是一个简单的用户空间程序,使用 eBPF 来计算环回接口上统计接收到 TCP、UDP 和 ICMP 协议包的数量。
我们跳过微不足道的的 main 和 open_raw_sock 函数,而专注于神奇的代码 test_sock。
static int test_sock(void)
{
int sock = -1, map_fd, prog_fd, i, key;
long long value = 0, tcp_cnt, udp_cnt, icmp_cnt;
map_fd = bpf_create_map(BPF_MAP_TYPE_ARRAY, sizeof(key), sizeof(value), 256, 0);
if (map_fd < 0) {printf("failed to create map'%s'
", strerror(errno));
goto cleanup;
}
struct bpf_insn prog[] = {BPF_MOV64_REG(BPF_REG_6, BPF_REG_1),
BPF_LD_ABS(BPF_B, ETH_HLEN + offsetof(struct iphdr, protocol) /* R0 = ip->proto */),
BPF_STX_MEM(BPF_W, BPF_REG_10, BPF_REG_0, -4), /* *(u32 *)(fp - 4) = r0 */
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -4), /* r2 = fp - 4 */
BPF_LD_MAP_FD(BPF_REG_1, map_fd),
BPF_RAW_INSN(BPF_JMP | BPF_CALL, 0, 0, 0, BPF_FUNC_map_lookup_elem),
BPF_JMP_IMM(BPF_JEQ, BPF_REG_0, 0, 2),
BPF_MOV64_IMM(BPF_REG_1, 1), /* r1 = 1 */
BPF_RAW_INSN(BPF_STX | BPF_XADD | BPF_DW, BPF_REG_0, BPF_REG_1, 0, 0), /* xadd r0 += r1 */
BPF_MOV64_IMM(BPF_REG_0, 0), /* r0 = 0 */
BPF_EXIT_INSN(),};
size_t insns_cnt = sizeof(prog) / sizeof(struct bpf_insn);
prog_fd = bpf_load_program(BPF_PROG_TYPE_SOCKET_FILTER, prog, insns_cnt,
"GPL", 0, bpf_log_buf, BPF_LOG_BUF_SIZE);
if (prog_fd < 0) {printf("failed to load prog'%s'
", strerror(errno));
goto cleanup;
}
sock = open_raw_sock("lo");
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd)) < 0) {printf("setsockopt %s
", strerror(errno));
goto cleanup;
}
首先,通过 libbpf API 创建一个 BPF map,该行为就像一个最大 256 个元素的固定大小的数组。按 IPROTO_* 定义的键索引网络协议(2 字节的 word),值代表各自的数据包计数(4 字节大小)。除了数组,eBPF 映射还实现了其他数据结构类型,如栈或队列。
接下来,eBPF 的字节码指令数组使用方便的内核宏进行定义。在这里,我们不会讨论字节码的细节(这将在第 2 部分描述机器后进行)。更高的层次上,字节码从数据包缓冲区中读取协议字,在 map 中查找,并增加特定的数据包计数。
然后 BPF 字节码被加载到内核中,并通过 libbpf 的 bpf_load_program 返回 fd 引用来验证正确/安全。调用指定了 eBPF 是什么程序类型,这决定了它可以访问哪些内核子集。因为样例是一个 SOCKET_FILTER 类型,因此提供了一个指向当前网络包的参数。最后,eBPF 的字节码通过套接字层被附加到一个特定的原始套接字上,之后在原始套接字上接受到的每一个数据包运行 eBPF 字节码,无论协议如何。
剩余的工作就是让用户进程开始轮询共享 map 的数据。
for (i = 0; i < 10; i++) {
key = IPPROTO_TCP;
assert(bpf_map_lookup_elem(map_fd, &key, &tcp_cnt) == 0);
key = IPPROTO_UDP;
assert(bpf_map_lookup_elem(map_fd, &key, &udp_cnt) == 0);
key = IPPROTO_ICMP;
assert(bpf_map_lookup_elem(map_fd, &key, &icmp_cnt) == 0);
printf("TCP %lld UDP %lld ICMP %lld packets
",
tcp_cnt, udp_cnt, icmp_cnt);
sleep(1);
}
}
5. 总结
第 1 部分介绍了 eBPF 的基础知识,我们通过如何加载字节码和与 eBPF 虚拟机通信的例子进行了讲述。由于篇幅限制,编译和运行例子作为留给读者的练习。我们也有意不去分析具体的 eBPF 字节码指令,因为这将是第 2 部分的重点。在我们研究的例子中,用户空间通过 libbpf 直接用 C 语言从内核虚拟机中读取 eBPF map 值(使用 10 次 1 秒的睡眠!),这很笨重,而且容易出错,而且很快就会变得很复杂,所以在第 3 部分,我们将研究更高级别的工具,通过脚本或特定领域的语言自动与虚拟机交互。