opcode(operate code)是计算机指令中的一部分,用于指定要执行的操作,指令的格式和规范由处理器的指定规范指定
opcode是一种php脚本编译后的中间语言,就像java的ByteCode,或者.NET的MSL
为什么要使用opcode缓存
opcode cache的目的是避免重复编译,减少CPU和内存开销的。如果动态内容的性能瓶颈不在于CPU和内容,而在于IO操作,比如数据库查询带来的IO开销,这个时候opcode cache的性能提升是非常有局限的。无论如何既然opcode cache 可以降低cpu和内存的开销,这当然是好事了
目前PHP中常见的opcode cahce模块如下
-
APC
-
Optimizer+(目前已开源并与php5.5+集成了opcache)
-
xcache
-
eAccelerator
Opcode原理
例如有如下一段代码
<?php
echo 'Hello World';$a = 1 + 1;echo $a;?>php执行这段代码会经过如下4个步骤(准确的说,通过php的语言引擎Zend)
Scanning 扫描 (Lexing)将php代码转化为语言片段(Tokens)
Parsing,解析 将Tokens转化为简单而有意义的表达式
Complilation,编译 将表达式编译成Opcode
Execution, 执行 顺序执行Opcode,每次一条,从而实现php脚本的功
如下图

Lexing阶段
Lex 就是一个词法分析的依据表。Zend引擎会会对输入的php代码进行词法分析(切确的说是: Zend/zend_language_scanner.c会根据Zend/zend_language_scanner.l(Lex文件) ),从而得到一个一个的词,php中提供了一个函数:token_get_all可以将一段php代码解析成tokens
如果用这个函数分析上面的示例代码,结果如下:
rray
( [0] => Array ( [0] => 374 [1] => <?php [2] => 1 ) [1] => Array ( [0] => 377 [1] => [2] => 1 ) [2] => Array ( [0] => 317 [1] => echo [2] => 1 ) [3] => Array ( [0] => 377 [1] => [2] => 1 ) [4] => Array ( [0] => 316 [1] => "Hello World" [2] => 1 ) [5] => ; [6] => Array ( [0] => 310 [1] => $a [2] => 1 ) [7] => Array ( [0] => 377 [1] => [2] => 1 ) [8] => = [9] => Array ( [0] => 377 [1] => [2] => 1 ) [10] => Array ( [0] => 306 [1] => 1 [2] => 1 ) [11] => Array ( [0] => 377 [1] => [2] => 1 ) [12] => + [13] => Array ( [0] => 377 [1] => [2] => 1 ) [14] => Array ( [0] => 306 [1] => 1 [2] => 1 ) [15] => ; [16] => Array ( [0] => 377 [1] => [2] => 1 ) [17] => Array ( [0] => 317 [1] => echo [2] => 1 ) [18] => Array ( [0] => 377 [1] => [2] => 1 ) [19] => Array ( [0] => 310 [1] => $a [2] => 1 ) [20] => ; [21] => Array ( [0] => 376 [1] => ?> [2] => 1 ))分析这个返回结果我们可以发现,源码中的字符串,字符,空格都会原样返回。每个源代码的字符都会出现在相应的顺序处。而其他的例如标签,操作符,语句 都被转化成一个包含;两部分的array:Token ID(也就是在Zend内部的该Token的对应码,比如T_ECHO,T_STRING)和 源码中原来的内容
Parsing阶段
Parsing阶段首先会丢弃Tokens array中的多余空格,然后将剩余的Tokens转换成一个一个简单的表达式
echo a contanst string
add two numbers togetherstore the result of the prior expression to a variableecho a variableComplilation阶段
Complilation阶段会把Tokens编译成一个个op_array,每个op_array包含如下5个部分
|
1
2
3
4
5
|
Opcode数字的标示,指明了每个op_array的操作类型,比如add,echo结果 存放Opcode的结果操作数1 给Opcode的操作数操作数2扩展值 1个整形用来区别被重载的操作符 |
比如我的php代码会被Parsing成:
|
1
2
3
4
|
ZEND_ECHO 'Hello World'ZEND_ADD ~0 1 1ZEND_ASSIGN !0 ~0ZEND_ECHI ~0 |
在上面的代码我们并没有看到 $a,去哪里了?
这个就要介绍操作数了,每个操作数都是由以下两个部分组成:
-
op_type :为IS_CONST,IS_TMP_VAR,IS_VAR,IS_UNUESED or IS_CV
-
u 一个联合体,根据op_type不同 分别用不同的类型保存这个操作数的值(const)或者左值(var)
而对于var来说,每个var也不一样
IS_TMP_VAR 顾名思义就是这是一个临时变量,保存一些op_array 的结果,以便接下来的op_array 使用,这种的操作数u保存着一个指向变量表的一个句柄(整数),这个操作数一般用~ 开头 ,比如 ~0 表示 变量表中0号的未知的临时变量
IS_VAR 这是我们一般意义上的变量,他们以$开头表示
IS_CV 表示ZE2.1/PHP5.1以后的编译器使用的一种cache机制,这种变量保存着被应用的变量地址,当一个变量第一次被应用的时候 ,就会被CV起来,以后对这个变量的引用就不需要再去查找active符号表了,CV变量已!开头表示
这么开来 我的$a 被优化成了!0了
Opcode Cache原理
通过上面的介绍,我们了解了opcode,关于opcode cache的原理图大致如下
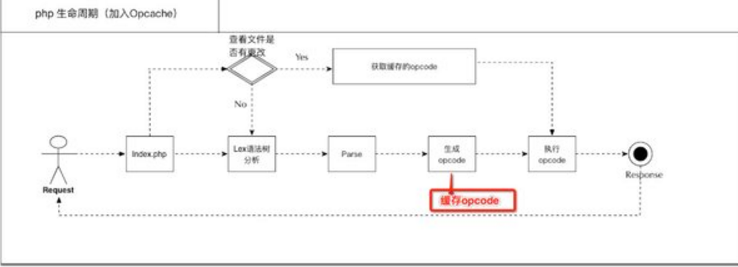
我们可以看到除了 Lexing,Parsing,Complilation,Execution阶段 还多了一个阶段:检测文件是否有更新
如果没有更新直接获取缓存的opcode,直接进入Execution阶段然后返回结果
如果更新了就按照原来流程(加入一个环节:图中红色部分 缓存opcode)